
Since its appearance, AWS provided a variety of database services to help users manage their data according to their needs. In AWS, you can run OLAP DBs as well as OLTP DBs .
The paper provides a further explanation of the whitepaper entitled “Automated Archival for Amazon Redshift” published In July 2021.It will shed the light on AWS Redshift service and its specifications especially the automated archival.
OLAP databases VS OLTP databases
Those two types of databases each rely on a different processing system. According to the type of information that you want to extract from your database, you generally select one of those two categories. In fact:
• OLAP( OnLine Analytical Processing) : Used for business intelligence and any other operation that require complex analytical calculations .The data is mostly coming from a data warehouse. This process is ideal for reporting and analyzing historical data. Many businesses rely on this type of database to have a clear visualization about their budgeting, sales forecasting and to track the success rate of released products.
• OLTP(OnLine Transactional Processing) : Used for a high volume of simple transactions and short queries. It relies mainly on four operations that can be performed on the databases (CRUD: CREATE, READ, UPDATE, DELETE). Businesses rely on this category to get detailed and current data from organized tables.
What is a Data Warehouse?
A Data Warehouse is a concept that refers to any aggregation of considerable amounts of data from different sources for the sake of analytics. Those resources could be internal (in your own network like marketing) or external (like customer categories, system partners,etc) .It helps to centralize historical data into one consistent repository of information. The Data warehouse concept aims to run analytics on hundreds of gigabytes to petabytes of data.
OLAP usage in Data Warehouse
OLAP is a system dedicated to perform multi-dimensional analysis on considerable volumes of data. It is ideal for querying and analyzing data warehouses. OLAP undergoes complex queries on data from different perspectives.
What AWS Redshift?
Amazon Redshift is a data warehouse service provided by AWS. It is fully managed and it can analyze up to a petabyte of data or more. It enables AWS users to run complex queries that involve aggregation on historical data rather than real-time data. Those analytics are crucial for business reporting and for visualization purposes . this helps managers to have clear insights into the evolution of the business .
Automated Archival for Amazon Redshift
In this paragraph, we discuss the architecture illustrated in Figure (a). This architecture automates the periodic data archival process for an Amazon Redshift database. We will go through each step and explain the ambiguous ones.
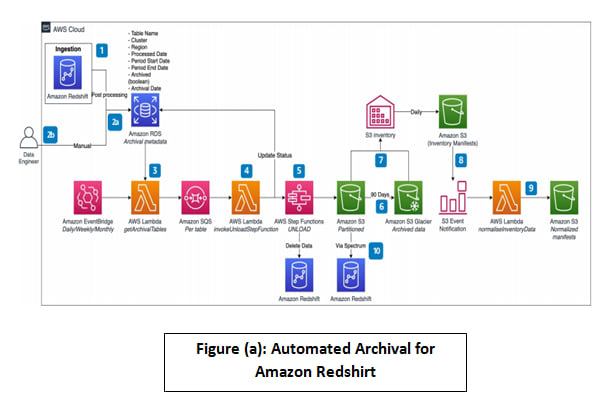
1) Data is ingested into the Amazon Redshift cluster at various frequencies:
The ingestion of data is literally the transportation of data from assorted sources like Simple Storage Service S3,Copy command (EMR, DynamoDB), database migration service or data pipeline to the data warehouse like Amazon Redshift cluster. Each given dataset has its own ‘Frequency Of Ingestion’ which defines how often we ingest it.
2.a) After every ingestion load, the process creates a queue of metadata about tables populated into Amazon Redshift tables in Amazon RDS:
In order to have a clear visualization of the data stored in the data warehouse, the process creates a queue of metadata for every ingested data and store it in an Amazon RDS (Relational Database Service).This archived metadata contains various information about the tables populated into Amazon Redshift such as Table Name, Cluster, Region , Processed Date, Archival Date, etc.
2.b) Data Engineers may also create the archival queue manually, if needed.
3) Using Amazon EventBridge, an AWS Lambda function is triggered periodically to read the queue from the RDS table and create an Amazon SQS message for every period due for archival. The user may choose a single SQS queue or an SQS queue per schema based on the volume of tables.
Amazon EventBridge is a serverless event bus to build event-driven applications. Here EventBridge is used to initiate an AWS Lambda function Daily,Weekly or Monthly to get archival tables from the Amazon RDS mentioned in step(1)
4) A proxy Lambda function de-queues the Amazon SQS messages and for every message invokes AWS Step Functions.
The proxy Lambda function links each Amazon SQS message to the corresponding AWS Step Functions.
AWS Step Functions is a low-code visual workflow service used to orchestrate AWS services. It manages failures, retries, parallelization, service integrations, and observability .
5) AWS Step Functions unloads the data from the Amazon Redshift cluster into an Amazon S3 bucket for the given table and period.
6) Amazon S3 Lifecycle configuration moves data in buckets from S3 Standard storage class to S3 Glacier storage class after 90 days.
The definition of the S3 lifecycle relies on the S3 retention policy. The transition action happens every 90 days to Amazon S3 Glacier (which is the minimum storage duration charge of S3 Glacier).S3 Glacier is a deep , long-term and durable archive storage that will conserve the data until deleted, while S3 is not a long term storage device.
7) Amazon S3 inventory tool generates manifest files from the Amazon S3 bucket dedicated for cold data on daily basis and stores them in an S3 bucket for manifest files.
S3 inventory is a tool provided by AWS to help manage the simple storage service. In this context, S3 inventory lies between the standard S3 storage and the S3 Glacier. It keeps track of the cool data archived in S3 Glacier. It generates manifest files that list all the file inventory lists that are stored in the S3 Glacier every 90 days when the transition takes action.
8) Every time an inventory manifest file is created in a manifest S3 bucket, an AWS Lambda function is triggered through an Amazon S3 Event Notification.
The manifest files created by the S3 inventory tool are stored in Amazon S3 . The acquisition of the data on the S3 bucket produces an S3 event notification which will initiate an AWS Lambda function.
9) A Lambda function normalizes the manifest file for easy consumption in the event of restore.
The triggered Lambda Function starts to normalize the inventory data.
10) The data stored in the S3 bucket used for cold data can be queried using Amazon Redshift Spectrum.
Amazon Redshift Spectrum will be used to query data directly from files on the Amazon S3 where the normalized manifests are stored.
Reference :
Automated Archival for Amazon Redshift Whitepaper published On July ,2021 : https://d1.awsstatic.com/architecture-diagrams/ArchitectureDiagrams/automated-archival-for-amazon-redshift-ra.pdf?did=wp_card&trk=wp_card

Top comments (0)