
This is the last part of my FaaS like Pro series, where I discuss and showcase some less common ways to invoke your serverless functions with AWS Lambda.
You can find [Part 1] here — covering Amazon Cognito User Pools, AWS Config, Amazon Kinesis Data Firehose, and AWS CloudFormation.
And [Part 2] here — covering AWS IoT Button, Amazon Lex, Amazon CloudWatch Logs, and Amazon Aurora.
In the third part I will describe four more:
- AWS CodeDeploy — pre & post deployment hooks
- AWS CodePipeline — custom pipeline actions
- Amazon Pinpont — custom segments & channels
- AWS ALB (Application Load Balancer) — HTTP target
9. AWS CodeDeploy (pre/post-deployment hooks)
CodeDeploy is part of the AWS Code Suite and allows you automate software deployments to Amazon EC2, AWS Fargate, AWS Lambda, and even on-premises environments.
Not only it enables features such as safe deployments for serverless functions, but it also integrates with Lambda to implement custom hooks. This means you can inject custom logic at different steps of a deployment in order to add validation, 3rd-party integrations, integrations tests, etc. Each hook runs only one per deployment and can potentially trigger a rollback.
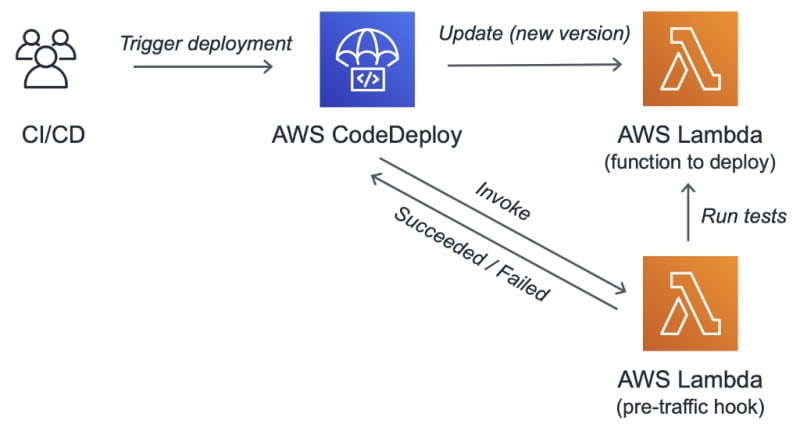
You can configure different lifecycle event hooks, depending on the compute platform (AWS Lambda, Amazon ECS, Amazon EC2 or on-premises).
AWS Lambda
- BeforeAllowTraffic — runs before traffic is shifted to the deployed Lambda function
- AfterAllowTraffic — runs after all traffic has been shifted
Amazon ECS & Amazon EC2/on-premises
See the full documentation here.
Amazon ECS and EC2 have a more complex deployment lifecycle, while Lambda follows a simple flow: Start > BeforeAllowTraffic > AllowTraffic > AfterAllowTraffic > End. In this flow, you can inject your custom logic before traffic is shifted to the new version of your Lambda function and after all traffic is shifted.
For example, we could run some integration tests in the BeforeAllowTraffic hook. And we could implement a 3rd-party integration (JIRA, Slack, email, etc.) in the AfterAllowTraffic hook.
Let’s have a look at a sample implementation of a Lambda hook for CodeDeploy:
The code snippet above doesn’t do much, but it shows you the overall hook structure:
- It receives a DeploymentId and LifecycleEventHookExecutionId that you’ll use to invoke CodeDeploy’s PutLifecycleEventHookExecutionStatus API
- The execution status can be either Succeeded or Failed
- You can easily provide an environment variable to the hook function so that it knows which functions we are deploying and what’s its ARN
I’d recommend defining the hook functions in the same CloudFormation (or SAM) template of the function you’re deploying. This way it’s very easy to define fine-grained permissions and environment variables.
For example, let’s define an AWS SAM template with a simple Lambda function and its corresponding Lambda hook:
The template above is defining two functions:
- myFunctionToBeDeployed is our target function, the one we’ll be deploying with AWS CodeDeploy
- preTrafficHook is our hook, invoked before traffic is shifted to myFunctionToBeDeployed during the deployment
I’ve configured two special properties on myFunctionToBeDeployed called DeploymentPreference and AutoPublishAlias . These properties allows us to specify which deployment type we want (linear, canary, etc.), which hooks will be invoked, and which alias will be used to shifting the traffic in a weighted fashion.
A few relevant details about the pre-traffic hook definition:
- I am defining an environment variable named NewVersion which will contain the ARN of the newly deployed function, so that we could invoke it and run a some tests
- preTrafficHook needs IAM permissions to invoke the codedeploy:PutLifecycleEventHookExecutionStatus API and I’m providing fine-grained permissions by referencing the deployment group via ${ServerlessDeploymentApplication}
- since we want to run some tests on the new version of myFunctionToBeDeployed, our hook will need IAM permissions to invoke thelambda:invokeFunction API, and I’m providing fine-grained permissions by referencing myFunctionToBeDeployed.Version
In a real-world scenario, you may want to set up a proper timeout based on which tests you’re planning to run and how long you expect them to take.
In even more complex scenarios, you may event execute an AWS Step Functions state machine that will run multiple tasks in parallel before reporting the hook execution status back to CodeDeploy.
Last but not least, don’t forget that you can implement a very similar behaviour for non-serverless deployments involving Amazon ECS or EC2. In this case, you’ll have many more hooks available such as BeforeInstall, AfterInstall, ApplicationStop, DownloadBundle, ApplicationStart, ValidateService, etc (full documentation here).
10. AWS CodePipeline (custom action)
CodePipeline is part of the AWS Code Suite and allows you to design and automate release pipelines (CI/CD). It integrates with the other Code Suite services such as CodeCommit, CodeBuild, and CodeDeploy, as well as popular 3rd-party services such as GitHub, CloudBees, Jenkins CI, TeamCity, BlazeMeter, Ghost Inspector, StormRunner Load, Runscope, and XebiaLabs.

In situations when built-in integrations don’t suit your needs, you can let CodePipeline integrate with your own Lambda functions as a pipeline stage. For example, you can use a Lambda function to verify if a website’s been deployed successfully, to create and delete resources on-demand at different stages of the pipeline, to back up resources before deployments, to swag CNAME values during a blue/green deployment, and so on.

Let’s have a look at a sample implementation of a Lambda stage for CodePipeline:
The function will receive three main inputs in the CodePipeline.job input:
- id — the JobID required to report success or failure via API
- data.actionConfiguration.configuration.UserParameters — the stage dynamic configuration; you can think of this as an environment variable that depends on the pipeline stage, so you could reuse the same function for dev, test, and prod pipelines
- context.invokeid — the invocation ID related to this pipeline execution, useful for tracing and debugging in case of failure
In the simple code snippet above I am doing the following:
- Verify that the given URL is valid
- Fetch the URL via HTTP(S)
- Report success via the CodePipeline putJobSuccessResult API if the HTTP status is 200
- Report failure via the CodePipeline putJobFailureResult API in case of errors — using different error messages and contextual information
Of course, we could extend and improve the validation step, as well as the URL verification. Receiving a 200 status is a very minimal way to verify that our website was deployed successful. Here we could add automated browser testing and any other custom logic.
It’s also worth remembering that you can implement this logic in any programming language supported by Lambda (or not). Here I’ve used Node.js but the overall structure wouldn’t change much in Python, Go, C#, Ruby, Java, PHP, etc.
Now, let me show you how we can integrate all of this into a CloudFormation template (using AWS SAM as usual):
In the template above I’ve defined three resources:
- An AWS::Serverless::Function to implement our custom pipeline stage; note that it will require IAM permissions to invoke the two CodePipeline API’s
- An AWS::CodePipeline::Pipeline where we’d normally add all our pipeline stages and actions; plus, I’m adding an action of type Invoke with provider Lambda that will invoke the myPipelineFunction function
- An AWS::Lambda::Permission that grants CodePipeline permissions to invoke the Lambda function
One more thing to note: in this template I’m not including the IAM role for CodePipeline for brevity.
You can find more details and step-by-step instructions in the official documentation here.
11. Amazon Pinpoint (custom segments & channels)
Amazon Pinpoint is a managed service that allows you to send multi-channel personalized communications to your own customers.
Pinpoint natively supports many channels including email, SMS (in over 200 countries), voice (audio messages), and push notifications (Apple Push Notification service, Amazon Device Messaging, Firebase Cloud Messaging, and Baidu Cloud Push).
As you’d expect, Pinpoint allows you to define users/endpoints and messaging campaigns to communicate with your customers.
And here’s where it nicely integrates with AWS Lambda for two interesting use cases:
- Custom segments — it allows you to dynamically modify the campaign’s segment at delivery-time , which means you can implement a Lambda function to filter out some of the users/endpoints to engage a more narrowly defined subset of users, or even to enrich users’ data with custom attributes (maybe coming from external systems)
- Custom channels — it allows you to integrate unsupported channels such as instant messaging services or web notifications, so you can implement a Lambda function that will take care of the message delivery outside of Amazon Pinpoint
Let’s dive into both use cases!
Note: both use cases are still in beta and some implementation details are still subject to change
11.A — How to define Custom Segments
We can connect a Lambda function to our Pinpoint Campaign and dynamically modify, reduce, or enrich our segment’s endpoints.

Our Lambda function will receive a structured event:
The important section of the input event is the set of Endpoints. The expected output of our function is a new set of endpoints with the same structure. This new set might contain fewer endpoints and/or new attributes as well. Also note that our function will receive at most 50 endpoints in a batch fashion. If you segment contains more than 50 endpoints, the function will be involved multiple times.
For example, let’s implement a custom segment that will include only the APNS channel (Apple) and generate a new custom attribute named CreditScore:
The code snippet above is iterating over the given endpoints and dynamically modify the set before returning it back to Amazon Pinpoint for delivery.
For each endpoint, we are excluding it from the set if it’s not APNS (just as an example), then we are generating a new CreditScore attribute only for active endpoints.
Let’s now define the CloudFormation template for our Pinpoint app:
The important section of the template above is the CampaignHook attribute of the AWS::Pinpoint::Campaign resource. We are providing the Lambda function name and configuring it with Mode: FILTER. As we’ll see in the next section of this article, we are going to use Mode: DELIVERY to implement custom channels.
In case we had multiple campaigns that required the same custom segment, we could centralize the CampaignHook definition into an AWS::Pinpoint:ApplicationSettings resource:
This way, all the campaigns in our Pinpoint application will inherit the same Lambda hook.
You can find the full documentation here.
11.B — How to define Custom Channels
We can connect a Lambda function to our Pinpoint Campaign to integrate unsupported channels. For example, Facebook Messenger or even your own website backend to show in-browser notifications.
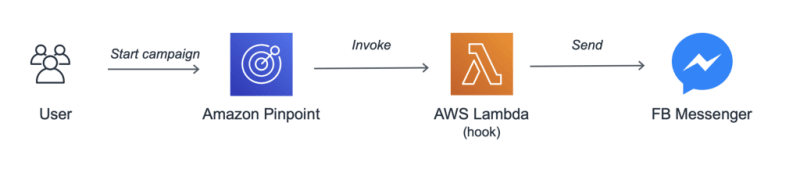
To define a custom channel we can use the same mechanism described above for custom segments, but using Mode: DELIVERY in our CampaignHook configuration. The biggest difference is that Pinpoint won’t deliver messages itself, as our Lambda hook will take care of that.
Our function will receive batches of 50 endpoints, so if you segment contains more than 50 endpoints the function will be involved multiple times (round(N/50) times to be precise).
We will receive the same input event:
Our Lambda function will need to iterate through all the given Endpoints and deliver messages via API.
Let’s implement the Lambda function that will deliver messages to FB Messenger, in Node.js:
The code snippet above defines a few configuration parameters, that I’d recommend storing on the AWS SSM Parameter Store or AWS Secrets Manager, here hard-coded for brevity.
The Lambda handler is simply iterating over event.Endpoints and generating an async API call for each one. Then we run all the API calls in parallel and wait for their completion using await Promise.all(...).
You could start from this sample implementation for FB Messenger and adapt it for your own custom channel by editing the deliver(message, user) function.
Let’s now define the CloudFormation template for our Pinpoint app:
The overall structure is the same of custom segments. Only two main differences:
- We don’t need to define a channel
- We are using DELIVERY for the campaign hook mode
You can find the full documentation here.
12. AWS ALB (Application Load Balancer)
AWS ALB is one of the three type of load balancers supported by Elastic Load Balancing on AWS, together with Network Load Balancers and Classic Load Balancers.
ALB operates at the Layer 7 of the OSI model, which means it has the ability to inspect packets and HTTP headers to optimize its job. It was announced in August 2016 and it introduced popular features such as content-based routing, support for container-based workloads, as well as for WebSockets and HTTP/2.
Since Nov 2018, ALB supports AWS Lambda too, which means you can invoke Lambda functions to serve HTTP(S) traffic behind your load balancer.
For example — thanks to the content-based routing feature — you could configure your existing application load balancer to serve all traffic under /my-new-feature with AWS Lambda, while all other paths are still served by Amazon EC2, Amazon ECS, or even on-premises servers.

While this is great to implement new features, it also opens up new interesting ways to evolve your compute architecture over time without necessarily refactoring the whole application. For example, by migrating one path/domain at a time transparently for your web or mobile clients.
If you’ve already used AWS Lambda with Amazon API Gateway, AWS ALB will look quite familiar, with a few minor differences.
Let’s have a look at the request/response structure:
AWS ALB will invoke our Lambda functions synchronously and the event structure looks like the JSON object above, which includes all the request headers, its body, and some additional metadata about the request itself such as HTTP method, query string parameters, etc.
ALB expects our Lambda function to return a JSON object similar to the following:
That’s it! As long as you apply a few minor changes to your Lambda function’s code, it’s quite straightforward to switch from Amazon API Gateway to AWS ALB. Most differences are related to the way you extract information from the input event and the way you compose the output object before it’s converted into a proper HTTP response. I’d personally recommend structuring your code by separating your business logic from the platform-specific input/output details (or the “adaptor”). This way, your business logic won’t change at all and you’ll just need to adapt how its inputs and outputs are provided.
For example, here’s how you could implement a simple Lambda function to work with both API Gateway and ALB:
Now, I wouldn’t recommend this coding exercise unless you have a real-world use case where your function needs to handle both API Gateway and ALB requests. But keep this in mind when you implement your business logic so that switching in the future won’t be such a painful refactor.
For example, here’s how I would implement a simple Lambda function that returns Hello Alex! when I invoke the endpoint with a querystring such as ?name=Alex and returns Hello world! if no name is provided:
In this case, I’d only need to apply very minor changes to build_response if I wanted to integrate the same function with API Gateway.
Now, let’s have a look at how we’d build our CloudFormation template. AWS SAM does not support ALB natively yet, so we’ll need to define a few raw CloudFormation resources:
The Application Load Balancer definition requires a list of EC2 subnets and a VPC. This is a good time to remind you that AWS ALB is not fully serverless, as it requires some infrastructure/networking to be managed and it’s priced by the hour. Also, it’s worth noting that we need to grant ALB permissions to invoke our function with a proper AWS::Lambda::Permission resource.
That said, let me share a few use cases where you may want to use AWS ALB to trigger your Lambda functions:
- You need a “hybrid” compute architecture including EC2, ECS, and Lambda under the same hostname — maybe to implement new features for a legacy system or to cost-optimize some infrequently used sub-systems
- Your API’s are under constant load and you are more comfortable with a by-the-hour pricing (ALB) than a pay-per-request model (API Gateway) — this might be especially true if you don’t need many of the advanced features of API Gateway such as input validation, velocity templates, DDOS protection, canary deployments, etc.
- You need to implement some advanced routing logic — with ALB’s content-based routing rules you can route requests to different Lambda functions based on the request content (hostname, path, HTTP headers, HTTP method, query string, and source IP)
- You want to build a global multi-region and highly resilient application powered by AWS Global Accelerator — ALB can be configured as an accelerated endpoint using the AWS global network
Let me know if you could think of a different use case for ALB + Lambda.
You can read more about this topic on the official documentation.
Also, here you can find an ALB app on the Serverless Application Repository.
Conclusions
That’s all for part 3!
I sincerely hope you’ve enjoyed diving deep into AWS CodeDeploy, AWS CodePipeline, Amazon Pinpoint, and AWS Application Load Balancer.
Now you can customize your CI/CD pipelines, implement custom segments or channels for Amazon Pinpoint, and serve HTTP traffic though AWS ALB.
This is the last episode of this series and I’d recommend checking out the first two articles here and here if you haven’t read them yet, where I talked about integrating Lambda with Amazon Cognito User Pools, AWS Config, Amazon Kinesis Data Firehose, AWS CloudFormation, AWS IoT Button, Amazon Lex, Amazon CloudWatch Logs, and Amazon Aurora.
Thank you all for reading and sharing your feedback!
As usual, feel free to share and/or drop a comment below :)
Originally published on HackerNoon on Oct 30, 2019.





Top comments (0)