September 18th, 2023 - Instalment #174
Welcome to #174 of the AWS open source newsletter, which will be the last one for a couple of weeks as I take some time off to recharge. I will be back in early October with more open source goodness, but in the meantime, you still have this edition packed with open source goodness.
This weeks new projects include a Rust tool to help you keep your CloudFormation stacks up to date, a tool to help upload files to Amazon S3, a generative AI tool that aims to help you review and detect IAM configuration issues, an updated JDBC driver for connecting to Amazon Aurora, and more. Also featured in this edition is content on open source technologies that include Apache Hudi, AWS CDK, Steampipe, OpenSearch, AWS Amplify, React, Dockle, Apache Flink, Apache Kafka, Apache Spark, Amazon EMR, Ray, Argo CD, AWS Distro for Open Telemetry, PostgreSQL, Trusted Language Extensions for PostgreSQL, and more. Make sure you check out the videos and events section. I will be attending the Open Source Summit in Bilbao, so come say hello and visit the AWS booth if you are planning to come.
Feedback
Before you dive in however, I need your help! Please please please take 1 minute to complete this short survey and you will forever have my gratitude!
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Marc Chene, Konstantinos Keramaris, Tenable, Dyego Sutil Mendes, Dave Cramer, Johannes Konings, Stefan Majiros, k.goto, Marcin Sodkiewicz, Suraj Narwade, Aaron Sempf, Puneet Talwar, Lorenzo Nicora, Francisco Morillo, Peter Celentano and Sukhpreet Kaur Bedi
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution. The projects mentioned here do not represent any formal recommendation or endorsement, I am just sharing for greater awareness as I think they look useful and interesting!
Tools
cfnupd
cfnupd is a CLI tool from Konstantinos Keramaris written in Rust that provides you with a quick and easy way to update your existing Cloudformation Stacks. From Konstantinos,
I wanted to share a small project of my own with you, hoping that it might be of interest to your readers. I recently developed a CLI tool written in rust called cfnupd , designed to streamline and simplify the process of updating existing CloudFormation stacks. The inspiration for this tool arose from my personal frustration when dealing with minor updates to "dev"-like stacks, that are not integrated with a cicd pipeline. Often, I found myself working from a machine that lacked local access to the necessary scripts and parameters meaning I first have to download the cfn template and then having to write a long aws cli command or perform multiple "clicks" on the AWS Cloudformation Console.
cfnupd downloads the CloudFormation template and parameters locally, opens an editor of choice (preferably a cli one) for easy modification, and then initiates the stack update. To the best of my knowledge, there isn't a similar CLI tool available that offers this level of convenience and efficiency.
Looks pretty interesting to me. If you give this a look, make sure you let Konstantinos know what you think.

EscalateGPT
EscalateGPT is an open source Python tool from Tenable that leverages the power of OpenAI to analyse AWS IAM misconfigurations. This tool can be used to retrieve all IAM policies associated with users or groups and will then prompt the OpenAI API, asking it to identify potential escalation opportunities and any relevant mitigations. EscalateGPT returns results in a JSON format that includes the path, the Amazon Resource Name (ARN) of the policy that could be exploited for privilege escalation and the recommended mitigation strategies to address the identified vulnerabilities.
You will need to have yourself an OpenAI key to use this, and make sure you read the README to get all the details. You can also find out more by following along in the blog post, EscalateGPT: leverages the power of OpenAI to analyze AWS IAM misconfigurations
aws-s3-presigned-post
aws-s3-presigned-post is a tool from Dyego Sutil Mendes that provides a Java library to generate pre-signed post data to be used to upload files to Amazon S3. The README is full of clear examples of how you can use this in your code. Very nice Dyego.
aws-advanced-jdbc-wrapper
aws-advanced-jdbc-wrapper is complementary to an existing JDBC driver and aims to extend the functionality of the driver to enable applications to take full advantage of the features of clustered databases such as Amazon Aurora. In other words, the AWS JDBC Driver does not connect directly to any database, but enables support of AWS and Aurora functionalities on top of an underlying JDBC driver of the user's choice. The AWS JDBC Driver is targeted to work with any existing JDBC driver. Currently, the AWS JDBC Driver has been validated to support the PostgreSQL JDBC Driver, MySQL JDBC Driver, and MariaDB JDBC Driver. In conjunction with the JDBC Drivers for PostgreSQL, MySQL, and MariaDB, the AWS JDBC Driver enables functionalities from Amazon Aurora such as fast failover for PostgreSQL and MySQL Aurora clusters. It also introduces integration with AWS authentication services such as AWS Identity and Access Management (IAM) and AWS Secrets Manager.
Check out more by reading the blog post from Dave Cramer, Introducing the Advanced JDBC Wrapper Driver for Amazon Aurora
Demos, Samples, Solutions and Workshops
aws-glue-apache-hudi-operational-data-processing-framework
aws-glue-apache-hudi-operational-data-processing-framework is a new data processing framework that you can use to expedite your journey in integrating operational databases into your modern data platforms built on AWS. The repo contains three components: 1/ File Manager, 2/ File Processor, and 3/ Configuration Manager. Each component runs independently to solve a portion of the operational data processing use case. The blog post, Simplify operational data processing in data lakes using AWS Glue and Apache Hudi looks at this new framework that has been developed by AWS Proserve, and shows how you can use it for real-world operational data processing use cases. It combines AWS services and open source tools like Apache Spark and Apache Hudi.

AWS and Community blog posts
Community round up
Starting this week's community round up we have AWS Community Builder Johannes Konings who writes about Steampipe, an open source tool that lets you query your AWS resources. In Use Steampipe to select your AWS resources across SSO accounts with SQL he shows you how you can use this across different AWS accounts that are integrated with Single Sign On. Next up we have Stefan Majiros who has put together Geo search with AWS Amplify, CDK and custom AppSync JS Resolvers in React Native and React, a tutorial on how you can incorporate geo-search support into AWS Amplify, adding custom resolvers against OpenSearch. I had not heard about Dockle before, but it turns out that this is a useful open source linter for container images focused on security and helping to build good practices. AWS Community Builder k.goto has put together Container image scanning with Dockle in AWS CDK that provides an overview of a new CDK Construct that you can use on Construct Hub that allows you to easily scan container images with Dockle, avoiding unnecessary builds if errors are encountered and saving applications being pushed to Amazon Elastic Container Registry (ECR) if they contain known vulnerabilities. Very cool stuff. Marcin Sodkiewicz has put together AWS & OpenTelemetry strikes back: Tail-based Sampling that provides an intro into what tail sampling is and how to set up OpenTelemetry collectors to work with it at scale.

To finish things off this week, we have AWS Community Builder Suraj Narwade who has put together a post about a project I featured a while back (#125, amazon-ec2-instance-selector). This is a CLI tool and go library which recommends instance types based on resource criteria like vcpus and memory, and Suraj has written Making a wise choice with ec2-instance-selector that explores how you can use this.

AWS CDK
In the post Using AWS CloudFormation and AWS Cloud Development Kit to provision multicloud resources, Aaron Sempf and Puneet Talwar debunk the misconception that CloudFormation and CDK can only be used to provision resources on AWS. They show you how you can reduce the cost and complexity of maintaining deployment pipelines across multiple cloud providers [hands on]

Apache Flink
Apache Flink is an open-source distributed engine for stateful processing over unbounded datasets (streams) and bounded datasets (batches). In a new two part blog post from Lorenzo Nicora and Francisco Morillo, they dive deeper into checkpointing mechanisms and in-flight data buffering, explaining some of the fundamental Apache Flink internals, covering the buffer debloating feature, and taking a look at unaligned checkpoints. So grab yourself the first part, Optimize checkpointing in your Amazon Managed Service for Apache Flink applications with buffer debloating and unaligned checkpoints – Part 1, and take it from there. [hands on]

Other Big Data and Analytics posts
- Securely process near-real-time data from Amazon MSK Serverless using an AWS Glue streaming ETL job with IAM authentication demonstrates how to build an end-to-end implementation to process data from Apache Kafka using an AWS Glue streaming extract, transform, and load (ETL) job with IAM authentication to connect MSK Serverless from the AWS Glue job and query the data using Amazon Athena [hands on]

- Run Spark-RAPIDS ML workloads with GPUs on Amazon EMR on EKS provides a nice hands on guide that shows the capabilities of the NVIDIA Spark-RAPIDS Accelerator for running ML workloads with Spark on EMR on EKS using GPU instances [hands on]

- Optimize equipment performance with historical data, Ray, and Amazon SageMaker builds an end-to-end solution to find optimal control policies using only historical data on Amazon SageMaker using Ray’s RLlib library [hands on]
- Extracting key insights from Amazon S3 access logs with AWS Glue for Ray presents an architecture solution that allows customers to extract key insights from Amazon S3 access logs at scale, using Ray, a popular new open source compute framework that helps you scale Python workloads [hands on]
Other posts and quick reads
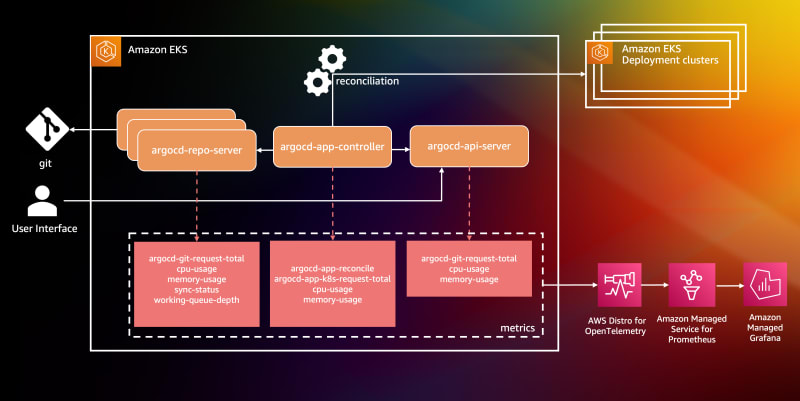
- Argo CD Application Controller Scalability Testing on Amazon EKS discusses initial efforts in scaling Argo CD to support 10,000 applications deployed across as many as 97 Kubernetes clusters [hands on]
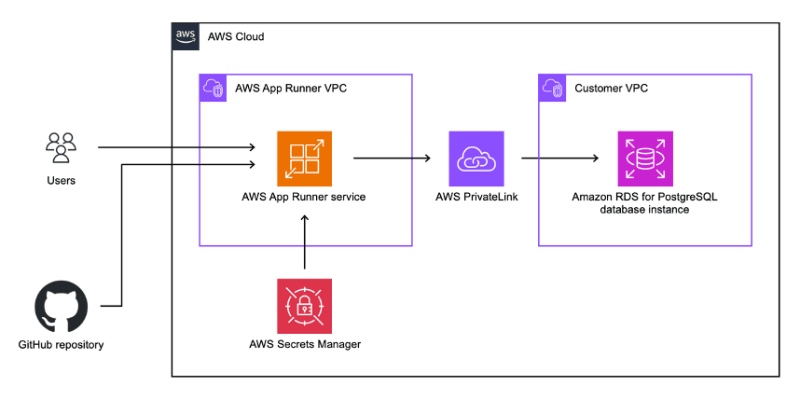
- Deploy and scale Django applications on AWS App Runner shows how to deploy and scale a Django web application on AWS App Runner and how to securely connect to a managed database with Amazon Relational Database Service (Amazon RDS) for PostgreSQL [hands on]
- Managing Amazon EBS volume throughput limits in Amazon OpenSearch Service domains looks at the impact of Amazon Elastic Block Store (Amazon EBS) volume IOPS and throughput limits on Amazon OpenSearch Service domain and how to prevent/mitigate throughput throttling situation [hands on]
- Tracing Tenant Activity for Multi-Account SaaS with AWS Distro for Open Telemetry explores how to collect tracing data across your multi-account SaaS environment using AWS Distro for Open Telemetry (ADOT) and publish events to a control plane for data aggregation and analysis [hands on]

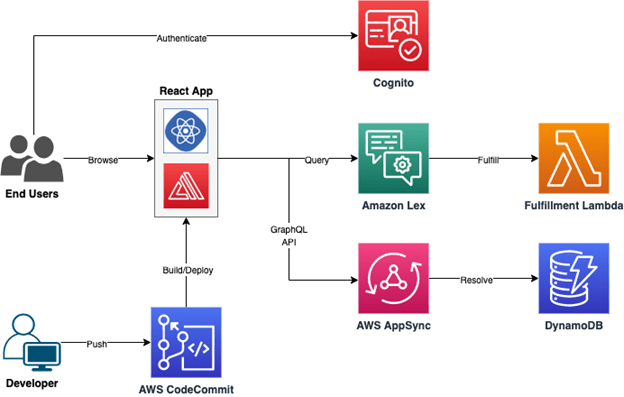
- Build a Conversational AI app to Interact with AWS using AWS Amplify showcases building a conversational application by harnessing AWS Amplify and integrating it with Amazon Lex, looking at some of the essential backend components, such as authentication workflows, API interfaces, data management, and intent fulfilment business logic [hands on]
Quick updates
Amazon EMR
You can now select Amazon Linux 2023 (AL2023) on Amazon EMR on EKS. Customers can use AL2023 as the operating system together with Java 17 as Java runtime to run Spark workloads on Amazon EMR on EKS. This provides customers a secure, stable, high-performance environment to develop and run their applications as well as enables them to access the latest enhancements such as kernel, toolchain, glibc, openssl and other system libraries and utilities. Previously, customers could only run their Spark jobs on Amazon EMR on EKS with Amazon Linux 2 (AL2) as the operating system. Now, with this launch, Amazon EMR on EKS supports AL2023 as an operating system, which offers several improvements over AL2 such as supporting Python 3.9 by default, the GNU C Library (glibc) is upgraded to 2.34 in AL2023, GNU Compiler Collection (gcc) is upgraded to 11.3, and more. For a complete list of the difference between AL2 and AL2023, please visit AL2023 user guide.
OpenSearch
Amazon OpenSearch Serverless has expanded its auto-scaling capabilities to efficiently handle tens of thousands of query transactions per minute. With this new feature, you can rely on OpenSearch Serverless to help handle unpredictable surges in your search and query traffic. At launch, OpenSearch Serverless supported two replicas of the index with redundancy for Availability Zone outages and infrastructure failures. With the new feature, OpenSearch Serverless will respond to the spikes in search traffic by detecting the shards under duress, dynamically increasing the shard replicas and then seamlessly scaling back when the workload demand reduces. Rather than automatically augmenting the entire index, OpenSearch Serverless only adds the replicas for the shards under high utilisation (hot shards), thus providing a cost-effective solution for the customers while providing fast response times and availability.
PostgreSQL
Amazon Relational Database Service (Amazon RDS) PostgreSQL Multi-AZ Deployments with two readable standbys now supports major version upgrades. Starting today, you can upgrade your RDS for PostgreSQL Multi-AZ Deployments with two readable standbys from major version 13.4 and above and 14.5 and above to 15.4 with just a few clicks on the AWS Management Console. PostgreSQL 15.4 offers several performance and feature benefits that include SQL standard "MERGE" command for conditional SQL queries, performance improvements for both in-memory and disk-based sorting, and support for two-phase commit and row/column filtering for logical replication. The PostgreSQL 15 release also adds support for new extension pg_walinspect, and server-side compression with Gzip, LZ4, or Zstandard (zstd) using pg_basebackup.
Read more about what's new in PostgreSQL 15 and test your application for compatibility before you upgrade your databases.
Trusted Language Extensions for PostgreSQL
Trusted Language Extensions for PostgreSQL (pg_tle) is an open source development kit to help you build extensions written in a trusted language that run safely on PostgreSQL. Support for custom data types included with the PostgreSQL extension pg_tle v1.1.1 is available on database instances in Amazon RDS running PostgreSQL 15.4 and higher, 14.9 and higher, and 13.12 and higher. pg_tle now supports building your own custom data types and is available on Amazon Relational Database Service (RDS) for PostgreSQL. You can now use Trusted Language Extensions for PostgreSQL to create a new base (or scalar) data type, specify how it is stored, and define functions that support SQL and index operations for this new data type. Custom data types are helpful when extending PostgreSQL to support functional domains where a built-in type such as number or text can’t provide sufficient search semantics. For example, an AWS resource can be uniquely identified by an Amazon Resource Name (ARN). You can build an ARN custom data type to store and compare ARNs from your application, and leverage PostgreSQL functionality such as indexes to accelerate searches.
Peter Celentano and Sukhpreet Kaur Bedi have put together a handy post, Create custom PostgreSQL data types using Trusted Language Extensions, that dives deeper on this new update, and demonstrate how to create custom PostgreSQL data types using TLE.
AWS Amplify
AWS Amplify Studio announced last week full support for GraphQL APIs. Developers using GraphQL APIs created either with Amplify Studio or Amplify CLI will now fully have access to all of Studio’s features. This includes Form Builder, Figma to Code UI generation, and Data Manager. Previously, Studio’s data-powered features were only available to developers using Amplify DataStore. With this launch, we’ve extended access to these features to support all Amplify GraphQL APIs. All new and existing Amplify developers can now generate forms connected to their API, manage records in their API with Data Manager, and create data-bound Figma to React components.
Videos of the week
Monitor Modern Applications—The Managed Open Source Way on AWS
If you are looking to learn more about some of the open source observability tools you can deploy or use on AWS to help you manage your infrastructure and applications, then take a look at this video from Marc Chene, who shows you how you can collect, export, and query telemetry data, and quickly set up dashboards to identify patterns or issues.
Using AWS CloudFormation and AWS Cloud Development Kit to provision multicloud resources
If you read and were interested in the CDK post and workshop that shows you how you can use CDK to provision resources in other cloud providers, you can check out this bonus video.
Open Source Brief
Now featured every week in the AWS Community Radio show, grab a quick five minute recap of the weekly open source newsletter from yours truly.
Check out the playlist here.
Build on Open Source
For those unfamiliar with this show, Build on Open Source is where we go over this newsletter and then invite special guests to dive deep into their open source project. Expect plenty of code, demos and hopefully laughs. We have put together a playlist so that you can easily access all (sixteen) of the episodes of the Build on Open Source show. Build on Open Source playlist.
We are currently planning the third series - if you have an open source project you want to talk about, get in touch and we might be able to feature your project in future episodes of Build on Open Source.
Events for your diary
If you are planning any events in 2023, either virtual, in person, or hybrid, get in touch as I would love to share details of your event with readers.
Open Source Summit, Europe
Bilbao, 18th-21st September
"Open Source Summit is the premier event for open source developers, technologists, and community leaders to collaborate, share information, solve problems, and gain knowledge, furthering open source innovation and ensuring a sustainable open source ecosystem. It is the gathering place for open-source code and community contributors."
If you are coming to the Open Source Summit Europe in Bilbao this week, make sure you pop by the AWS booth where we will be having lots of open source goodness, including SWAG and a demo station where we will be showing Powetools for Lambda, Cedar, OpenSearch. You will also catch many of the folks working on open source at AWS, including myself. So please stop hi and be sure to take a selfie with the crew.
Find out more at the official site, Open Source Summit Europe 2023.
Build ML into your apps with PostgreSQL and the pgvector extension
YouTube, 21st September 4pm UK time
This office hours session is a follow up for those who attended the fireside chat titled "Building ML capabilities into your apps with PostgreSQL and the open-source pgvector extension". Others are also welcome. Office hours attendees can ask questions related to this topic. Application developers who use Amazon Aurora for PostgreSQL or Amazon RDS for PostgreSQL can use pgvector, an open-source extension for PostgreSQL, to harness the power of generative AI and LLMs for driving richer user experiences. Join us to ask your questions and hear the answers to the most frequently asked questions about the pgvector extension for PostgreSQL.
Watch it live on YouTube.
OpenSearchCon
Seattle, September 27-29, 2023
Registration is now open source OpenSearchCon. Check out this post from Daryll Swager, Registration for OpenSearchCon 2023 is now open! that provides you with what you can expect, and resources you need to help plan your trip.
CDK Day, 2023
Online, 29th September 2023
Back for the fourth instalment, this Community led event is a must attend for anyone working with infrastructure as code using the AWS Cloud Development Kit (CDK). It is intended to provide learning opportunities for all users of the CDK and related libraries. The event will be live streamed on YouTube, and you check more at the website, CDK Day
All Things Open
October, 15th-17th, Raleigh Convention Center, Raleigh, North Carolina
I will be attending and speaking at All Things Open, looking at Apache Airflow as an container orchestrator. I will be there with a bunch of fellow AWS colleagues, and I hope to meet some of you there. Check us out at the AWS booth, where you will find me and the other AWS folk throughout the event. Check out the event and sessions/speakers at the official webpage for the event, AllThingsOpen 2023
Open Source India
October 19th-21st, NIMHANS Convention Center, Bengaluru
One of the most important open source events in the region, Open Source India will be welcoming thousands of attendees all to discuss and learn about open source technologies. I will be there too, doing a talk so I would love to meet with any of you who are also planning on attending. Check out more details on their web page, here.
Cortex
Every other Thursday, next one 16th February
The Cortex community call happens every two weeks on Thursday, alternating at 1200 UTC and 1700 UTC. You can check out the GitHub project for more details, go to the Community Meetings section. The community calls keep a rolling doc of previous meetings, so you can catch up on the previous discussions. Check the Cortex Community Meetings Notes for more info.
OpenSearch
Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Stay in touch with open source at AWS
Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen





Top comments (1)
nice article