September 11th, 2023 - Instalment #173
Welcome to #173 of the AWS open source newsletter, bringing you all the news and latest projects for AWS developers. This weeks new projects include a Golang based SDK for kernel eBPF operations, a project that helps you to optimise your network performance, a couple of projects for Apache Flink users, as well as a handful of different tools and demos featuring open source technologies helping to drive innovation in generative AI. !As well as the new projects, we also have content this week on open source technologies including ebpf, Apache Flink, Griptape, AWS Amplify, Amazon Corretto, Smithy, lakeFS, Jupyter, GitLab, OpenSearch, Apache Kafka, Apache Iceberg, OpenQAOA, AWS Toolkit for Visual Studio, Apache Airflow, PostgreSQL, MySQL, AWS SAM, PyTorch, and Flux.
Finally, be sure to check out the events section as there are a few events happening this week. Before you dive into the newsletter, check out the following information on open source mentorship program being sponsored by the OpenSearch project.
Open Source Mentorship
The OpenSearch group is going to be doing their second cohort of our open source mentorship program. This program helps new developers make contributions to open source software, giving them a portfolio to launch them into their career. This is a really exciting opportunity, so please make some time to read Receive mentorship from Amazon engineers and accelerate your career in Tech where Iskander Rakhman talks about the history of the program, provides lots of details you will want to know, and provides a link where you can sign up. Please share with anyone you know who is looking for an opportunity like this to kick start their open source journey.

Feedback
Before you dive in however, I need your help! Please please please take 1 minute to complete this short survey and you will forever have my gratitude!
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Jay Pillai, Shikhar Kwatra, Karthik Sonti, Ken Collins, Supratip Banerjee, Nathan Peck, Lionel Tchami, Dr. Aparna Sundar, Will Childs-Klein, Andrew Foss, Vijay Karumajji, Eric Johnson, Rio Astamal, Sukhpreet Bedi, Betty Zheng, and Iskander Rakhman
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution. The projects mentioned here do not represent any formal recommendation or endorsement, I am just sharing for greater awareness as I think they look useful and interesting!
Tools
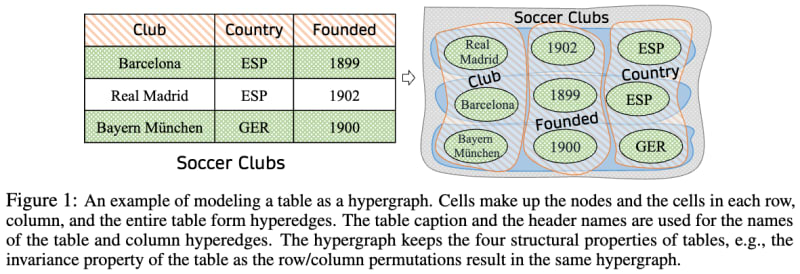
hypergraph-tabular-lm
hypergraph-tabular-lm This repository contains the official implementation for the paper HyTrel: Hypergraph-enhanced Tabular Data Representation Learning with code, data, and checkpoints. From the abstract we can see:
Language models pretrained on large collections of tabular data have demonstrated their effectiveness in several downstream tasks. However, many of these models do not take into account the row/column permutation invariances, hierarchical structure, etc. that exist in tabular data. To alleviate these limitations, we propose HYTREL, a tabular language model, that captures the permutation invariances and three more structural properties of tabular data by using hypergraphs–where the table cells make up the nodes and the cells occurring jointly together in each row, column, and the entire table are used to form three different types of hyperedges.
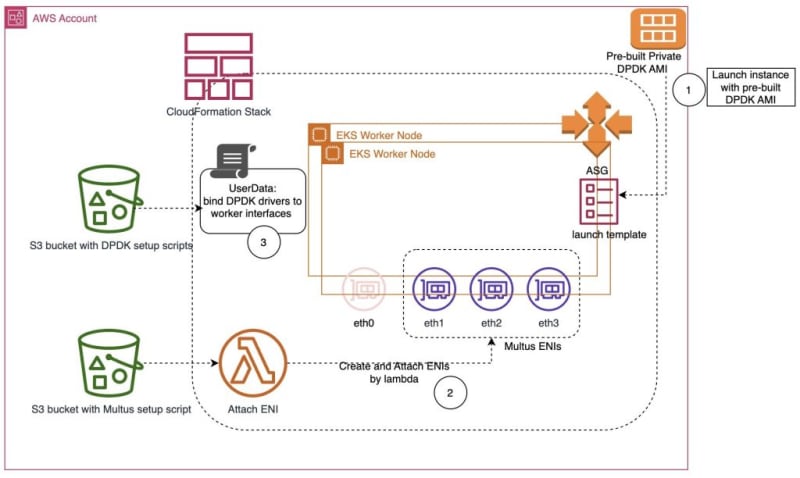
dpdk-setup-eks
dpdk-setup-eks provides sample code on how you can use packet acceleration using SRIOV (Single Root I/O Virtualization) and DPDK (Data Plane Development Kit) to achieve high network bandwidth, maximum throughput, and minimal latency in your cloud native workloads. SRIOV enables hardware-based acceleration in a virtualised environment that provides higher I/O performance, lower CPU utilisation, higher packet per second (PPS) performance, and lower latency. DPDK provides software-based development kit, which bypasses the operating system (OS) kernel and reduces packet processing overhead, resulting in performance improvement and lower latency. To help you get started with this code, following along with the post Automate Packet Acceleration configuration using DPDK on Amazon EKS.
aws-ebpf-sdk-go
aws-ebpf-sdk-go is a Golang based SDK for kernel eBPF operations i.e, load/attach/detach eBPF programs and create/delete/update maps. SDK relies on Unix bpf() system calls. This SDK currently supports eBPF program types (a. Traffic Classifiers b. XDP c. Kprobes/Kretprobes d. Tracepoint probes), and Ring buffer (would need kernel 5.10+). The SDK currently does not support Map in Map and Perf buffer. This is the first version of SDK and interface is subject to change so kindly review the release notes before upgrading.
static-checker-flink
static-checker-flink The goal of this project is to catch certain issues with Apache Flink applications fast (during build/packaging). Covered cases include Kinesis connector compatibility issues, Apache Kafka connector compatibility issues, and MSK IAM Auth library issues. As an example of how you might use this, did you know that you have to use AWS Kinesis Connector 1.15.4 or above for Apache Flink 1.15 apps? This plugin is there to stop you from building an app that has such incompatible connector versions.
managed-service-for-apache-flink-blueprints
managed-service-for-apache-flink-blueprints are a curated collection of Apache Flink applications. Each blueprint will walk you through how to solve a practical problem related to stream processing using Apache Flink. These blueprints can be leveraged to create more complex applications to solve your business challenges in Apache Flink, and they are designed to be extensible. We will feature examples for both the DataStream and Table API where possible.
Currently the repo contains two blueprints, and you will find examples of Apache Flink applications that can be run locally, on an open source Apache Flink cluster, or on Managed Service for Apache Flink cluster.
Demos, Samples, Solutions and Workshops
generative-ai-demo-on-miro
generative-ai-demo-on-miro is the source code for a super cool demo that shows three Generative AI use-cases integrated into single solution on Miro board (digital whiteboard). It turns Python notebooks into dynamic interactive experience, where several team members can brainstorm, explore, exchange ideas empowered by privately hosted Sagemaker generative AI models. This demo can be easily extended by adding use-cases to demonstrate new concepts and solutions.

lambda-rag
lambda-rag is a Retrieval Augmented Generation Chat AI Demo from AWS Hero Ken Collins. This OpenAI based RAG chat application that can help you learn about AI retrieval patterns. The technologies here are beginner friendly and easy to deploy to AWS Lambda. You will need an OpenAI API key to run this application, so check out the README for more details on other dependencies.
To help you get started and help explain everything, Ken has put together a couple of great blog posts that really do a fantastic job of explaining the approach and the details. Make sure you read RAGs To Riches - Part #1 Generative AI & Retrieval, and the not surprisingly named, RAGs To Riches - Part #2 Building On Lambda

griptape-hello-world
griptape-hello-world Griptape is an open source project that provides an enterprise grade alternative to tools like LangChain, and in this repo I share some code that I put together whilst testing it out as part of writing a short blog post on this project, Getting gnarly with AI - a quick look at Griptape, an enterprise ready alternative to LangChain. Let me know what you think if you try this out.
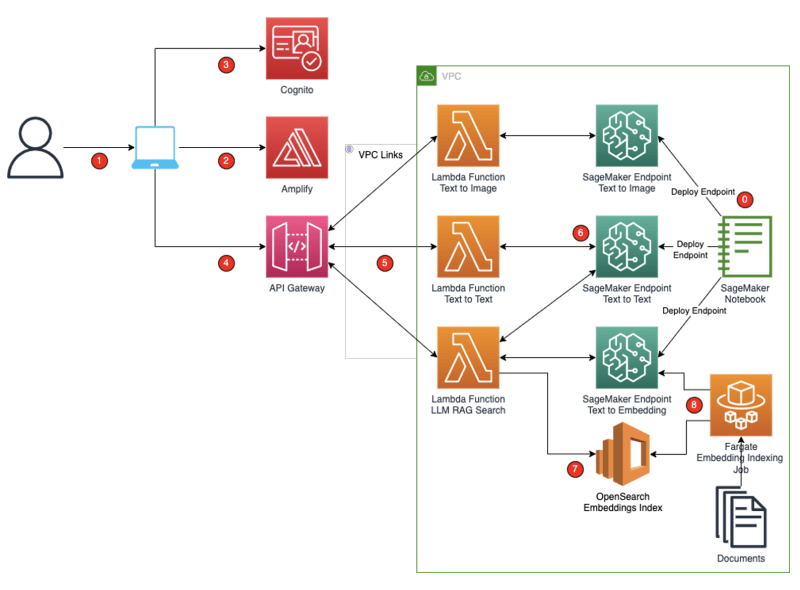
genai-jumpstart-amplify-cdk-app
genai-jumpstart-amplify-cdk-app In this project we show you how you can take a SageMaker Generative AI model, expose it as a SageMaker Endpoint and consume the Foundational Model in a React Amplify front end. This sample project also demonstrates an implementation of Retrieval Augmented Generation using AWS OpenSearch. The project illustrates how to take sample documents and use a SageMaker Endpoint running an Embeddings LLM to get the embeddings and create an embeddings index within OpenSearch. The app integrates with Cognito for authentication. All the backend components including Lambda, SageMaker Endpoints, OpenSearch, Fargate all run within a VPC.
Jay Pillai, Shikhar Kwatra, and Karthik Sonti have put together a detailed blog post, Build a secure enterprise application with Generative AI and RAG using Amazon SageMaker JumpStart, to help bootstrap you with this code.
AWS and Community blog posts
Community round up
The community round up is my favourite part of the newsletter, as I get to read about some of the great open source work being done by the AWS community. This week starts off with AWS Community Builder Supratip Banerjee who takes a look at how to build Data version control using lakeFS, an open-source project that provides format-agnostic version control for data lakes, in the post A Step-by-Step Guide to Implementing Data Version Control. Next up we have Nathan Peck who has put together Deploy Jupyter notebook container with Amazon ECS, which is a nice detailed blueprint that shows how you can deploy Jupyter notebooks on Amazon ECS, leveraging underlying infrastructure optimised for AI (AWS Inferentia and AWS Trainium instance types). AWS Community Builders Lionel Tchami takes a look at setting up CI/CD pipelines using GitLab in his post, Every Project Deserves its CI/CD pipeline, no matter how small, something I think we can all agree on. To wrap things up this week, we finish with Dr. Aparna Sundar who has put together OpenSearch Dashboards: A usability snapshot that takes a look at the approach taken to enhance the user experience for OpenSearch users.
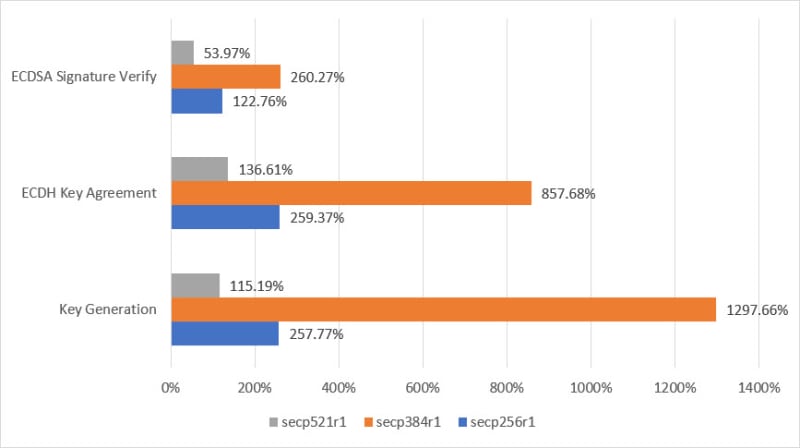
Amazon Corretto
Amazon Corretto Crypto Provider (ACCP) is a collection of high-performance cryptographic implementations exposed via standard JCA/JCE interfaces, something I have spoken and demoed in the past. It is super cool stuff! I was therefore delighted when I saw Will Childs-Klein's post, Accelerating JVM cryptography with Amazon Corretto Crypto Provider 2 which looks at the updated version (ACCP 2) delivers comprehensive performance enhancements, with some algorithms (such as elliptic curve key generation) seeing a greater than 13-fold improvement over ACCP 1. This release also sees changes to the backing cryptography library for ACCP from OpenSSL (used in ACCP 1) to the AWS open source cryptography library, AWS libcrypto (AWS-LC). If you are a Java developer, then this is a must read post this week.
Smithy
Smithy is an open-source Interface Definition Language (IDL) and set of tools for building web services, created by AWS. AWS uses Smithy to model services, generate server scaffolding, generate SDKs for multiple languages, and generate AWS SDKs. Andrew Foss is excited to announce the release of a new capability, which he writes about in his post Creating Smithy Projects with Smithy Init. The release of the init command in Smithy CLI, enables developers to create new Smithy projects quickly and easily. Jump into the post to find out more about Smithy and this new update. [hands on]
Other posts and quick reads
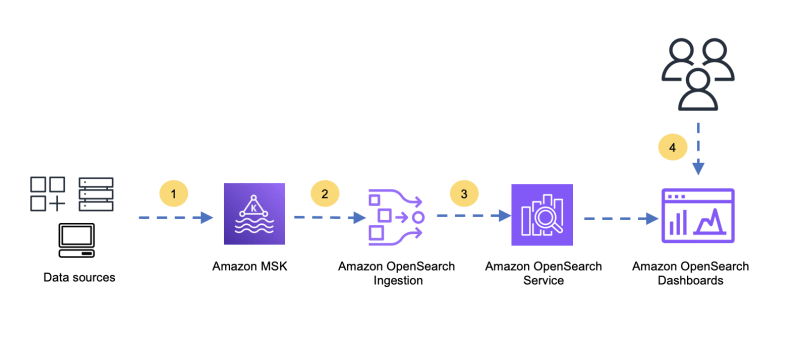
- Introducing Amazon MSK as a source for Amazon OpenSearch Ingestion looks at Amazon MSK as a source to Amazon OpenSearch Ingestion, a serverless, fully managed, real-time data collector for OpenSearch Service that makes this ingestion even easier [hands on]
- Query your Iceberg tables in data lake using Amazon Redshift (Preview) provides an example of querying an Iceberg table in Redshift using files stored in Amazon S3, demonstrating some of the key features like efficient row-level update and delete, and the schema evolution experience [hands on]
- Optimization with OpenQAOA on Amazon Braket explores how the open source project OpenQAOA is integrated with Amazon Braket, demonstrating how to cast an optimisation problem
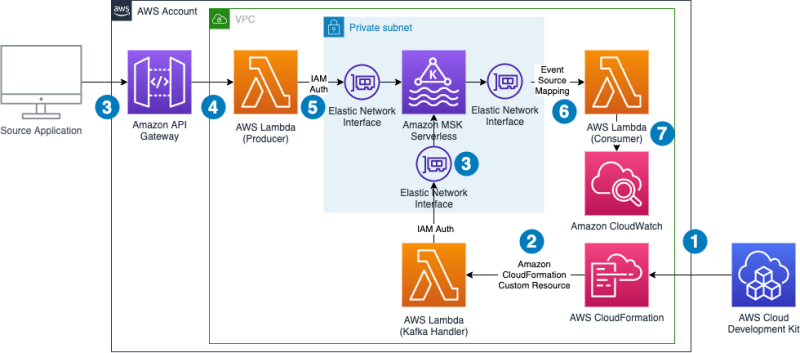
- Build streaming data pipelines with Amazon MSK Serverless and IAM authentication shows you how to create a serverless integration Lambda function between API Gateway and MSK Serverless as a way to do IAM authentication when your producer is not written in Java [hands on]
- Use the reverse token filter to enable suffix matching queries in OpenSearch gives a hands on guide on how you can implement a suffix-based search [hands on]
Quick updates
AWS Toolkit for Visual Studio
Announced last week was news that the AWS Toolkit for Visual Studio is now generally available on the Arm64 version of Visual Studio (aka “Arm64 Visual Studio”). This release enables a Visual Studio user on a native Windows Arm64 device or on a device emulating Windows Arm64 on a M class Apple device to leverage the same AWS tooling that has been available to x64 versions of Visual Studio. You can read the full details in the post, AWS Toolkit for Visual Studio adds support for Arm64 Visual Studio
AWS SDK
There is an upcoming change in the S3 GetObjectAttributes API, and so John Viegas has put together a post that users of the AWS SDK for Java v2, AWS SDK for .NET v3, and AWS Tools for PowerShell should read and understand how they can prepare. You can catch the post here, Update to AWS SDK for Java v2, AWS SDK for .NET v3, and AWS Tools for PowerShell when using S3 GetObjectAttributes API
Apache Airflow
Amazon Managed Workflows for Apache Airflow (MWAA) has added certifications for International Organization for Standardization (ISO) and Information Security Registered Assessors Program (IRAP). Amazon Web Services (AWS) maintains certifications through extensive audits of its controls to ensure that information security risks that affect the confidentiality, integrity, and availability of company and customer information are appropriately managed.
Amazon MWAA is a managed orchestration service for Apache Airflow that makes it easier to set up and operate end-to-end data pipelines in the cloud. Amazon MWAA has certification for compliance with ISO/IEC 27001:2013, 27017:2015, 27018:2019, 27701:2019, 22301:2019, 9001:2015, and CSA STAR CCM v4.0. You can download copies of the AWS ISO certificates and use them to jump-start your own certification efforts. Further, with IRAP certification, you can meet the Australian Government Information Security Manual (ISM) control objectives while using Amazon MWAA.
In addition to ISO and IRAP certification, Amazon MWAA is also Health Insurance Portability and Accountability Act (HIPAA) eligible, in scope for System and Organization Controls (SOC) reports, and Payment Card Industry Data Security Standard (PCI) compliant.
MySQL and PostgreSQL
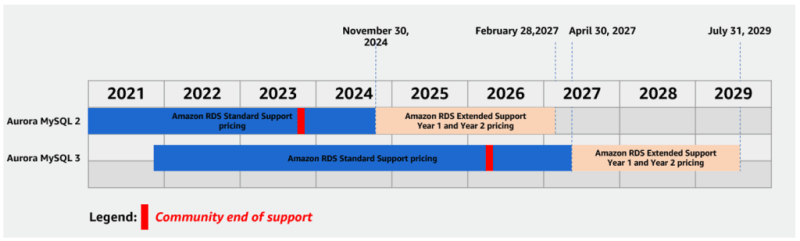
Amazon Relational Database Service (RDS) announces Amazon RDS Extended Support for Amazon Aurora and Amazon RDS database instances running MySQL 5.7, PostgreSQL 11, and higher major versions beyond the community end of life. Amazon RDS Extended Support provides you more time, up to three years, to upgrade to a new major version to help you meet your business requirements. Extended Support is available for Aurora MySQL-compatible edition, Aurora PostgreSQL-compatible edition, RDS for MySQL and RDS for PostgreSQL.
Starting in December, 2023, you will be able to opt-in to Amazon RDS Extended Support through the AWS Console, CLI, and APIs. When you opt-in to Extended Support, Amazon RDS will provide critical security and bug fixes for your MySQL and PostgreSQL databases after the community ends support for a major version. You can run your databases on Amazon Aurora and Amazon RDS with Extended Support for up to three years beyond a major version’s end of standard support date. Learn more about Extended Support, including supported engine versions, in the Amazon Aurora user guide and Amazon RDS User Guide.
Amazon RDS Extended Support is now available for Aurora MySQL-Compatible version 2 and higher, Aurora PostgreSQL-Compatible version 11 and higher, RDS for MySQL major versions 5.7 and higher, and RDS for PostgreSQL major versions 11 and higher in AWS Commercial and AWS GovCloud (US) Regions.
Find out more by reading the post, Introducing Amazon RDS Extended Support for MySQL databases on Amazon Aurora and Amazon RDS, where Vijay Karumajji makes some compelling arguments why you should try and upgrade, but failing that, how Amazon RDS Extended Support can help.
PostreSQL
Aside from the Extended support news just mentioned, there are a couple of other updates worth noting.
First is news that Amazon Relational Database Service (RDS) for PostgreSQL now supports the h3-pg extension, which provides an API to H3, an open-source hexagonal, hierarchical geospatial indexing system. With this extension, you can perform different kinds of spatial analysis over large datasets, including efficient indexing and lookups, modeling flow through a grid, and applying machine learning models over your geospatial data stored in Amazon RDS for PostgreSQL. The H3 library provides an invariant set of hexagonal map tiles over multiple layers of resolution. This allows the h3-pg extension to index your geospatial data so you can efficiently query data on your maps. For example, a retailer planning new outlets may want to create a heatmap visualisation using traffic, mobility, demographic, and other geospatial datasets to identify locations best suited for their customers. You can also use H3 and PostGIS together to perform different geospatial analyses. h3-pg is available on database instances in Amazon RDS running PostgreSQL 15.4, 14.9, 13.12 and higher in all applicable AWS Regions.
Finally, Amazon RDS for PostgreSQL 16 Release Candidate 1 (RC1) is now available in the Amazon RDS Database Preview Environment, allowing you to evaluate the pre-release of PostgreSQL 16 on Amazon RDS for PostgreSQL. You can deploy PostgreSQL 16 RC1 in the Preview Environment and have the same benefits of a fully managed database, making it simpler to set up, operate, and monitor databases. PostgreSQL 16RC1 in the Preview Environment also includes support for logical decoding on read replicas, AWS libcrypto (AWS-LC), and over 80 PostgreSQL extensions such as pgvector, pg_tle, h3-pg, pg_cron, and rdkit.
The PostgreSQL community released PostgreSQL 16 RC1 on August 31, 2023 that enables logical replication from standbys and includes numerous performance improvements. PostgreSQL 16 also adds support for SQL/JSON constructors and identity functions, more query types that can use parallelism, introduction of using SIMD CPU acceleration, and the ‘pg_stat_io’ view that provides statistics on I/O usage. The Amazon RDS Database Preview Environment supports the latest generation of instance classes that are retained for a maximum period of 60 days and are automatically deleted after the retention period. Amazon RDS database snapshots that are created in the Preview Environment can only be used to create or restore database instances within the Preview Environment. You can use the PostgreSQL dump and load functionality to import or export your databases from the Preview Environment.
AWS Serverless Application Model (SAM)
The AWS Serverless Application Model (SAM) Command Line Interface (CLI) announces the launch of SAM CLI local testing and debugging on HashiCorp Terraform. The AWS SAM CLI is a developer tool that makes it easier to build, test, package, and deploy serverless applications. Terraform is an infrastructure as code tool that lets you build, change, and version cloud and on-premises resources safely and efficiently.
Customers can now use the SAM CLI to locally test and debug AWS Lambda functions and Amazon API Gateway defined in their Terraform application. SAM CLI can read the infrastructure resource information from the Terraform project and start Lambda functions and API Gateway endpoints locally running in a Docker container. Customers can invoke their function or API endpoint with an event payload, or attach a debugger using AWS toolkits on IDE to step through the Lambda function code. Previously, SAM CLI only supported local testing and debugging on CloudFormation templates. With this change, Terraform users can use the SAM CLI local testing commands like sam local start-api, sam local start-lambda and sam local invoke on their Terraform projects to speed up their development cycles. They can also use sam local generate command to generate mock test events for local testing.
This feature is supported with Terraform version 1.1+ and you can find out more by reading the post from Eric Johnson, AWS SAM support for HashiCorp Terraform now generally available
PyTorch
SageMaker Multi-Model Endpoint (MME) is a fully managed capability that allows customers to deploy 1000s of models on a single SageMaker endpoint and reduce costs. Until today, MME was not supported for PyTorch models deployed using TorchServe. Now, customers can use MME to deploy 1000s of PyTorch models using TorchServe to reduce inference costs.
Customers are increasingly building ML models using PyTorch to achieve business outcomes, To deploy these ML models, customers use TorchServe on CPU/GPU instances to meet desired latency and throughput goals. However, costs can add up if customers are deploying 10+ models. With MME support for TorchServe, customers can deploy 1000s of PyTorch based models on a single SageMaker endpoint. Behind the scenes, MME will run multiple models on a single instance and dynamically load/unload models across multiple instances based on the incoming traffic. With this feature, customers can save costs, as they can share instances behind an endpoint across 1000s of models and only pay for the number of instances used.
This feature supports PyTorch models which use SageMaker TorchServe Inference Container with all machine learning optimised CPU instances and single GPU instances in ml.g4dn, ml.g5, ml.p2, ml.p3 family. It is also available in all regions supported by Amazon SageMaker.
lightsail-miab-installer
This is a project from my fellow developer advocate Rio Astamal, that provides a user-friendly command-line tool to streamline the setup of Mail-in-a-Box on Amazon Lightsail. Rio contacted me that lightsail-miab-installer has had an update so go check out the changelog for updates.
Videos of the week
Start building with PL/Rust in Amazon RDS for PostgreSQL
Rust combines the performance and resource efficiency of compiled languages like C with mechanisms that limit the risks from unsafe memory use. As a PostgreSQL trusted procedural language, PL/Rust provides memory safety so that an unprivileged user can run code in the database without the risk of crashing the database due to a software defect that corrupts memory. Developers can also package PL/Rust code as Trusted Language Extensions (TLE) for PostgreSQL to run on Amazon RDS. RDS for PostgreSQL customers can now use Rust to build high performance user defined functions to extend PostgreSQL for compute-intensive data processing.
In this session, Sukhpreet Bedi provides a brief introduction to Rust, walk you through how to deploy RDS for PostgreSQL with PL/Rust enabled, and show you how to write high-performance Rust code directly to your database.
Mastering GitOps with Flux: Step-by-Step Guide for Effective Implementation
GitOps is an effective way to achieve continuous deployment for Kubernetes clusters while meeting enterprise requirements like security, separation of privileges, audibility, and agility. In this series of 4 demos, Betty Zheng will show you some good practices for GitOps based on EKS and Flux CD. Check the YouTube listing for the supporting code so you can follow along too.
Open Source Brief
Now featured every week in the AWS Community Radio show, grab a quick five minute recap of the weekly open source newsletter from yours truely.
Check out the playlist here.
Build on Open Source
For those unfamiliar with this show, Build on Open Source is where we go over this newsletter and then invite special guests to dive deep into their open source project. Expect plenty of code, demos and hopefully laughs. We have put together a playlist so that you can easily access all (sixteen) of the episodes of the Build on Open Source show. Build on Open Source playlist.
We are currently planning the third series - if you have an open source project you want to talk about, get in touch and we might be able to feature your project in future episodes of Build on Open Source.
Events for your diary
If you are planning any events in 2023, either virtual, in person, or hybrid, get in touch as I would love to share details of your event with readers.
Building ML capabilities with PostgreSQL and pgvector extension
YouTube, 14th September 4pm UK time
Generative AI and Large Language Models (LLMs) are powerful technologies for building applications with richer and more personalized user experiences. Application developers who use Amazon Aurora for PostgreSQL or Amazon RDS for PostgreSQL can use pgvector, an open-source extension for PostgreSQL, to harness the power of generative AI and LLMs for driving richer user experiences. Register now to learn more about this powerful technology.
Watch it live on YouTube.
Build ML into your apps with PostgreSQL and the pgvector extension
YouTube, 21st September 4pm UK time
This office hours session is a follow up for those who attended the fireside chat titled "Building ML capabilities into your apps with PostgreSQL and the open-source pgvector extension". Others are also welcome. Office hours attendees can ask questions related to this topic. Application developers who use Amazon Aurora for PostgreSQL or Amazon RDS for PostgreSQL can use pgvector, an open-source extension for PostgreSQL, to harness the power of generative AI and LLMs for driving richer user experiences. Join us to ask your questions and hear the answers to the most frequently asked questions about the pgvector extension for PostgreSQL.
Watch it live on YouTube.
Open Source Summit, Europe
September 19th-21st, Bilboa Spain
"Open Source Summit is the premier event for open source developers, technologists, and community leaders to collaborate, share information, solve problems, and gain knowledge, furthering open source innovation and ensuring a sustainable open source ecosystem. It is the gathering place for open-source code and community contributors." You will find AWS as well as myself at Open Source Summit this year, so come by the AWS booth and say hello - from the glimpses I have seen so far, it is going to be awesome! Find out more at the official site, Open Source Summit Europe 2023.
OpenSearchCon
Seattle, September 27-29, 2023
Registration is now open source OpenSearchCon. Check out this post from Daryll Swager, Registration for OpenSearchCon 2023 is now open! that provides you with what you can expect, and resources you need to help plan your trip.
CDK Day, 2023
Online, 29th September 2023
Back for the fourth instalment, this Community led event is a must attend for anyone working with infrastructure as code using the AWS Cloud Development Kit (CDK). It is intended to provide learning opportunities for all users of the CDK and related libraries. The event will be live streamed on YouTube, and you check more at the website, CDK Day
All Things Open
October, 15th-17th, Raleigh Convention Center, Raleigh, North Carolina
I will be attending and speaking at All Things Open, looking at Apache Airflow as an container orchestrator. I will be there with a bunch of fellow AWS colleagues, and I hope to meet some of you there. Check us out at the AWS booth, where you will find me and the other AWS folk throughout the event. Check out the event and sessions/speakers at the official webpage for the event, AllThingsOpen 2023
Open Source India
October 19th-21st, NIMHANS Convention Center, Bengaluru
One of the most important open source events in the region, Open Source India will be welcoming thousands of attendees all to discuss and learn about open source technologies. I will be there too, doing a talk so I would love to meet with any of you who are also planning on attending. Check out more details on their web page, here.
Cortex
Every other Thursday, next one 16th February
The Cortex community call happens every two weeks on Thursday, alternating at 1200 UTC and 1700 UTC. You can check out the GitHub project for more details, go to the Community Meetings section. The community calls keep a rolling doc of previous meetings, so you can catch up on the previous discussions. Check the Cortex Community Meetings Notes for more info.
OpenSearch
Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Stay in touch with open source at AWS
Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen





Top comments (0)