May 22nd, 2023 - Instalment #157
Welcome
Hello and welcome to the AWS open source newsletter, #157. Apologies for the lack of newsletter last week, but hopefully this week will make up for that as we have a bumper selection of great open source content for you. This weeks new projects include repos that help you get OpenEMR up and running ("host-openemr-on-aws-fargate"), two new security related open source projects that you definitely need to check out, ("cedar" and "snapchange"), integration of clickstream analytics using Swift ("clickstream-swift"), deployment of Backstage to serve up access to your AWS resources, ("app-development-for-backstage-io-on-aws"), a tool to help you clean up ecs tasks definitions ("aws-ecs-task-definition-cleanup") and many more.
Also featured this week is content on some of your favourite open source projects, including Cedar, Apache Airflow, MLFlow, Backstage, openEMR, Mail-in-Box, Amazon EMR, Dremio, Apache Kafka, Dask, Apache Spark, Grafana, Cypress, Karpenter, Dagster, Apache Hudi, Redis, JupyterLab, AWS Distro for OpenTelemetry, OpenSearch and many more!
Coming Soon
Scoutflo is a new commercial open source marketplace that is launching very soon that readers of this newsletter might be interested in. I spoke with Atharva Bondre of Scoutflo a while back, and I am excited about what they are hoping to do. This will make it easy for folk to consume and deploy their favourite open source technologies, but also provide a channel to generate income. Watch this space, they are launching very soon and we will try and have them on the Build on Open Source show so they can dive deeper into this service.
OpenSearchCon Call for Papers
The call for presentations for OpenSearchCon 2023 is now live and looking for your submissions against three tracks: Search, Community, and Analytics, Security, and Observability. Check out the announcement, Call for presentations: Bring your ideas to OpenSearchCon 2023!
Feedback
Please please please take 1 minute to complete this short survey and bask in the warmth of having helped improve how we support open source.
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Peter Mescalchin, Mike Hicks, Gabriel Manor, Swapnil Bhartiya, Damian Schenkelman, Emina Torlak, Uma Ramadoss, Mark Richman, Paolo Di Francesco, Chris Fregly, Irshad Buchh, Cory Duplantis, Joab Jackson, Romaric Philogène, Parnab Basak and Vishal Vijayvargiya.
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution.
Tools
snapchange
snapchange provides the ability to load a raw memory dump and register state into a KVM virtual machine (VM) for execution. At a point in execution, this VM can be reset to its initial state by resetting the dirty pages found by KVM or pages manually dirtied by a fuzzer. The README contains essential reading on how to get started, and the repo contains tutorials to help. Check out the Videos section down below for more info related to snapchange.
cedar
cedar repository contains source code of the Rust crates that implement the Cedar policy language. Cedar is a language for writing and enforcing authorisation policies in your applications. Using Cedar, you can write policies that specify your applications' fine-grained permissions. Your applications then authorise access requests by calling Cedar's authorisation engine. Because Cedar policies are separate from application code, they can be independently authored, updated, analysed, and audited. You can use Cedar's validator to check that Cedar policies are consistent with a declared schema which defines your application's authorisation model. We have lots of Cedar related content in this weeks newsletter, so check those out further below.
cloud-radar
cloud-radar is an open source python module (from the awesomely named DontShaveTheYak) that allows testing of Cloudformation Templates/Stacks using Python. Check out this Reddit thread for more background an example. The repo itself has a good README so you should be able to get going pretty swiftly. Very nice project indeed.
aws-ecs-task-definition-cleanup
aws-ecs-task-definition-cleanup is an open source tool from Peter Mescalchin that provides a Python CLI utility to help maintain legacy AWS ECS task definitions in bulk. From his post on Reddit:
With the (fairly) recent ability to finally being able to delete inactive ECS task definitions - I felt inspired to put together a little utility to both deregister (ACTIVE -> INACTIVE) task definitions no longer in use by an ECS cluster and also bulk delete INACTIVE task definitions.
Can take a little while to get the job done with a large backlog of inactive definitions (e.g. the delete definition API only allows a maximum of 10 task definitions ARNs to be submitted at once) - but will handle retry/backoff if API throttling is encountered to get the job done.
Used this to clean up several thousand deprecated definitions from a few AWS accounts/regions to throw away much unused cruft.
discord_bot_lambda
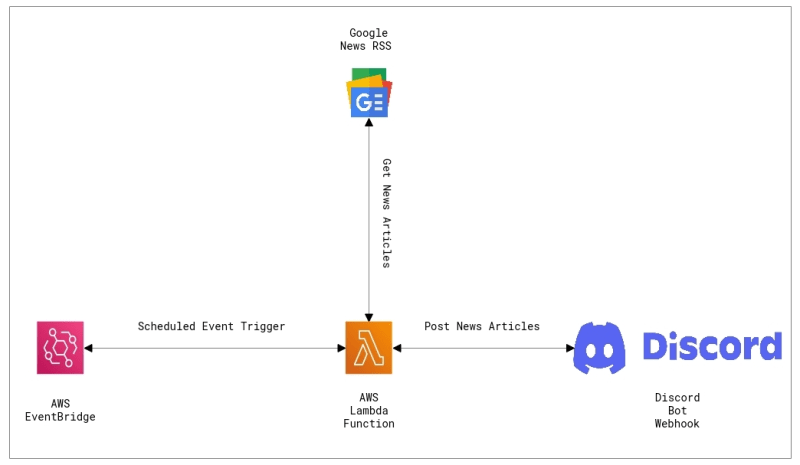
discord_bot_lambda this tool from Gokul G should be handy for any Discord users. The repo is a Discord Bot(webhook) written in Go and hosted as an AWS Lambda Function. This application is designed to call the Google News RSS feed and post latest news articles to the discord bot based on given search query. We can automate the daily articles posting by setting up AWS EventBridge to schedule event triggers targeting the lambda function.
clickstream-swift
clickstream-swift Clickstream iOS SDK can help you easily report in-app events on iOS. After the event is reported, statistics and analysis of specific scenario data can be completed on AWS Clickstream solution.
https://github.com/awslabs/clickstream-swift
app-development-for-backstage-io-on-aws
app-development-for-backstage-io-on-aws provides a new developer experience to simplify the use and consumption of AWS services while minimising required expertise in cloud infrastructure technologies. Built on the Backstage open platform, this solution makes the AWS cloud more accessible to Application Developers allowing them to focus on building application logic and delivering business value.

Make sure you check out these awesome YouTube videos that support this repo.
Demos, Samples, Solutions and Workshops
aws-text-to-speech
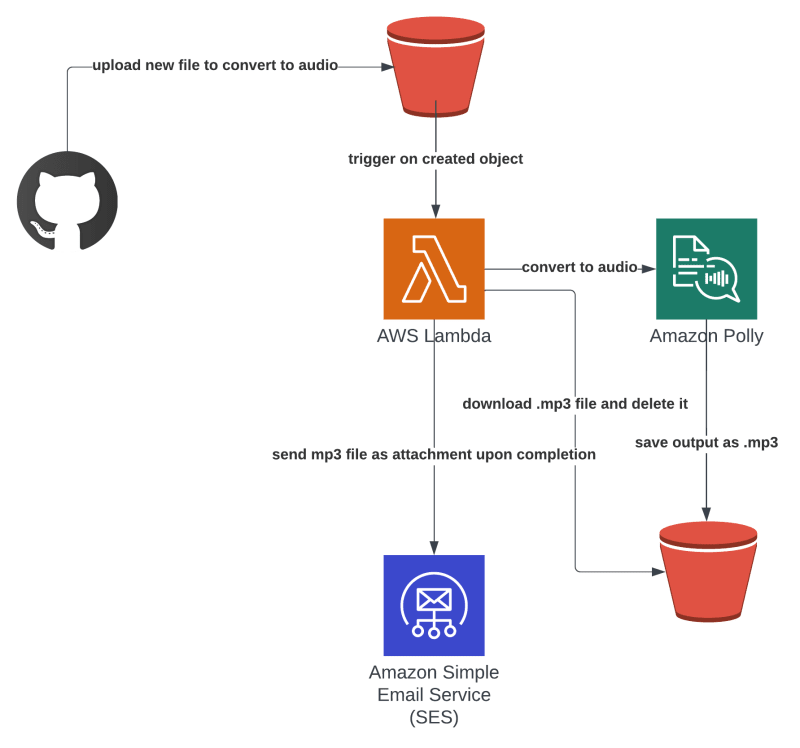
aws-text-to-speech is from AWS Community Builder (and Build on Open Source guest) Ran Isenberg, and this repository deploys a serverless service that takes text files uploaded to a bucket, converts them to an MP3 and sends the output to an email address
host-openemr-on-aws-fargate
host-openemr-on-aws-fargate this repo provides a way to deploy OpenEMR, a popular Electronic Health and Medical Practice management solution (yeah, I also thought it was the other EMR too!).

aws-opensource-mailserver
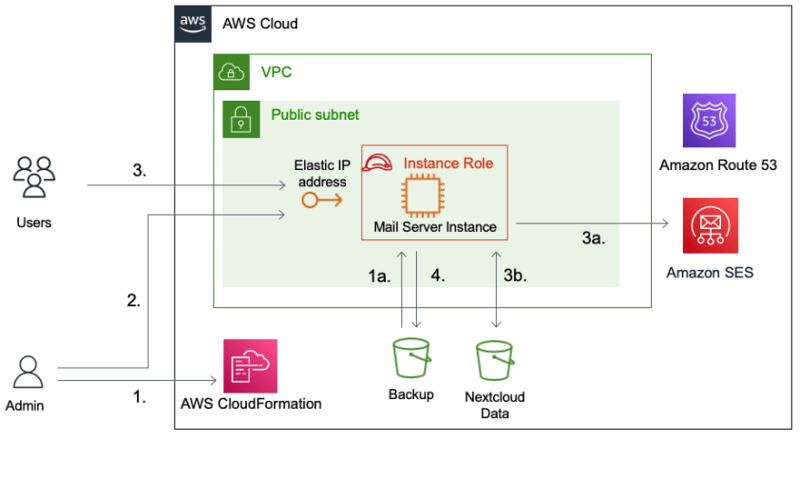
aws-opensource-mailserver provides code to help you deploy a number of open source projects on AWS using Mail-in-a-box, that sits on top of popular open source mail server packages such as Postfix for SMTP and Dovecot for IMAP, and integrates Nextcloud for calendar, contacts, and file sharing. You can follow the post, Fully Automated Deployment of an Open Source Mail Server on AWS, which provides a detailed guide on how you can use this to get your own mail server up and running.
AWS and Community blog posts
Cedar
One of the big announcements at the Open Source Summit a few weeks ago was Cedar. Cedar is an open source language and software development kit (SDK) for writing and enforcing authorisation policies for your applications. This was launched a few weeks back at the North American Open Source Summit, and has been generating a lot of buzz and interest among developers. Mike Hicks has put together the official launch post, Using Open Source Cedar to Write and Enforce Custom Authorization Policies [hands on], where you can dive deeper and look at how this works. The post looks at one of the example apps in the project repo, TinyTodo, that will give you a nice starting point for your own adventures with Cedar. Please do share your thoughts on this project and on how you might be wanting to use it.

Mike also put together this post, How we built Cedar with automated reasoning and differential testing which takes a look behind the scenes as to how the new development process used by Cedar.

Swapnil Bhartiya of TFiR: Let’s Talk, catches up with Gabriel Manor, Director of DevRel at Permit.io, while at Open Source Summit in Vancouver, discussing Cedar and the current trends in policy and access control. Gabriel goes on to explain how Permit.io is helping customers deploy policies at scale using Cedar and other policy engines.
Finally, check out this podcast where host Damian Schenkelman talks to Emina Torlak, Senior Principal Applied Scientist at AWS, about the intricacies of software authorisation, policies, and the Cedar policy language.
Apache Airflow
A common question I get asked when I talk about Apache Airflow, and specifically Managed Workflows for Apache Airflow (MWAA) is how can you "pause" your MWAA environments. Luckily, we have this fantastic post, Automating stopping and starting Amazon MWAA environments to reduce cost, where Uma Ramadoss provides a detailed, hands on guide on how you can build a solution that enables you to do just this. Why would you want to do this? One reason is cost savings, with the potential cost savings of running your MWAA environment for only 12 hours on weekdays are significant. The example shows how you can save up to 65% of your monthly costs by choosing this option. This makes it an attractive solution for organisations that are looking to reduce cost while maintaining a high level of performance. [hands on]
Following that we have the post, Amazon DynamoDB Value Sensor for Apache Airflow, where Mark Richman walks you through a recent new Apache Airflow operator he developed. The post looks at some of the typical use cases where this operator might be helpful, and provides sample code to get you in the mood! [hands on]
I have written about MWAA startup scripts before, so I was really excited to read this post, What’s new with Amazon MWAA support for startup scripts. Parnab Basak and Vishal Vijayvargiya have put together a nice summary of how you can get started with this feature, a look at some of the potential use cases (let us know how you are using this feature), how it works, and importantly, some of the key considerations. Very nice.
Finally, I have put together a detailed tutorial on how to automate the provisioning and deployment of workflows using MWAA in, Automate the Provisioning of Your Apache Airflow Environments. Let me know how you get on and whether you encounter any issues or improvements you would like me to add.

MLflow
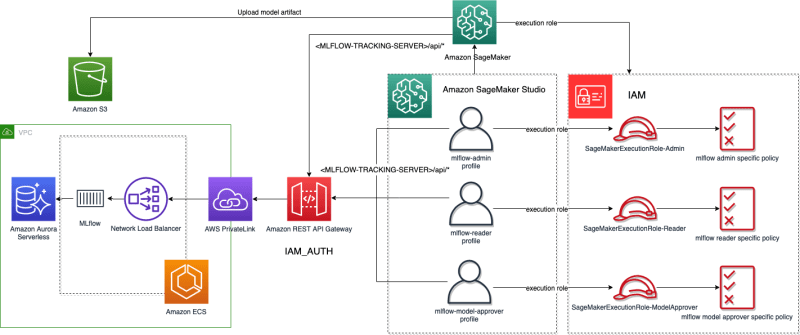
MLflow is an open source platform to manage the ML lifecycle, including experimentation, reproducibility, deployment, and a central model registry. In the post, Securing MLflow in AWS: Fine-grained access control with AWS native services, Paolo Di Francesco, Chris Fregly, and Irshad Buchh collaborate on this follow up post that shows how you can implement the access control outside of the MLflow server, offloading authentication and authorisation tasks to Amazon API Gateway, where we implement fine-grained access control mechanisms at the resource level using Identity and Access Management (IAM). [hands on]
Big Data, Small Data, but open source data posts and quick reads
- Dive deep into AWS Glue 4.0 for Apache Spark explores features of AWS Glue 4.0 which includes many upgrades, such as the new optimised Apache Spark 3.3.0 runtime, Python 3.10 support, and a new enhanced Amazon Redshift connector In this post, we discuss the main benefits that this new AWS Glue version brings and how it can help you build better data integration pipelines.
- Create an ETL Pipeline with Amazon EMR and Apache Spark a new tutorial from my colleague Suman, that helps you build an Extract, Transform, Load (ETL) pipeline for batch processing using Amazon EMR and Apache Spark [hands on]

- Build efficient, cross-Regional, I/O-intensive workloads with Dask on AWS shows you how to deploy a solution that extends Dask’s functionality to work inter-Regionally across Amazon’s global network [hands on]
- Federated query support for Amazon Aurora PostgreSQL and Amazon RDS for PostgreSQL – Part 2 a follow on post that demonstrates the foreign data wrappers (FDW) extensions which lets you use your Amazon RDS for PostgreSQL database instance to query MySQL-compatible engines [hands on]
- Stream data with Amazon MSK Connect using an open-source JDBC connector is a solution to stream data from Amazon Relation Database Service (Amazon RDS) for MySQL to an MSK cluster in real time by configuring and deploying a connector using Amazon MSK Connect [hands on]

- Perform Amazon Aurora PostgreSQL minor version upgrades with minimal downtime via minor version update improvements looks at a series of improvements to the minor version update process that allow for reduced downtime and fewer disruptions to your workloads
- Migrate generated columns to PostgreSQL using AWS Database Migration Service explains Amazon Database Migration Accelerator’s (DMA) approach to migrate generated columns to PostgreSQL implementations, such as Amazon RDS for PostgreSQL or Amazon Aurora PostgreSQL-Compatible Edition [hands on]

- Automate benchmark tests for Amazon Aurora PostgreSQL – Part 2 provides a solution to automate and scale database benchmarks on Amazon Aurora PostgreSQL Serverless v2 using AWS CloudFormation and Systems Manager [hands on]
- Accelerate Business Changes with Apache Iceberg on Dremio and Amazon EMR Serverless looks at how you can leverage Apache Iceberg capabilities with Dremio and Amazon EMR Serverless to scale your business by keeping up with various changes to your data and analytics portfolio
Other posts and quick reads
- Visualize and gain insights into your VPC Flow logs with Amazon Managed Grafana is a really nice post that shows you how to query CloudWatch logs and metrics from Amazon Managed Grafana workspace to build visual insights from your VPC logs [hands on]
- Automate Testing with Authentication using AWS Amplify and Cypress details configuration and strategies using Cypress to test applications built using Amplify and React, and how to run Cypress test suites with AWS Amplify Hosting [hands on]
- How Sentra manages data workflows using Amazon EKS, Dagster, and Karpenter to maximize cost-efficiency with minimal operational overhead explores some great ways to optimise how you can run Dagster, a new open-source big-data orchestration framework, to run efficient, scalable, and sophisticated workflows that require dependency and stage management
- Building Production-Grade Kubernetes Clusters with Amazon EKS Anywhere on Nutanix show you how to build a production-grade Kubernetes cluster with EKS-A on Nutanix

- Fleet Provisioning for Embedded Linux Devices with AWS IoT Greengrass is really great post with supporting code and video walk throughs on how you can build a Raspberry Pi Yocto image with Greengrass with Fleet Provisioning Plugin

Quick updates
OpenSearch
OpenSearch integration with Apache Spark via OpenSearch-Hadook is now officially available. Check out the release notes for more details.
Apache Hudi
Apache Hudi is an open-source data management framework used to simplify incremental data processing in S3 data lakes. Hudi provides record-level data processing that can help you simplify development of Change Data Capture (CDC) pipelines, comply with GDPR-driven updates and deletions, and better manage streaming data from sensors or devices that require data insertion and event updates. The 0.12.2 release includes support for Metadata Tables which are designed to eliminate the requirement for the “list files” operation in order to better support efficient scaling over larger data sets. The Metadata Table will instead proactively maintain the list of files and remove the need for recursive file listing operations to avoid running into request limits in the case of storage systems like Amazon S3.
You can now use Amazon Athena to query tables created with Apache Hudi 0.12.2 which includes support for improved scalability of queries accessing data sets in Amazon S3 data lake. The updated integration enables you to use Athena to query Hudi 0.12.2 tables managed via Amazon EMR, Apache Spark, Apache Hive or other compatible services.
Linux
Patch Manager, a capability of AWS Systems Manager, now supports patch deployments for instances running Alma Linux versions 8.3-8.7, 9.0-9.1 and Ubuntu 22.04. Patch Manager enables you to automatically patch nodes with both security related and other types of updates across your infrastructure.
AWS Distro for OpenTelemetry
Now generally available is the tail sampling processor and the group-by-trace processor in the AWS Distro for OpenTelemetry (ADOT) collector. ADOT is a secure, production-ready, AWS supported distribution of the OpenTelemetry project. With this release, customers can use the ADOT collector for advanced distributed trace sampling use cases.
Customers can now apply tail sampling for traces with the ADOT collector. Sampling of traces allows customers to control the volume of traces ingest in service such as AWS X-Ray and can help reduce costs. Tail sampling enables customers to make the sampling decision when all of the trace’s spans are completed. Due to this, customers can define sampling policies such as “ingest 100% of all error cases and 5% of all success cases”. With tail sampling, customers can achieve better collector load characteristics, induce lower compute resource usage, and reduce the costs of storing traces in a distributed tracing backend such as AWS X-Ray or Amazon OpenSearch.
JupyterLab
Data scientists can now use CodeWhisperer for no additional charge to generate real-time code suggestions for Python notebooks in JupyterLab and Amazon SageMaker Studio. With CodeWhisperer, you can write a comment in natural language that outlines a specific coding task in English and CodeWhisperer will recommend one or more code snippets directly in the Notebook that can accomplish the task. With the CodeWhisperer extension, SageMaker Studio and JupyterLab users will be able to quickly develop code in their Python notebook to accelerate data analysis.
Redis
Amazon MemoryDB for Redis now supports Redis 7. This release brings several new features to MemoryDB:
- Redis Functions: MemoryDB adds support for Redis Functions, and provides a managed experience enabling developers to execute LUA scripts with application logic durably stored on the MemoryDB cluster.
- ACL improvements: MemoryDB adds support for the next version of Redis Access Control Lists (ACLs). With MemoryDB, clients can now specify multiple sets of permissions on specific keys or keyspaces in Redis.
- Sharded Pub/Sub: MemoryDB now gives you the ability to run Redis’ Pub/Sub functionality in a sharded way. With MemoryDB, channels are bound to a shard in the MemoryDB cluster, eliminating the need to propagate channel information across shards resulting in improved scalability.
- Enhanced I/O Multiplexing: MemoryDB now includes enhanced I/O multiplexing, which delivers significant improvements to throughput and latency at scale. As an example, when using r6g.4xlarge node and running 5200 concurrent clients, you can achieve up to 46% increased throughput (read and write operations per second) and up to 21% decreased P99 latency, compared with MemoryDB for Redis 6.
Videos of the week
Snapchange
Also announced at the Open Source Summit a few weeks ago, Snapchange is a fuzzing framework written in Rust that provides a library of utilities for running the fuzzing process, and can controlled by the command line. In this video, Joab Jackson talks with AWS Security Engineer Cory Duplantis about this project and Corey then shows you it in action.
Check out the launch post from Cory, Announcing Snapchange: An Open Source KVM-backed Snapshot Fuzzing Framework that provides a detailed guide to the repo and a walk through of how you can use this for your own projects.
Build on Open Source
Hopefully some of you were able to catch Derek and Abhishek speaking with Romaric Philogène, CEO of Qovery, as he walked you through Replibyte. If you missed it, don't worry, you can catch it on replay here.
For those unfamiliar with this show, Build on Open Source is where we go over this newsletter and then invite special guests to dive deep into their open source project. Expect plenty of code, demos and hopefully laughs. We have put together a playlist so that you can easily access all (eight) of the episodes of the Build on Open Source show. Build on Open Source playlist
Events for your diary
If you are planning any events in 2023, either virtual, in person, or hybrid, get in touch as I would love to share details of your event with readers.
Intelligent Document Processing with AWS and Open Source with Hugging Face
AWS Office Zurich, May 23rd 8am - 2pm CET
For readers who are based in Zurich, make sure you check out this event. The goal of this in-person event is to learn and share experience on how to get insights from documents, and simplify workflows using document processing and the power of open source. There is a great line up of speakers and an excellent agenda.
Find out more and reserve your space by heading over to, Intelligent Document Processing with AWS and Open Source with Hugging Face
Open source Table Formats with AWS Glue and Amazon EMR
Online, 6th June 5PM UK time
Curious about Transactional Data Lakes? Come join our AWS experts as we take you through the most popular open source table formats, how these table formats can help you enable a modern data strategy, and how to build on these formats with Amazon EMR and AWS Glue. In this session, we'll cover some of the key differences between these different table formats, help you decide which table format may be the best fit for your workloads, and show you how to start building today.
You can join via YouTube live here
London Open Source Data Infrastructure Meetup
Huckletree Shoreditch, 6:30PM - 9:30PM
As part of London Tech Week Aiven are co-hosting the 'London Open Source Data Infrastructure Meetup' on the 14th of June. This event is in collaboration with Hugh Evans from Daemon the 'AI and Deep Learning for Enterprise' group. The speaker panel includes Ricardo Sueiras from Amazon Web Services (AWS) discussing the wonders of Apache Airflow, Davies Oludare from Confluent shedding light on the intricate world of Kafka, and Ed Shee from Seldon breaking down the nuances of ML-powered summarisation.
Spaces are limited, so make sure you reserve your spot by checking and out the meetup page
Open Source Festival
Lagos, Nigeria - June 15th-17th
An established and essential event for all open source developers, Open Source Festival promises to be even bigger and better than previous years. I feel very privileged to have spoken at this event in 2020, and so make sure you check this out if you are in the region or perhaps if you are maybe looking to sponsor an open source event, then maybe this is the one you should check out.
Check out more on their homepage, Open Source Festival
Cortex
Every other Thursday, next one 16th February
The Cortex community call happens every two weeks on Thursday, alternating at 1200 UTC and 1700 UTC. You can check out the GitHub project for more details, go to the Community Meetings section. The community calls keep a rolling doc of previous meetings, so you can catch up on the previous discussions. Check the Cortex Community Meetings Notes for more info.
OpenSearch
Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Stay in touch with open source at AWS
Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen





Top comments (0)