
When you decide to go serverless, be it a personal decision or enterprise-wide, you're signing up to be a forever student. Modern technology moves fast and keeping up with all the new features, services, and offerings week after week is something that you need to do to stay effective. Cloud vendors are continuously releasing higher and higher abstractions and integrations that make your job as a builder easier. So rather than reinventing the wheel and building something you'll have to maintain, if you keep up with the new releases, someone may have already done that for you and is offering to maintain it themselves.
Such is the case with Neon, a serverless Postgres service, that went generally available on April 15. Congrats Nikita Shamgunov and team on the launch. When I saw the announcement, I knew I had to try it out for myself and report back with my findings.
I host a weekly show with Andres Moreno for the Believe in Serverless community called Null Check. Andres and I find newly released services or buzzing features and try them out ourselves live on-air for a true "this is what it is" experience. We try to build some silly stuff for a little bit of fun while we're at it.
Last week, we did a full assessment on Neon, looking at pricing, developer experience, elasticity, and serverless-ness (we're going to pretend that's a word). Let's go over what we found.
Pricing
Neon has two pricing metrics - storage and compute, which feels spot-on for a managed database service. On top of the two pricing metrics, there are four plans to choose from ranging from free tier to enterprise.
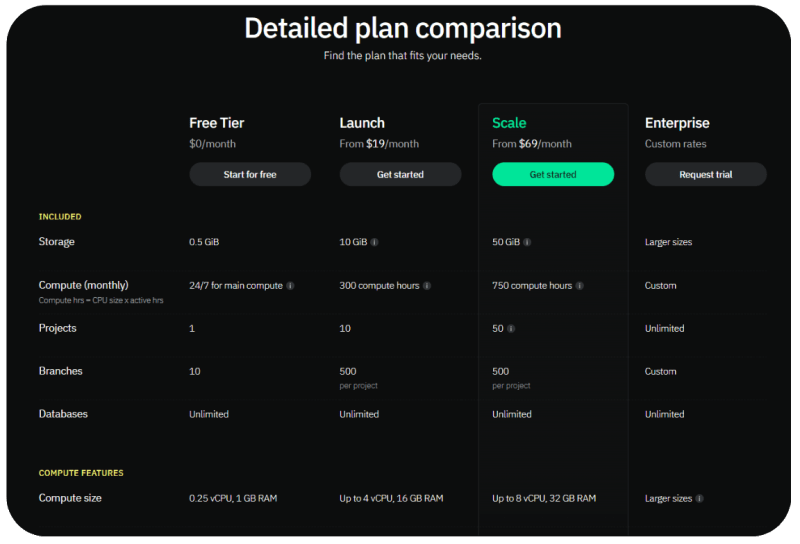
Storage is a metric we should all be familiar with. It refers to the amount of data you're storing inside of Neon. Each plan includes a certain amount of data, and if you exceed it you pay for the overage. The overage cost decreases the higher the plan. Meaning it's more per GB of data on the Free tier than it is at the Scale tier.
Compute, on the other hand, is similar to what we see in other serverless services, but also kind of different. It's the same in that you're charged for the amount of compute in hours x vCPUs consumed, but it's different from other managed DB services in that you're charged for this time while queries/operations are running. With something like DynamoDB, you're charged for read and write capacity units - which are determined by the size of the data you're handling. With Neon, it's all about the effort the machines are putting in with seemingly no direct charge for the amount of data handled.
Developer experience
Developer experience (DX) refers to a lot of things. Onboarding, ease of use, clearness of documentation, intuitiveness, etc... all play a role when talking about how a developer uses your service. Andres and I tried to see how far we could get without needing to dive into the docs - which is a great indicator of how easy and intuitive the experience is.
We started in the console, where a wizard guided us through setting up our first project and database. This was a simple form that required us to come up with a name for everything and select a region to use. After that, it was set up and ready to use! We were even presented with a quickstart for getting connected to the DB we just created.

In this popup, there was a language picker that allowed us to select from psql, Next.js, Primsa, Node.js, Django, Go, and several others. As far as quickstarts go, this one was fast. I put the provided code as-is in a JavaScript file and was able to connect and query data within seconds.
Since the database was created void of tables and data, my query didn't do anything 😅 so we used the integrated SQL editor in the console to create tables and the Neon CLI to insert data in bulk from a csv. Overall, we went from idea to queryable data inside of tables in less than 5 minutes!
The Neon SDK was easy to use as well. Granted all I did was use raw SQL with the SDK, which is ripe for a SQL injection attack, it still did exactly what I needed it to do without needing to go digging through docs for 30 minutes. In fact, I could have easily used the industry standard node-postgres package instead of the one from Neon and communicated with my database the same way I've always done. This means if I migrate from another service to this one, all I'd need to do is update the connection string!
Overall, I was delighted at how easy the developer experience was to get started with this service. It also feels like a breeze to maintain.
Elasticity
A service is only as good as its elasticity. If your app has more traffic than a service can handle you're forced to either throttle requests or go with a service that can handle it. So we ran some tests to see how Neon could scale with traffic spikes.
For this benchmark, we ran two tests: one for heavy reads and another for heavy writes. To run the benchmark, we built a small web server inside of a Lambda function and created a function url for public access to the internet. We created an endpoint that would do a large read, joining across several tables and returning several hundred results, and another for a write operation which created a single row in one table.
Then, we used the Postman load generator to push load onto each of these endpoints, running at a sustained 75 requests per second (RPS) for two minutes.

Granted this isn't a ridiculously high load, but keep in mind I was testing out the free tier that has limited compute usage. So 7,500 requests over 2 minutes will have to do. And it did well!
Funnily enough, the only time we were getting errors in this test was when the Lambda function was trying to keep up with scaling. When we sent burst requests out of nowhere, we'd get back 429 - Too Many Request status codes from Lambda as it was scaling up. But neither the write nor the read tests overwhelmed Neon - even at the lowest tier.
From what I can tell, there is a little bit of a cold start when Neon is initiating compute. The documentation says the compute instances wind down after 5 minutes of inactivity in the free tier. Running a large read query on an inactive database resulted in about 800ms round-trip time (RTT) for the endpoint. This included the Lambda cold start as well, so overall not a terrible latency. Subsequent runs dropped to about 350ms.
It appears to me that Neon will cache reads for about 1-2 seconds. After a warm start, running the same query resulted in an 80ms RTT for a couple of seconds, then would spike up to 300ms for a single request, then back down to 80ms again. Given that pattern, I imagine there's built-in caching with a short time-to-live (TTL).
Serverless-ness
Any time something is branded as serverless, I give it a bit of a skeptical eye roll. Depending on who you believe, serverless has no meaning. Rather than thinking about serverless as a "thing" I like to approach it as a set of capabilities:
- Usage-based pricing with no minimums
- No instances to provision or manage
- Always available and reliable
- Instantly ready with a single API call
Given what we've already discussed about Neon, I feel like it checks the boxes on the serverless test. For pricing, we're only paying for what we're using - the amount of data stored in the service and the amount of compute time we're consuming in our read and write operations. There is no minimum cost and it scales linearly with the amount I use it.
It took me a few days to land on my opinion for no instances to provision or manage. There definitely is compute with an on/off status and it's made clearly visible to end users. However, users can't do anything with it. It's managed completely by Neon. If more compute is needed, it is automatically added. I'm not responsible for configuring how it scales, it just does it. I initially didn't like that I was given a peek behind the curtain, but that's really all it is - a peek. I'm not managing anything, Neon is.
Always available and reliable is a big one for serverless. If I need to use it now - by golly I need it now. Even though compute instances start idling after 5 minutes, they're still available at a moments notice when traffic comes in. There are no maintenance windows or planned downtime, so this one is checked as another win in my book.
The onboarding experience for Neon was minimal. I typed in a name for my database and hit the "Go" button and it was immediately available. This feels serverless to me. I don't have to know the amount of traffic I expect or configure auto-scaling groups or decide what operating system I want the compute to run on. Again, this is all managed for me by Neon.
By my count, that makes this service definitely serverless!
Final thoughts
This was a great test of a super cool service. It's nice to see SQL catching up a bit in the serverless game. One of the really cool features I liked about Neon was data branching. They treat database data similar to code in a GitHub repository. You can branch your data and use it in a sandbox environment, like a CI/CD pipeline or a trial run for an ETL job. When you're done with the branch, you can either discard it or merge it back into its parent.
This is a huge capability for any managed database. It simplifies many workflows and provides an easy and instant way to get a snapshot of data. It follows a copy-on-write principle, meaning the data is copied whenever it's modified in your branch. If you're just doing reads it uses a pointer to look at the parent branch data. This helps reduce storage costs and increase availability of data when you branch.
Overall, I think this is a great product and I will be building more with it. It's a nice alternative to something like Aurora Serverless, which has a usage minimum and requires a VPC 😬
If you're into relational databases and are a fan of Postgres, it's worth a shot.
Happy coding!

Top comments (0)