
The reason for writing a post about resiliency and immutable infrastructure originates from the following question recently asked to me:
Just read your comments about building AMIs. Why do you think it is best to do everything on compile time? We decided to work the other way around. We mostly deploy the standard images provided by AWS and do all the customization as post-install config with Ansible.
Compile-time vs. Runtime aka Baking vs. Frying
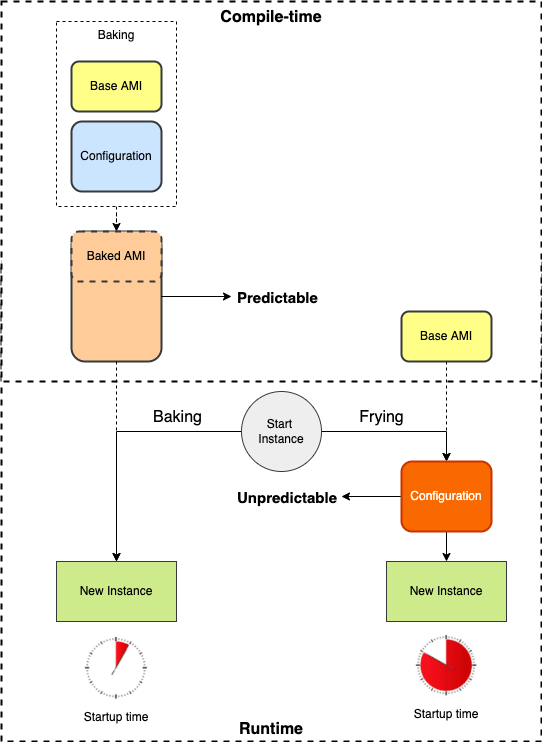
To explain why I prefer doing things at compile-time, we need to look at the possibilities for system provisioning first. Generally, you have two options for system provisioning: bake all configuration into a system before launch (baking) or add configuration after launching, called frying. Often you use a mixture of both, where parts of the system are baked, and parts are fried.
Towards developers, I often compare the concepts of baking and frying with compile-time vs. runtime or early vs. late binding. That terminology is easier to understand for developers because most of them are familiar with those concepts and their benefits and drawbacks.
Mitigating Unpredictably
The main reason to prefer baking, early binding, or compile-time is simple: it avoids unpredictability. Whenever things are being done at runtime or whenever you use late binding, there is a chance of unexpected behavior, potentially breaking things.
For example, imagine the trivial case where yum update is executed in cloud-init on an EC2 Instance. Executing simple code while booting can potentially break because of unpredictable behavior. While it can look like a good idea to run yum update during initialization to keep package versions evergreen. It will become clear it wasn't when you end up without healthy instances Sunday at 8 am, just because some yum dependency was temporarily unavailable. 😅
Need for Speed
Besides stability, there's a second benefit of baking: speed. Replacement and scale-out events will likely finish faster using baked artifacts because those require fewer steps during startup.
Especially in the case of scaling out, velocity is critical. When scaling is slow, there's a bigger chance to overload a service until resources can't come up anymore. Think about premature starvation due to resource exhaustion and fail fast whenever scaling is involved. Keep in mind: a pre-built immutable artifact always wins the race to spin up over a post-build playbook.
Immutable Infrastructure
Doing everything at compile-time ideally results in what is called "Immutable infrastructure." If you are not familiar with the concept or you want a quick refresher. I recommend first reading Martin Fowler's Immutable Server. Drilling down further from that article will bring you to the PhoenixServer, an interesting concept linked to immutable infrastructure.
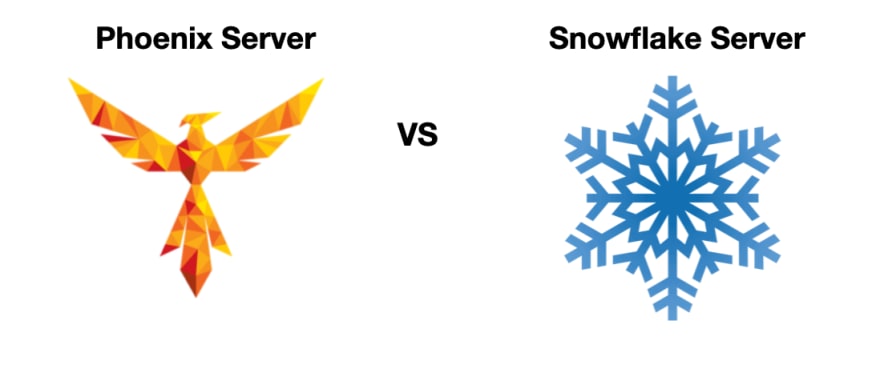
It is a good idea to virtually burn down your servers at regular intervals. A server should be like a phoenix, regularly rising from the ashes.
Furthermore, I want to emphasize that Snowflake servers are to be avoided. To say it in Martin's words: they're good for a ski resort, bad for a data center. The problem with a snowflake server is that it's difficult to reproduce. Should you run into problems, it's hard to fire up a new server to support the same functionality. New resources that come up need to be exact copies and predictable.
Immutable infrastructure and Infrastructure as Code (IaC)
I repeat myself saying I'm a fan of both Immutable infrastructure and Infrastructure as Code. Assure not to switch things up, Infrastructure as Code can facilitate building Immutable Infrastructure, but it's not a necessity.
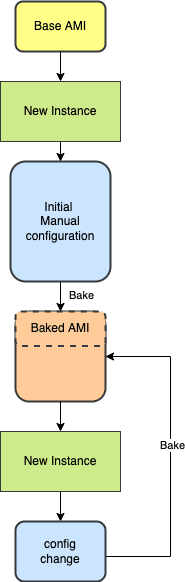
Even in case everything is installed manually without using Infrastructure as Code, Immutable infrastructure can be achieved as long as you "bake" the manual install steps into a machine image. Follow the same baking procedure whenever changes are made. It's maybe not ideal, but sometimes it's the best option if time is a constraint.
In any case, it is crucial to reflect your installation procedure in your Recovery Time Objective (RTO). If a setup or update is time-consuming, this should increase your Recovery Time Objective.
Embrace Chaos (aka Resilience) Engineering
Adopting a new strategy like Immutable Infrastructure requires extra effort and perseverance at the start. Be aware it's easy to fall into old habits. I regularly see people login into instances making changes using some "last resort remote access". That is something you really want to avoid. For that reason, I also advise embracing Chaos Engineering. It will help to get quick feedback about violations against Immutable Infrastructure. By shortening instance lifetime, people will feel the pain of manual changes after a week or two instead of several months, which is far more desirable. 😉 Start using AWS Fault Injector, Chaos Monkey, or simply put a max lifetime on your autoscaling group.
Enjoy and until next time!

Top comments (0)