
The ability to make decisions is dependent on large volumes of historical data. And as machines are getting better at making decisions by understanding the data. Developers need to comprehend why and when to use Machine
This blog explains what ML is and how Distributed ML works. We will be covering Amazon Rekognition, Amazon Lex, Amazon Sagemaker, and Amazon EMR.
Q.What is Machine learning?
Machine learning is a branch of artificial intelligence (AI) and computer science which focuses on the use of data and algorithms to imitate the way that humans learn, gradually improving its accuracy.

An example of low code Machine learning solutions. When considering Machine learning solutions, there are many use cases to consider. Let us consider a few sample use cases,
A. Analyse images and videos
Amazon Rekognition makes it easy to add image and video analysis to your applications. You just provide an image or video to the Amazon Rekognition API, and the service can identify objects, people, text, scenes, and activities. It can detect any inappropriate content as well.
Images are uploaded to the Rekognition service in one of two ways.
- Store the image file within an S3 bucket and then provide the S3 location of the image to the Rekognition service.
- Base64-encode the image data and supply this as an input parameter to the API operation.
Amazon Rekognition provides highly accurate facial analysis, face comparison, and face search capabilities. Some common use cases for using Amazon Rekognition include the following:
- Face-based user verification
- Sentiment and demographic analysis
- Images and stored videos searchable so you can discover objects and scenes that appear within them.
- You can search images, store videos, and stream videos for faces that match those stored in a container known as a face collection.
- Detect adult and violent content in images and stored videos. Developers can filter inappropriate content based on their business needs, using metadata.
- Recognise and extract textual(text and numbers) content from images in different orientations.

Hence we have a separate API to processing videos and video streams. Since, Processing video files need more compute and thus several of the Video API operations are asynchronous.
With the video processing APIs, you always host the video to be processed as a file within an S3 bucket. You then supply the S3 file location as an input parameter to the respective start operation.
With Custom Labels, you can identify the objects and scenes in images and videos that are specific to your business needs. For more information, refer
- https://docs.aws.amazon.com/rekognition/latest/customlabels-dg/what-is.html
- https://aws.amazon.com/rekognition/resources/?nc=sn&loc=6
B. Create a Chatbot using Amazon Lex
Amazon Lex can be used to create and embed chatbots into your applications. Internally, the Amazon Lex service uses the same deep learning engine that powers Amazon Alexa.
Amazon Lex uses automatic speech recognition(ASR) for converting speech to text, and natural language understanding(NLU) to recognise the intent of the text.
The unit of build and deployment within Amazon Lex is the bot itself. Developers can build and deploy multiple bots, each with its own set of skills and behaviours. An intent represents a kind of outcome or action that the bot may perform. A single bot can be composed of multiple intents. For each intent, you need to provide the following attributes:
- Intent name: A descriptive name describing what the intent accomplishes.
- Utterances: One or several phrases the user speaks or types activate the intent.
- Fulfilment process: The method used to complete or fulfil the intent.
Amazon Lex also provides several built-in intents that you can leverage. Each intent may need and have to request extra attributes(slots) from the user to complete this intended outcome. Each slot you define requires you to specify a slot type. You can define and create your custom slot types, or leverage any of the inbuilt slot types.
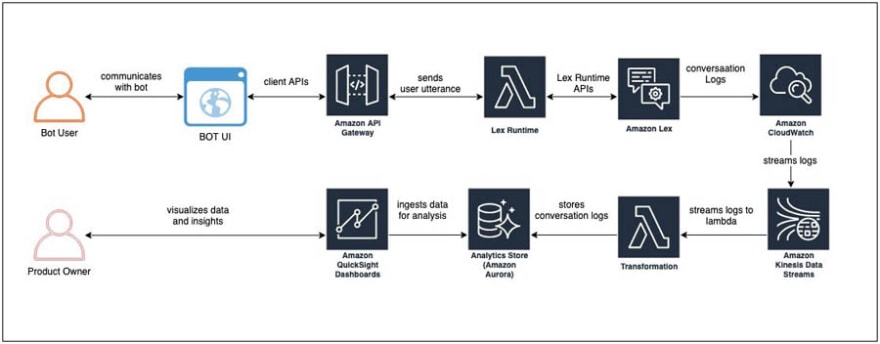
After the deployment of your chatbot, Amazon Lex provides a feature to monitor and track so-called missed utterances. For which Amazon Lex cannot match at runtime against any of the registered utterances.
Amazon Lex can integrate into other messaging platforms using channels. All network connections established to Amazon Lex are done so only using HTTPS. Hence they are encrypted, and can thus be considered secure. Additionally, the Amazon Lex API requires a signature to be calculated and supplied with any API calls.
For more information on various machine learning general use case solutions refer to,
If you don't prefer Low code solution, you should try looking into Sagemaker. They are good for computing and deploying your ML models, as you get AWS compute servers.
Q.What is a Sagemaker?
At its core, sagemaker is a fully managed service that provides the tools to build, train and deploy machine learning models. It has some components in it such as managing notebooks and helping label and train models deploy models with a variety of ways to use endpoints.
SageMaker algorithms are available via container images. Each region that supports SageMaker has its copy of the images. You will begin by retrieving the URI of the container image for the current session's region. You can also utilise your own container images for specific ML algorithms.
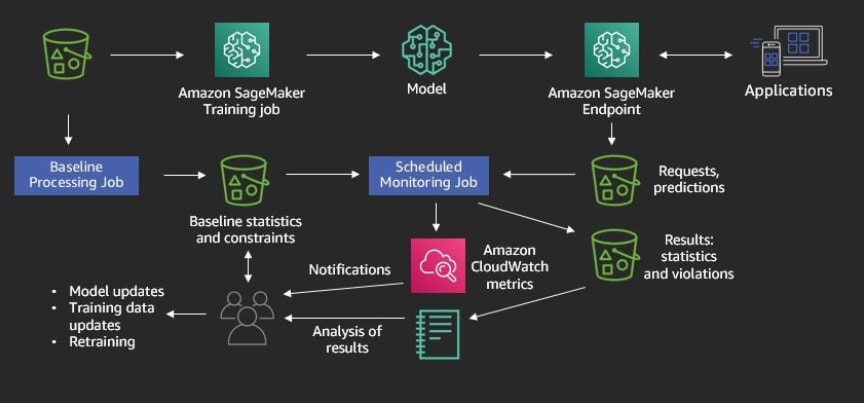
Q.How can we host Sagemaker models?
SageMaker can host models through its hosting services. The model is accessible to the client through a SageMaker endpoint. The Endpoint is accessible over HTTPS and SageMaker Python SDK.
Another way would be using AWS Batch. It manages the processing of large datasets within the limits of specified parameters. When a batch transform job starts, SageMaker initialises compute instances and distributes the inference or pre-processing workload between them.
In Batch Transform, you provide your inference data as an S3 URI and SageMaker will care of downloading it, running the prediction and uploading the results afterwards to S3 again.
Batch Transform partitions the Amazon S3 objects in the input by key and maps Amazon S3 objects to an instance. To split input files into mini-batches you create a batch transform job, set the SplitType parameter value to Line. You can control the size of the mini-batches by using the BatchStrategy and MaxPayloadInMB parameters.
After processing, it creates an output file with the same name and the .out file extension. The batch transforms job stores the output files in the specified location in Amazon S3, such as s3://awsexamplebucket/output/.
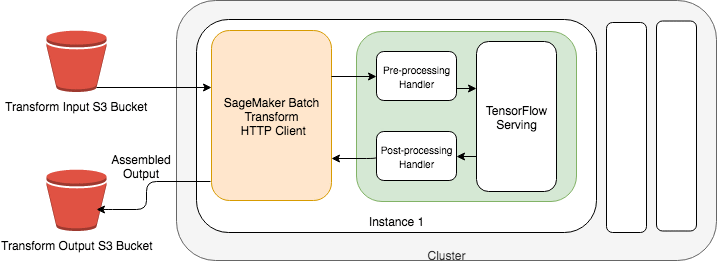
The predictions in an output file are in the same order as the corresponding records in the input file. To combine the results of many output files into a single output file, set the AssembleWith parameter to Line.
For more information refer,
- https://docs.aws.amazon.com/sagemaker/latest/dg/batch-transform.html
- https://docs.aws.amazon.com/sagemaker/latest/dg/how-it-works-batch.html
- https://docs.aws.amazon.com/sagemaker/latest/dg/ex1-model-deployment.html#ex1-batch-transform
Q. What is distributed machine learning?
When machine learning processes have been deployed across a cluster of computing resources. So why use Distributed Machine learning?
- To paralyse your machine learning processing requirements, allowing you to achieve quicker results
- The complexity of the data set (features) may exceed the capabilities of a single node setup.
- The accuracy of a machine learning model can be enhanced by processing more data. This, in turn, is connected back to the large datasets point above.

Apache Spark can provision a cluster of machines, configured in a manner that provides a distributed computing engine. Your datasets are partitioned and spread across the Spark cluster, allowing the cluster to process the data in parallel.
Q. Why Apache Spark?
- Spark contains Resilient Distributed datasets (RDD) which saves time taken in reading and writing operations.
- In-memory computing: In spark, data is stored in the RAM, so it can access the data quickly and speed up the speed of analytics.
- Flexible: Spark supports many languages and allows the developers to write applications in Java, Scala, R or Python.
- Resilient Distributed Datasets(RDD) are designed to handle the failure of any worker node in the cluster.
- Better analytics: Spark has a rich set of SQL queries, machine learning algorithms, complex analytics.
MLlib is Apache Spark's scalable machine learning library. It contains fast and scalable implementations of standard machine learning algorithms.
Q. Why Spark MLLib?
- Spark MLlib is on top of Spark which eases the development of efficient large-scale machine learning algorithms.
- MLlib is easy to deploy and does not need any pre-installation if Hadoop cluster is already installed and running.
- MLlib provides ultimate performance gains (about 10 to 100 times faster than Hadoop and Apache Mahout).
For more information on Apache Spark and MLLib, refer to,
- https://programmerprodigy.code.blog/2022/01/09/introduction-to-apache-spark-sparkql-and-spark-mlib/
Q. How to use Distributed ML on AWS Cloud?
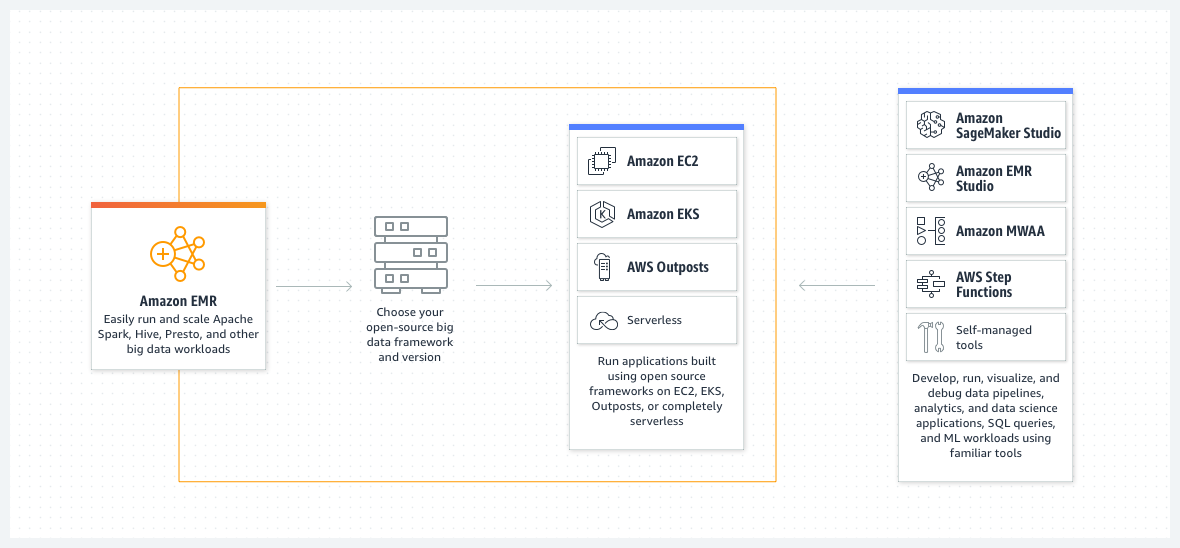
Amazon EMR provides a managed Hadoop frame loop that makes it easy, fast and cost effective to process vast amounts of data.
Amazon EMR can be used to perform: log analysis, web indexing, ETL, financial forecasting, bioinformatics and, machine learning.
Amazon EMR, together with Spark, simplifies the task of cluster and distributed job management. As we can use Amazon EMR at every stage of the Machine Learning pipeline.
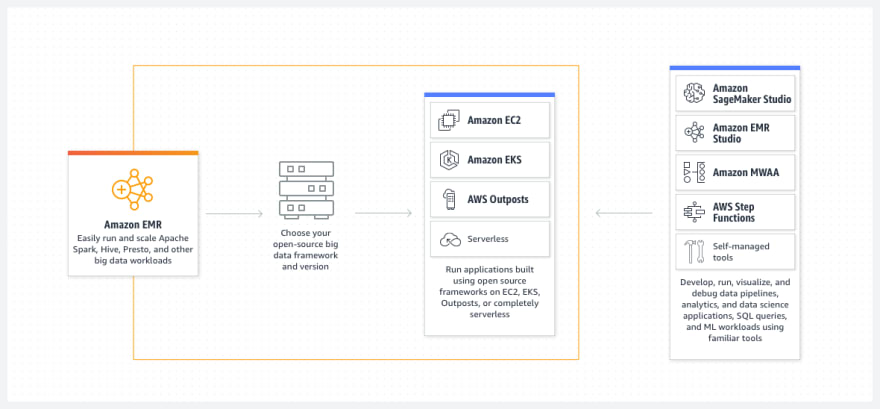
You can customize the installation of applications that complement the core EMR Hadoop application. When you launch an EMR cluster, you need to define and allocate compute resources to three different nodes: Master, Core and Task.
Q. How to Select the right to compute instance?
Choosing a Compute instance completely biased on either price or compute, might not be a good option. As you select a cheaper compute instance, it takes you about 30 mins. But if you would have selected a better compute instance, it takes 10 mins. The second alternative would have been a better alternative economically and time-based.
Some points to remember while choosing CPU and GPU will be
- The CPU time grows proportional to the size of the matrix squared or cubed.
- The GPU time grows almost linearly with the size of the matrix for the sizes used in the experiment. It can add more compute cores to complete the computation in much shorter times than a CPU.
- Sometimes the CPU performs better than GPU for these small sizes. In general, GPU excel for large-scale problems.
- For larger problems, GPUs can offer speedups in the hundreds. For Example, an application used for facial or object detection in an image or a video will need more computing. Hence GPUs might be a better solution.
For more information, feel free to listen to my session on introduction to Algorithms and AWS Sagemaker:
- https://vimeo.com/586886985/7faddfb340
For more information on Sagemaker,
- https://aws.amazon.com/blogs/aws/sagemaker/
After considering all the no/low code solutions and coding solutions. Let's consider a use case,
If you have a relatively simple algorithm with a less diverse data set. Then i would recommend no/low code solution using a centralised compute instance. If your algorithm is complicated, and your data set is diverse. Then i would recommend a distributed machine learning approach.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
Top comments (0)