Business users always format, transform and summarize data to derive insights. Even with data being ETL to Data Warehousing systems; users had to apply additional transformations in BI tools.
As modern enterprises are increasingly adopting Lake House architectures, there is an even greater need to simplify this process for data prep on large data sets that can scale.
AWS Glue DataBrew
AWS Glue DataBrew is a new visual data preparation tool that makes it easy for data analysts and data scientists to clean and normalize data to prepare it for analytics and machine learning.
It allows you to:
- Profile
- Clean and Transform
- Track Lineage
- Orchestrate and Automate
In the remaining sections, I will demonstrate these capabilities using a simple customer segmentation dataset - Link
Data Profiling
First thing we do on a dataset is to profile - either with code or here with a few clicks in Data Brew.
To begin, select the dataset and "Run data profile" button.

This would take us to "Create job" page where we create a "Profile Job" and this will generate summary statistics on our data.
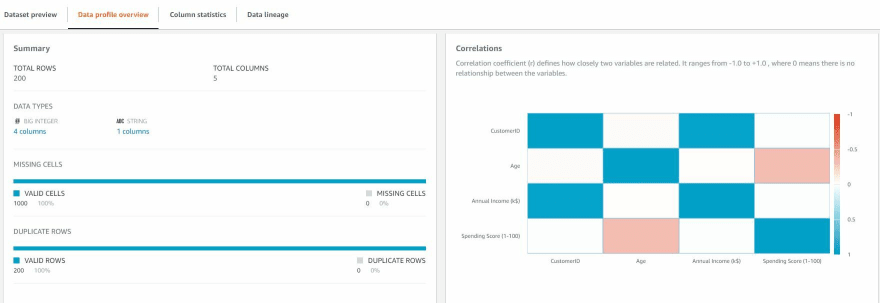
Once Profile job is complete, it provides a profile overview, detailed column statistics and lineage.
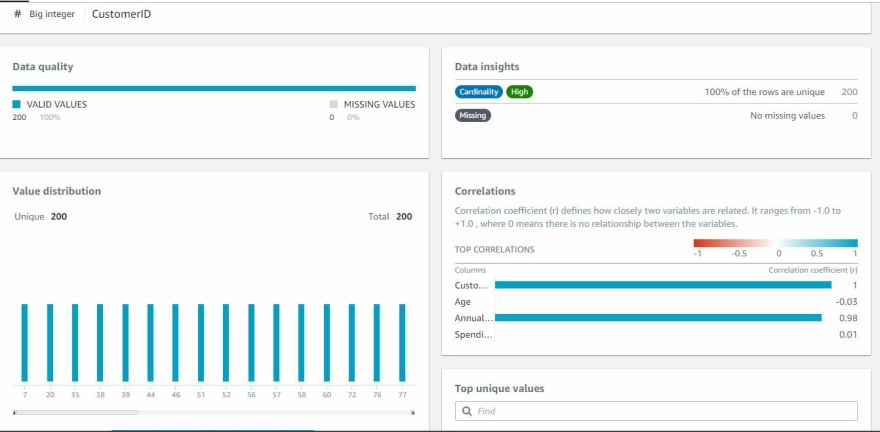
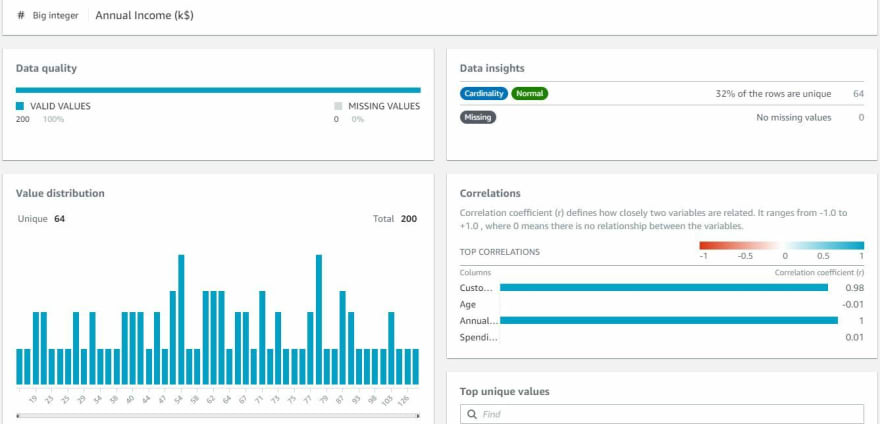
Projects
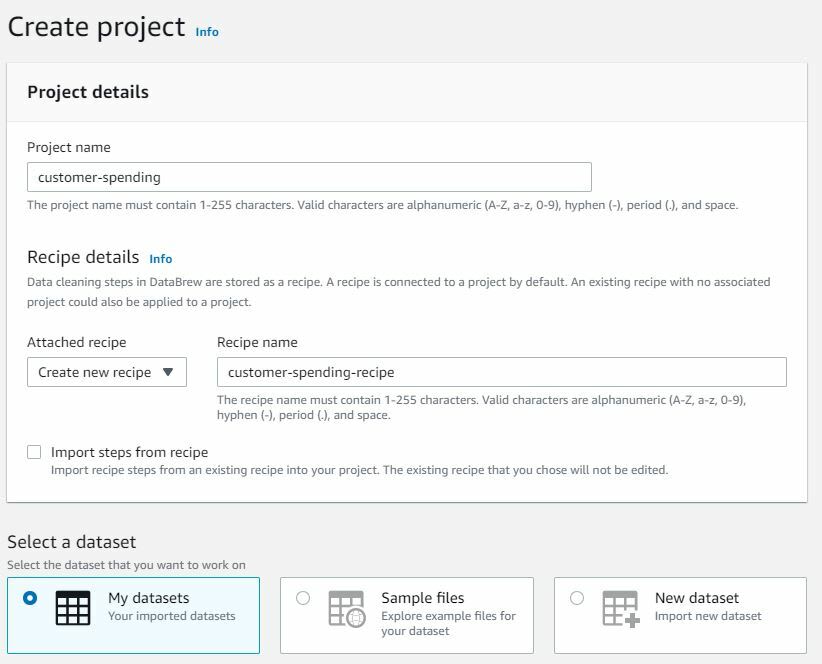
Next, we will transform the data by creating a project on the dataset. We can create Project from the Datasets view by specifying Project Name and Recipe details. For recipe we can either create a new one or use from existing list.

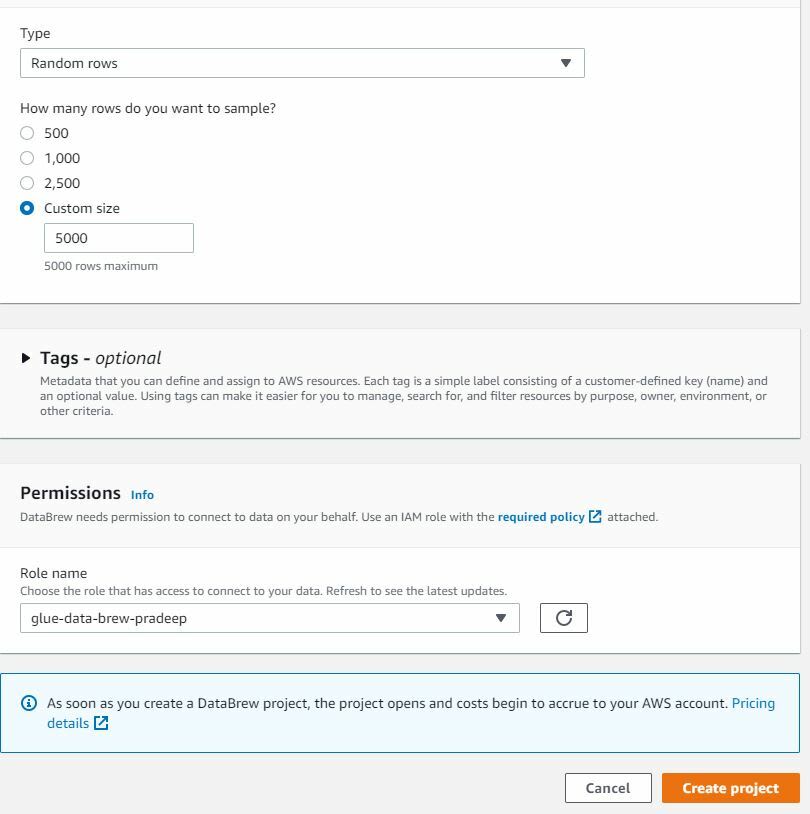
While creating recipes, transforms are done with sample data. For this Project, we will select 5000 random rows.
Project Landing Page
Default view of this page shows us sample rows, distribution and recipe steps.It also shows the available list of transformations that can be done on the dataset.

Schema View-

Transformations steps can be added and together makes a recipe.
DataBrew provides from over 250 built-in transformations to visualize, clean, and normalize your data with an interactive, point-and-click visual interface.
For this dataset, we will create a recipe with two transformations:
- Filter Customers with age greater than equal to 30
- Encode Gender to 'M' or 'F'
1. Filter Customers with age greater than 30
From Filter category > By Condition > Greater than or equal to:

Select the source column and the filter value

Preview shows the result of the step and helps verify the outcome before applying it

2. Encode Gender to 'M' or 'F'
From the clean category > select Replace value or Pattern

Select source column and the value to be replaced
Note - We need two steps here, one for each value to be replaced.
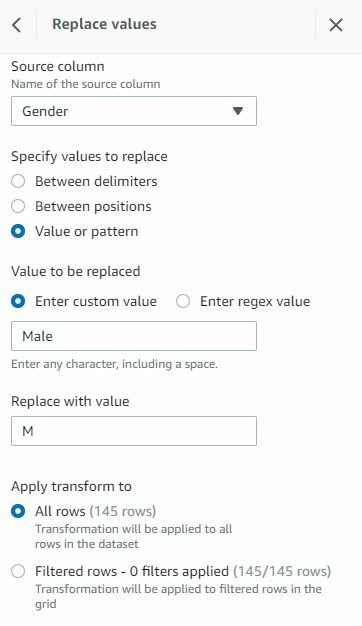
Preview changes and apply

Then, transform the next value
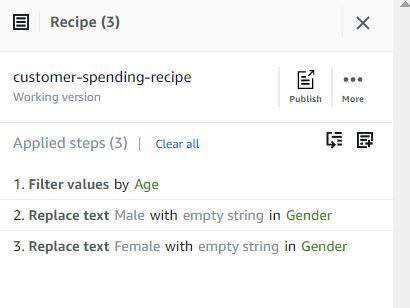
As we are done with all the steps, we are good to publish our recipe:

Jobs
We had earlier created a Profile Job. We will now create a recipe job that will transform the entire dataset.
We will specify the Dataset, Recipe and Output details.
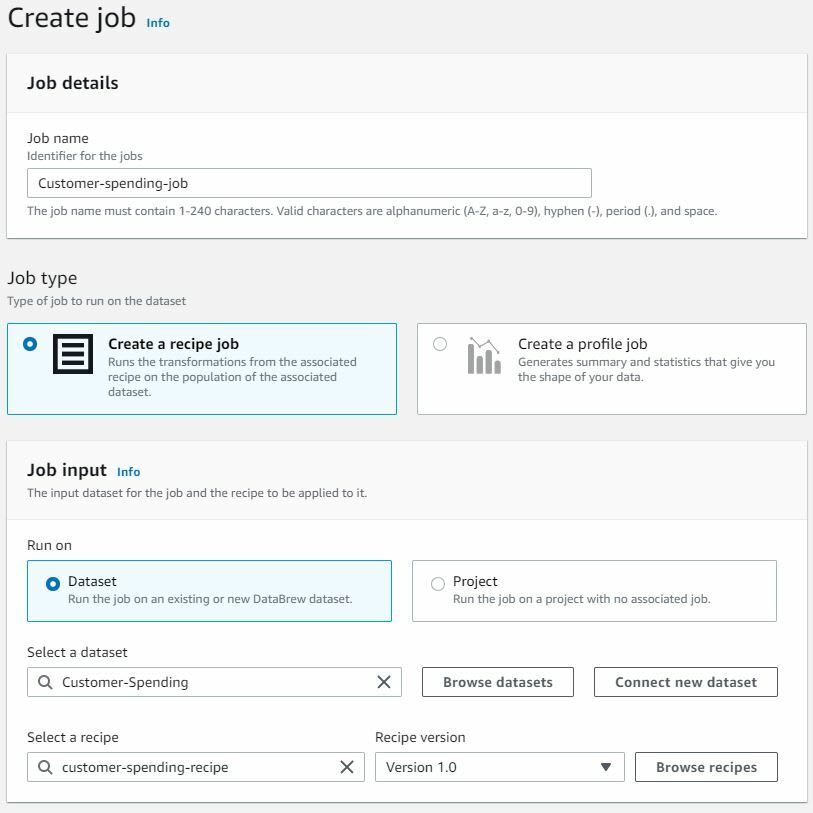
Once job is created, we get the transformed dataset, job run and history details.

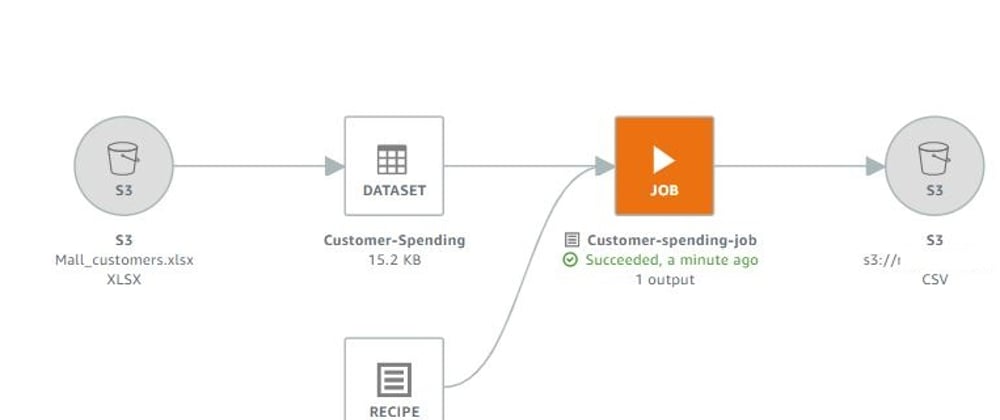
Data Lineage
Lineage shows the various components and their relationships to the output.

Summary
Data Brew provides a powerful abstraction for data preparation. As explained, it fastens and simplifies the Data Prep process allowing Users to focus on the insights and decisions that drives their business.
.




Top comments (4)
Nice. The catch here is the profiler is done for the first 20k rows. What if I have more rows in the dataset? There are many open-source profiler libraries available. What is the specific advantage here?
The best part is its easy to use GUI interface. Profiling done on specific/custom sample - transform data - apply that profile on entire dataset. Earlier it was tough to work through spark or hive to do cleanup - as sampling option and then pushing that on entire dataset was not there very handy.
Thanks @ Pradeep for such a nice presentation for the - still not much known - stuff under Glue umbrella (glue/athena/gluebrew/glue studio)
AWS is choosing best products of hadoop framework and nicely coating the stuff in GUI with lots of enhancement and designing optimal solution.
As I have understood, DataBrew jobs work on entire dataset. We can create either profile or recipe jobs that work on the whole dataset. We select sample data for building the recipes where we can visualize the changes to data as we add steps. But once done we need to use the recipe and create a job. DataBrew integrates - visual GUI data prep, profiler and lineage in one and very well coupled with other aws services
Neat post. My feedback: This is a sweet separation between a data set and a recipe.