Let's dive into SageMaker and take a hands-on look at the tool.

So in photo, you're seeing how SageMaker looks as logged into, through Amazon Web Services. If you don't know how to get here, check out the services button in the top left and look around for SageMaker you also be able to search for it and click it.
This page shows a surprisingly similar workflow to what we just discussed in the middle of it. Of course, there's some options on the left but the focus is purely in the middle, you could see a series of tools used to help achieve all of the previous machine learning workflow steps we just discussed.
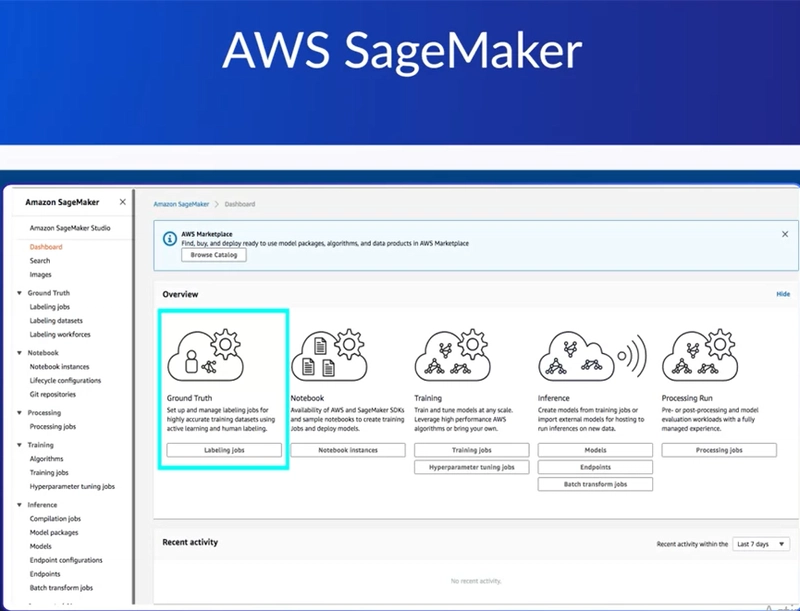
Starting at the left, you see Ground Truth. Data preparation really is the foundation of any machine learning project. So much so that Amazon even labeled its data preparation stage, Ground Truth.
Now, if you ever tried to label or create data sets before, you've probably had some success if it's small. If it's a small amount of data that you understand very well you're often able to just handle it yourself. But as you start to move into the thousands or millions of records or perhaps there's many images that need custom annotations this becomes an unmanageable task.
Now you'll have a few choices of course. Your company could scale and hire some temporary help, but Amazon offers a semi-automated, semi-human driven solution through Ground Truth. This section of the platform actually allows you to annotate your data sets by creating workflows. And these workflows could either use some of the previously mentioned machine learning models.
So in this case, Amazon SageMaker as a platform is actually referencing applications or it actually has a way to route you through to people who have been trained on how to label data what they call their human workforce, and completely human intelligence tasks. So regardless, if you want to just have some help yourself maybe have some machine learning help with a pre-trained framework or employ other people, this is a good option for handling any of those tasks.
Clicking into Ground Truth, the first thing you're confronted with is a plethora of options about how you want to label your data.

At the top, you see a dropdown that allows you to select if it's text or image and such, but within each type of data, you have different types of labeling you can do. And the type of labeling really can make or break your solution.

So, first things first is whether it's whole image classification or bounded classification.
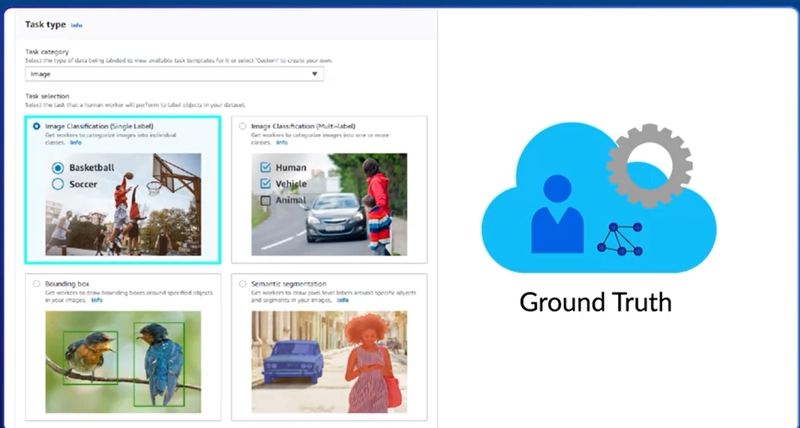
So a whole image classification what you see at the top here as single label or multi-label simply is this picture as a whole describes what my machine learning model should detect.
So as you can see at the top left we have it being labeled basketball. And very importantly, we're not narrowing in on any given part of this image to describe basketball. We're not zeroing in on the ball. We're not zeroing in on the hoop or the players. We're just saying this entire image represents basketball.
Very similarly on the right, we're saying that this entire image describes both humans and vehicles.

It can be a little confusing at times but in multi-level imaging, it's not saying look just at the human or just look at the vehicle. It says this entire thing as an entity is both a human with a vehicle.
Now, if you want to start to be more specific and say that you want to very specifically call up part of the image, or maybe this element will be remixed in other images, you need to start to look at bounding boxes and semantic segmentation.

What this does is it tells the machine learning image, look at what's in this segment or look at what is within this box, and apply the labels just to that. Of course, as you move from the top left to the bottom right in this selection it gets increasingly difficult.

With semantic segmentation being down to pixel level accuracy while whole image obviously is the entire image.
If you were to select that the task category was text, you are also going to be presented with various similar options.

Once again, you have whole text classification such as single label or multi-label, and you also have named entity recognition.
Now it's kind of heretical to say this, but in all reality named entity recognition is very similar to putting a bounding box on your image. You're basically saying this section of the text has a specific label applied to it. Either it's a person, a phrase, or an expression, but basically single label and multi-label text classification is whole text while named entity recognition is the ability to isolate phrases or people and objects out of the text.
To quickly move through with the last two types. Basically, video is very similar to image and text with the added element of time series.

So you can either classify the whole clip and object within the clip or very uniquely to video, you can track an object as it moves through multiple frames AKA multiple images. As a general rule of thumb, video classification is a bit more time intensive and difficult than just image classification. But of course, you can add a lot more details when you have time series and can see the object in context.
Now do keep in mind if you have a video, you don't necessarily need to do video machine learning. You are able to isolate specific frames and treat it as image machine learning. But that's a little beyond the scope of this class on which one to pick, but just know that Amazon Ground Truth has the ability to both do images and video depending on where the actual source of that image data is coming from.
And finally, if your data doesn't really fall into any of these, or maybe it's too complex or any given one type, you can actually start to define a custom set of tasks for both yourself or the human intelligence workers on the other side of the screen, to start to help you process your data.

Top comments (0)