See my previous post about Overview of Training the Model using SageMaker from here
And finally, after all this effort, after all of this training and creation and labeling, we're actually able to start using the model AKA inferencing it. Of course, SageMaker has a section for this. At its core, what you're going to do is make an endpoint in which you can call the model. But let's check that out through clicking into the inference section of SageMaker.
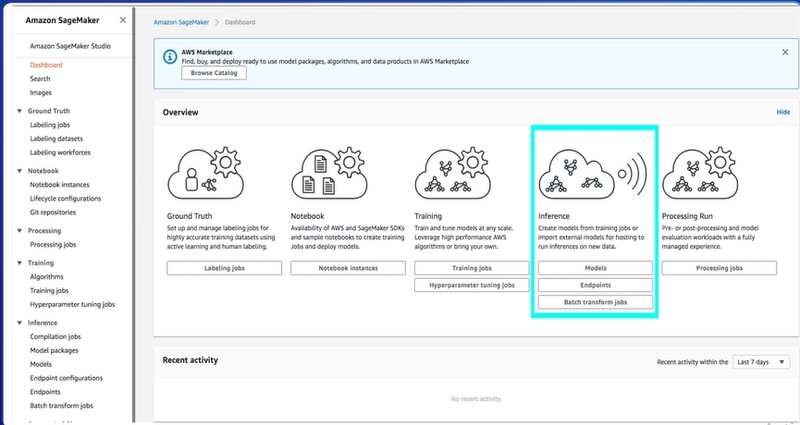
Once again, of course, assessable through the hub, AKA the dashboard. The dive into this, basically the way Amazon encourages you to interact with your SageMaker model is through basically an HTTP slash HTTPS endpoint. You're able to make calls to this, send it data and get a response.

Of course, coming out of the training job and especially coming out of the notebook, you're also able to use the Python objects or rather the framework's objects and import those into other machine learning frameworks.
So don't think you need to use SageMaker's end point system in order to use your models. It could actually be directly coded into your existing applications, especially after an export. But this is a really strong way of decoupling your machine learning and your production instance, in that your application developers and coders are able to just make an arrest call and get an inference result.
So basically when designing an endpoint, think if you want it to be an endpoint, completely detached and just kind of segregated like a microservice, or if you wanna export the model and have it act more like a library within an application.
Assuming you wanna go with an endpoint, the configuration can be set with an Amazon, of course, just not too many options,
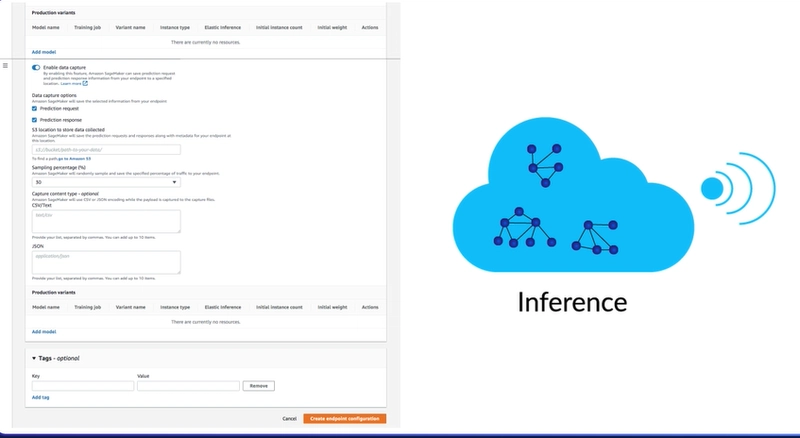
but you can configure how it will behave, but more importantly, you need to select, are you going to capture data? And what I mean by if you wanna capture data and enabling it pretty much as a data scientist or machine learning creator, you're going to want to capture it. You're going to wanna capture both the incoming predictions and the response you gave them. You can of course increase the sampling percentage and make sure it all gets stored depending on the volume or just a percentage of it.
But this allows you to tell how your consumers are interacting with your model in the real world.
But there's a huge caveat. And I'm speaking from personal experience here. Some applications are extremely sensitive, and you're not allowed to either see the incoming data or the outgoing prediction SageMaker allows you to store. Maybe you're only giving them a prediction result so you could test for prediction skew over time. But assuming privacy security and permission-wise, you're allowed to capture both the incoming and outgoing result. I really encourage you to do this at least at first, because it allows you to debug your model and very importantly, look for edge conditions you might not have seen in testing.

Top comments (0)