In this post, we will go over several modern application design architectures, with the predominant one being event and message-based architecture. After this mostly theoretical discussion, we will move into practical implementation. We will do this by going over two different AWS services. The first of these services, Amazon Simple Notification Service (SNS), is a managed messaging service that allows you to decouple publishers from subscribers. The second service is Amazon EventBridge, which is a serverless event bus. As we are going over each, we will also review the inclusion of these services into a .NET application so that you can see how it works.
Modern Application Design
The growth in the public cloud and its ability to quickly scale computing resources up and down has made the building of complex systems much easier. Let’s start by looking at what the Microservice Extractor for .NET does for you. For those of you unaware of this tool, you can check out the user guide or see a blog article on its use. Basically, however, the tool analyzes your code and helps you determine what areas of the code you can split out into a separate microservice. Figure 1 shows the initial design and then the design after the extractor was run.
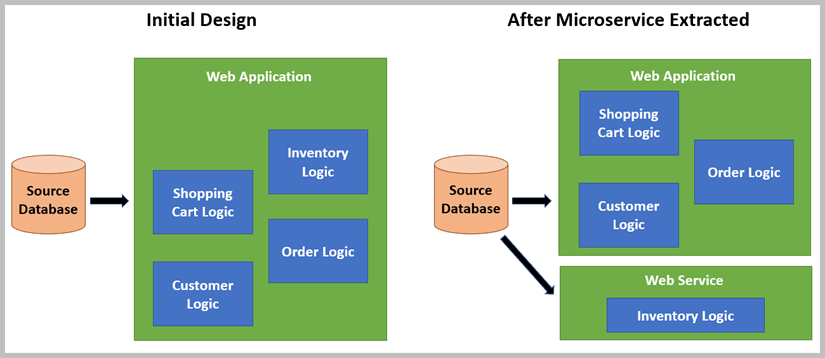 Figure 1. Pre and Post design after running the Microservice Extractor
Figure 1. Pre and Post design after running the Microservice Extractor
Why is this important? Well, consider the likely usage of this system. If you think about a typical e-commerce system, you will see that the inventory logic, the logic that was extracted, is a highly used set of logic. It is needed to work with the catalog pages. It is needed when working with orders, or with the shopping cart. This means that this logic may act as a bottleneck for the entire application. To get around this with the initial design means that you would need to deploy additional web applications to ease the load off and minimize this bottleneck.
Evolving into Microservices
However, the extractor allows us to use a different approach. Instead of horizontally scaling the entire application, scale the set of logic that gets the most use. This allows you to minimize the number of resources necessary to keep the application optimally running. There is another benefit to this approach as you now have an independently managed application, which means that it can have its own development and deployment processes and can be interacted with independently of the rest of the application stack. This means that a fully realized microservices approach could look more like that shown in Figure 2.
 Figure 2. Microservices-based system design
Figure 2. Microservices-based system design
This approach allows you to scale each web service as needed. You may only need one “Customer” web service running but need multiples of the “Shopping Cart” and “Inventory” running to ensure performance. This approach means you can also do work in one of the services, say “Shopping Cart” and not have to worry about testing anything within the other services because those won’t have been impacted – and you can be positive of that because they are completely different code lines.
This more decoupled approach also allows you to manage business changes more easily.
Note – Tightly coupled systems have dependencies between the systems that affect the flexibility and reusability of the code. Loosely coupled, or decoupled, systems have minimal dependencies between each other and allow for greater code reuse and flexibility.
Consider Figure 3 and what it would have taken to build this new mobile application with the “old-school” approach. There most likely would have been some duplication of business logic, which means that as each of the applications evolve, they would likely have drifted apart. Now, that logic is in a single place so it will always be the same for both applications (excluding any logic put into the UI part of the application that may evolve differently – but who does that?)
 Figure 3. Microservices-based system supporting multiple applications
Figure 3. Microservices-based system supporting multiple applications
One look at Figure 3 shows how this system is much more loosely coupled than was the original application. However, there is still a level of coupling within these different subsystems. Let’s look at those next and figure out what to do about them.
Deep Dive into Decoupling
Without looking any deeper into the systems than the drawing in Figure 3 you should see one aspect of tight coupling that we haven’t addressed. The “Source Database.” Yes, this shared database indicates that there is still a less than optimal coupling between the different web services. Think about how we used the Extractor to pull out the “Inventory” service so we could scale that independently of the regular application. We did not do the same to the database service that is being accessed by all these web services. So, we still have that quandary, only at the database layer than at the business logic layer.
The next logical step in decoupling these systems would be to break out the database responsibilities as well, resulting in a design like that shown in Figure 4.
 Figure 4. Splitting the database to support decoupled services
Figure 4. Splitting the database to support decoupled services
Unfortunately, it is not that easy. Think about what is going on within each of these different services; how useful is a “Shopping Cart” or an “Order” without any knowledge of the “Inventory” being added to the cart, or sold? Sure, those services do not need to know everything about “Inventory”, but they need to either interact with the “Inventory” service or go directly into the database to get information. These two options are shown in Figure 5.
 Figure 5. Sharing data through a shared database or service-to-service calls
Figure 5. Sharing data through a shared database or service-to-service calls
As you can see, however, we have just added back in some coupling, as in either approach the “Order” service and “Shopping Cart” service now have dependencies on the “Inventory” service in some form or another. However, this may be unavoidable based on certain business requirements – those requirements that mean that the “Order” needs to know about “Inventory.” Before we stress out too much about this design, let’s further break down this “need to know” by adding in an additional consideration about when the application needs to know about the data. This helps us understand the required consistency.
Strong Consistency
Strong consistency means that all applications and systems see the same data at the same time. The solutions in Figure 3 represent this approach because, regardless of whether you are calling the database directly or through the web service, you are seeing the most current set of the data, and it is available immediately after the data is persisted. There may easily be requirements where that is required. However, there may just as easily be requirements where a slight delay between the “Inventory” service and the “Shopping Cart” service knowing information may be acceptable.
For example, consider how a change in inventory availability (the quantity available for the sale of a product) may affect the shopping cart system differently than the order system. The shopping cart represents items that have been selected as part of an order, so inventory availability is important to it – it needs to know that the items are available before those items can be processed as an order. But when does it need to know that? That’s where the business requirements come into play. If the user must know about the change right away, that will likely require some form of strong consistency. If, on the other hand, the inventory availability is only important when the order is placed, then strong consistency is not as necessary. That means there may be a case for eventual consistency.
Eventual Consistency
As the name implies, data will be consistent within the various services eventually – not right away. This difference may be as slight as milliseconds or it can be seconds or even minutes, all depending upon business needs and system design. The smaller the timeframe necessary, the more likely you will need to use strong consistency. However, there are plenty of instances where seconds and even minutes are ok. An order, for example, needs some information about a product so that it has context. This could be as simple as the product name or more complex relationships such as the warehouses and storage locations for the products. But the key factor is that changes in this data are not really required to be available immediately to the order system. Does the order system need to know about a new product added to the inventory list? Probably not – as it is highly unlikely that this new product will be included in an order within milliseconds of becoming active. Being available within seconds should be just fine. Figure 6 shows a time series graph of the differences between strong and eventual consistency.
 Figure 6. Time series showing the difference between strong and eventual consistency
Figure 6. Time series showing the difference between strong and eventual consistency
What does the concept of eventual consistency mean when we look at Figure 3 showing how these three services can have some coupling? It gives us the option for a paradigm shift. Our assumption up to this time is that data is stored in a single source, whether all the data is stored in a big database or whether each service has its own database – such as the Inventory service “owning” the Inventory database that stores all the Inventory information. Thus, any system needing inventory data would have to go through these services\databases in some way.
This means our paradigm understands and accepts the concept of a microservice being responsible for maintaining its own data – that relationship between the inventory service and the inventory database. Our paradigm shift is around the definition of the data that should be persisted in the microservices database. For example, currently, the order system stores only data that describes orders – which is why we need the ability to somehow pull data from the inventory system. However, this other information is obviously critical to the order so instead of making the call to the inventory system we instead store that critical inventory-related data in the order system. Think what that would be like.
Oh No! Not duplicated data!
Yes, this means some data may be saved in multiple places. And you know what? That’s ok. Because it is not going to be all the data, but just those pieces of data that the other systems may care about. That means the databases in a system may look like those shown in Figure 7 where there may be overlap in the data being persisted.
 Figure 7. Data duplication between databases
Figure 7. Data duplication between databases
This data overlap or duplication is important because it eliminates the coupling that we identified when we realized that the inventory data was important to other systems. By including the interesting data in each of the subsystems, we no longer have that coupling, and that means our system will be much more resilient.
If we continued to have that dependency between systems, then an outage in the inventory system means that there would also be an outage in the shopping cart and order systems, because those systems have that dependency upon the inventory system for data. With this data being persisted in multiple places, an outage in the inventory system will NOT cause any outage in those other systems. Instead, those systems will continue to happily plug along without any concern for what is going on over in inventory-land. It can go down, whether intentionally because of a product release or unintentionally, say by a database failure, and the rest of the systems continue to function. That is the beauty of decoupled systems, and why modern system architectural design relies heavily on decoupling business processes.
We have shown the importance of decoupling and how the paradigm shift of allowing some duplication of data can lead to that decoupling. However, we haven’t touched on how we would do this. In this next section, we will go into one of the most common ways to drive this level of decoupling and information sharing.
Designing a messaging or event-based architecture
The key to this level of decoupling requires that one system notify the other systems when data has changed. The most powerful method for doing this is through either messaging or events. While both messaging and events provide approaches for sending information to other systems, they represent different forms of communication and different rules that they should follow.
Messaging
Conceptually, the differences are straightforward. Messaging is used when:
- Transient Data is needed – this data is only stored until the message consumer has processed the message or it hits a timeout or expiration period.
- Two-way Communication is desired – also known as a request\reply approach, one system sends a request message, and the receiving system sends a response message in reply to the request.
- Reliable Targeted Delivery – Messages are generally targeted to a specific entity. Thus, by design, a message can have one and only one recipient as the message will be removed from the queue once the first system processes it.
Even though messages tend to be targeted, they provide decoupling because there is no requirement that the targeted system is available when the message is sent. If the target system is down, then the message will be stored until the system is back up and accepting messages. Any missed messages will be processed in a First In – First Out process and the targeted system will be able to independently catch up on its work without affecting the sending system.
When we look at the decoupling we discussed earlier, it becomes apparent that messaging may not be the best way to support eventual consistency as there is more than one system that could be interested in the data within the message. And, by design, messaging isn’t a big fan of this happening. So, with these limitations, when would messaging make sense?
Note: There are technical design approaches that allow you to send a single message that can be received by multiple targets. This is done through a recipient list, where the message sender sends a single message and then there is code around the recipient list that duplicates that message to every target in the list. We won’t go into these approaches here.
The key thing to consider about messaging is that it focuses on assured delivery and once and once-only processing. This provides insight into the types of operations best supported by messaging. An example may be the web application submitting an order. Think of the chaos if this order was received and processed by some services but not the order service. Instead, this submission should be a message targeted at the order service. Sure, in many instances we are handling this as an HTTP Request (note the similarities between a message and the HTTP request) but that may not always be the best approach. Instead, our ordering system sends a message that is assured of delivery to a single target.
Events
Events, on the other hand, are traditionally used to represent “something that happened” – an action performed by the service that some other systems may find interesting. Events are for when you need:
- Scalable consumption – multiple systems may be interested in the content within a single event
- History – the history of the “thing that happened” is useful. Generally, the database will provide the current state of information. The event history provides insight into when and what caused changes to that data. This can be very valuable insight.
- Immutable data – since an event represents “something that already happened” the data contained in an event is immutable – that data cannot be changed. This allows for very accurate tracing of changes, including the ability to recreate database changes.
Events are generally designed to be sent by a system, with that system having no concern about whether other systems receive the event or act upon it. The sender fires the event and then forgets about it.
When you consider the decoupled design that we worked through earlier, it becomes quickly obvious that events are the best approach to provide any changed inventory data to the other systems. In the next article, we will jump right into Amazon Simple Notification Service (SNS), and talk more about events within our application using SNS as our guide.

Top comments (0)