
Purpose :
Machine learning development can be a complex and expensive process and there are barriers to adoption at every step of the machine learning workflow from data aggregation to preprocessing, which is time consuming and compute intensive, to choosing the right algorithm, which is often done by trial and error, to long running training cycles, which leads to increased costs. In this blog we will discuss recommendations around provisioning a cost effective, manageable, secure, scalable, high performance, efficient, highly available, fault tolerant and recoverable MLOps architecture that an organization can adopt to solve pain points around Collaboration, Scaling, Reproducibility, Testing, Monitoring, Security and deployment strategies around ML projects lifecycle.Background :
Data science and analytics teams are often seen operating between increasing business expectations and abstract environments developing into complex solutions. This makes it challenging to transform data into solid answers for stakeholders consistently. In such a situation, How can teams overcome complexity and live up to the expectations placed on them and deliver business impacts?
MLOps provides some answers, There is no one size fits all when it comes to implementing an MLOps solution on Amazon Web Services (AWS). Like any other technical solution, MLOps should be implemented to meet the project requirements.
Machine Learning Life Cycle
One way to categorize a machine learning platform's capabilities is through the machine learning life cycle stages. The typical ML life cycle can be described in the following nine steps:
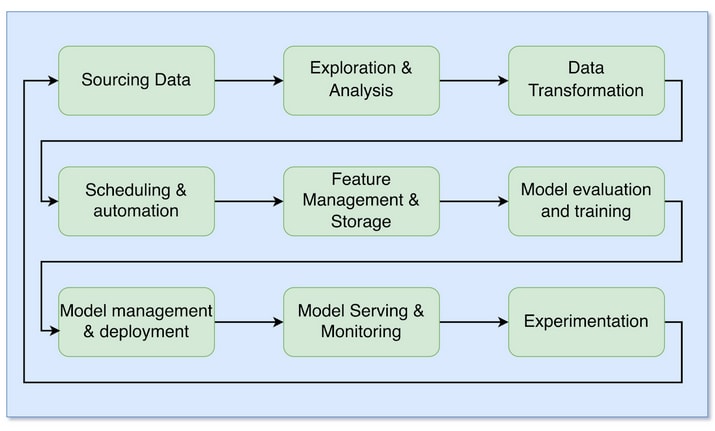
Starting by sourcing data, a data scientist will explore and analyze it. The raw data is transformed into valuable features, typically involving scheduling and automation to do this regularly. The resultant features are stored and managed, available for the various models and other data scientists to use. As part of the exploration, the data scientist will also build, train, and evaluate multiple models. Promising models are stored and deployed into production. The production models are then served and monitored for a while. Typically, there are numerous competing models in production, and choosing between them or evaluating them is done via experimentation. With the learnings of the production models, the data scientist iterates on new features and models.
As an organization, Looking towards leveraging ML in various aspects in their business, from gathering insights on the products (based on reviews, tweets etc), build user experiences (recommendation, personalization) or create impactful solutions around healthcare, ecommerce etc, there are some major concerns around CI/CD, ML lifecycle, collaboration, monitoring, experiments tracking, testing, security and infrastructure that a MLOps platform should address and empower data scientists to create ML solutions that drive direct business impact.
These solutions can range from simple analyses to production ML systems that serve millions of customers. The MLOps Platform aims to provide these users with a unified set of tools to develop and confidently deploy their ML solutions rapidly.
Key Components of an MLOps Solution
This section briefly discusses the key components for implementing an MLOps solution:
- A version control system to store, track, and version changes to ML code.
- A version control system to track and version changes to your datasets.
- A network layer that implements the necessary network resources to ensure the MLOps solution is secured.
- An ML-based workload to execute machine learning tasks. AWS has a three-layered ML stack to choose from based on skill level.
- AI services: They are a fully managed set of services that enables users to quickly add ML capabilities to workloads using API calls. E.g: Amazon Rekognition and Amazon Comprehend.
- ML services: AWS provides managed services and resources (Amazon SageMaker suite, for example) to enable users to label data and build, train, deploy, and operate ML models.
- ML frameworks and infrastructure: This is for expert ML practitioners using open-source frameworks like TensorFlow, PyTorch, and Apache MXNet; Deep Learning AMI for Amazon EC2 instances; and Deep Learning Containers to implement own tools and workflows to build, train, and deploy the ML models.
- Use infrastructure as code (IaC) to automate the provisioning and configuration of your cloud-based ML workloads and other IT infrastructure resources.
- An ML (training/retraining) pipeline to automate the steps required to train/retrain and deploy your ML models.
- An orchestration tool to orchestrate and execute your automated ML workflow steps.
- A model monitoring solution to monitor production models’ performance to protect against both model and data drift. You can also use the performance metrics as feedback to help improve the models’ future development and training.
- A model governance framework to make it easier to track, compare, and reproduce your ML experiments and secure your ML models.
- A data platform like Amazon Simple Storage Service (Amazon S3) to store your datasets.
Setting up a MLOps Pipeline
Data science and analytics teams are often squeezed between increasing business expectations and sandbox environments evolving into complex solutions. This makes it challenging to transform data into solid answers for stakeholders consistently.
The ML-based workloads should support the reproducibility in any machine learning pipeline, which is central to any MLOps solution. The ML-based workload implementation choice can directly impact the design and implementation of any MLOps solution.
If the ML capabilities required by your use cases can be implemented using the AI services, then an MLOps solution is not required. For instance the business use case to track the sentiment of users from their social media content (tweets, facebook posts) which leverages AWS AI services like Comprehend and Translate to extract insights can be well supported with a minimal solution where an listener running on a Amazon EC2 instance ingesting tweets / posts and delivering them via Kinesis Data Firehose and storing the raw content in S3 bucket. Amazon S3 invokes an AWS Lambda function to analyze the raw tweets using Amazon Translate to translate non-English tweets into English, and Amazon Comprehend to use natural-language-processing (NLP) to perform entity extraction and sentiment analysis.
A second Kinesis Data Firehose delivery stream loads the translated tweets and sentiment values into the sentiment prefix in the Amazon S3 bucket. A third delivery stream loads entities in the entities prefix using in the Amazon S3 bucket.
This solution uses a data lake leveraging AWS Glue for data transformation, Amazon Athena for data analysis, and Amazon QuickSight for data visualization. AWS Glue Data Catalog contains a logical database which is used to organize the tables for the data on Amazon S3. Athena uses these table definitions to query the data stored on Amazon S3 and return the information to an Amazon QuickSight dashboard.
On the other hand, if you use either the ML services or ML frameworks and infrastructure, we recommend you implement an MLOps solution regardless of the use case. The ML services stack’s ease of use and support for various use cases makes it desirable for implementing any ML-based pipeline.
Also, since different model training and serving algorithms can alter aspects of the MLOps solution, there are three main options Amazon SageMaker provides when it comes to choosing your training algorithm:
- Use a built-in Amazon SageMaker algorithm or framework. With this option, a training dataset is the only input developers and data scientists have to provide when training their models. On the other hand, the trained model artefacts are the only input they need to deploy the models. This is a good fit for scenarios where off-the-shelf solutions serve the purpose. .
- Use pre-built Amazon SageMaker container images. For this option, you need to provide two inputs to train your models, and they are your training scripts and datasets. Likewise, the inputs for deploying the trained models are your serving scripts and the trained model artefacts.
- Extend a pre-built Amazon SageMaker container image, or adapt an existing container image. This is for more advanced use cases. You are responsible for developing and maintaining those container images. Therefore, you may want to consider implementing a CI/CD pipeline to automate the building, testing, and publishing of the customized Amazon SageMaker container images and then integrate the pipeline with your MLOps solution.

This can introduce some complexity to the MLOps solution, but it provides the flexibility to use custom and other third-party libraries to build and train models. This option’s training inputs are your training scripts, datasets and customized Docker image for Amazon SageMaker. Lastly, the inputs for model deployment are the trained model artefacts, serving scripts and customized Docker image for Amazon SageMaker.
Recommended MLOps Platform :
This recommended architecture demonstrates how you can integrate the Amazon SageMaker container image CI/CD pipeline with your ML (training) pipeline.
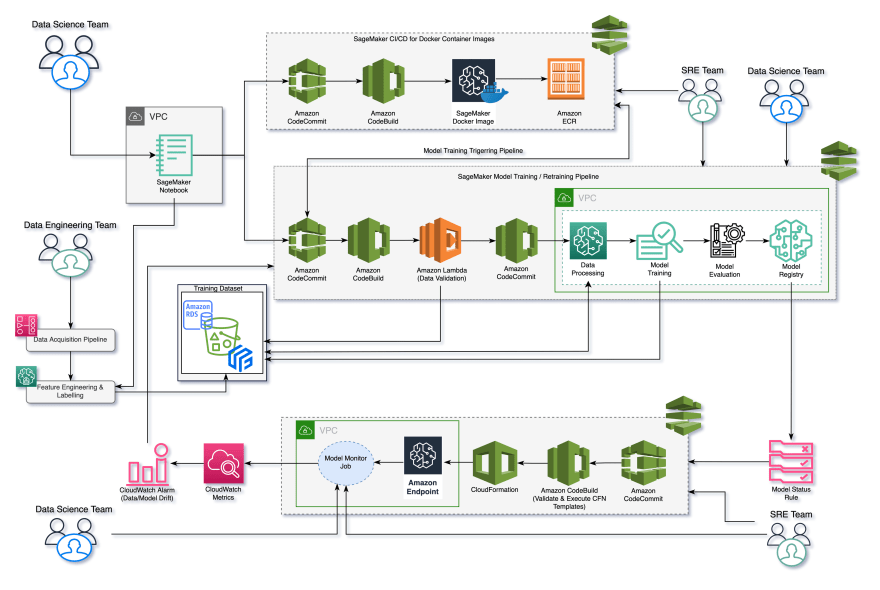
The components of the MLOps Platform architecture diagram are:
- A secured development environment was implemented using an Amazon SageMaker Notebook Instance deployed to a custom virtual private cloud (VPC), and secured by implementing security groups and routing the notebook’s internet traffic via the custom VPC. \ Also, the development environment has two Git repositories (AWS CodeCommit) attached: one for the Exploratory Data Analysis (EDA) code and the other for developing the custom Amazon SageMaker Docker container images.
- An ML CI/CD pipeline made up of three sub-components:
- Data validation step implemented using AWS Lambda and triggered using AWS CodeBuild.
- Model training/retraining pipeline implemented using Amazon SageMaker Pipelines (pipeline-as-code) and executed using CodeBuild.
- Model deployment pipeline that natively supports model rollbacks was implemented using AWS CloudFormation.
Finally, AWS CodePipeline is used to orchestrate the pipeline.
- A CI/CD pipeline for developing and deploying the custom Amazon SageMaker Docker container image. This pipeline automatically triggers the ML pipeline when you successfully push a new version of the SageMaker container image, providing the following benefits:
- Developers and data scientists can thoroughly test and get immediate feedback on the ML pipeline’s performance after publishing a new version of the Docker image. This helps ensure ML pipelines are adequately tested before promoting them to production.
- Developers and data scientists don’t have to manually update the ML pipeline to use the latest version of the customized Amazon SageMaker image when working on the develop git branch. They can branch off the develop branch if they want to use an older version or start developing a new version, which they will merge back to develop branch once approved.
- A model monitoring solution implemented using Amazon SageMaker Model Monitor to monitor the production models’ quality continuously. This provides monitoring for the following: data drift, model drift, the bias in the models’ predictions, and drifts in feature attributes. You can start with the default model monitor, which requires no coding.
- A model retraining implementation that is based on the metric-based model retraining strategy. There are three main retaining strategies available for your model retraining implementation:
- Scheduled: This kicks off the model retraining process at a scheduled time and can be implemented using an Amazon EventBridge scheduled event.
- Event-driven: This kicks off the model retraining process when a new model retraining dataset is made available and can be implemented using an EventBridge event.
- Metric-based: This is implemented by creating a Data Drift CloudWatch Alarm that triggers your model retraining process once it goes off, fully automating your correction action for a model drift.
- A data platform can be implemented using Amazon S3 buckets, RDS or Feast with versioning enabled.
- A model governance framework, which is not obvious from the architectural diagram and is made of the following components:
- A model registry for versioning and tracking the trained model artefacts, implemented using Amazon SageMaker Model Registry.
- Dataset versioning implemented using Amazon S3 bucket versioning.
- ML workflow steps auditability, visibility, and reproducibility implemented using Amazon SageMaker Lineage Tracking.
- Secured trained model artefacts implemented using AWS Identity and Access Management (IAM) roles to ensure only authorized individuals have access.
People in MLOps :
| Rold | Role in ML Life Cycle | MLOps Requirements |
| Data Scientists |
|
|
| Data Engineers |
|
|
| Software Engineers |
|
|
| ML Architects |
|
|
| SRE |
|
|
References :
- AWS MLOps Framework | Implementations | AWS Solutions
- Harnessing the power of Machine Learning to fuel the growth of Halodoc
- MLOPs with Amazon Web Services
- Amazon SageMaker Documentation
- Introducing MLOps [Book]
- ML Ops: Machine Learning Operations
- A Practical Guide to MLOps in AWS Sagemaker — Part I





Top comments (3)
Great Article, Must Read !!
Very interesting your post, greetings.
Useless article, all fluff and talk, w/ no github to prove it out.