S3 (Simple Storage Service) is a top-rated service for data storage in AWS. It offers high durability, availability and scalability. I've used S3 for various use cases, including storing many files, backups of databases, analytics, data archiving and static site hosting.
A few months ago, I encountered a case where we needed to query data from a large JSON file in S3. We went with the usual approach of getting the object in our Lambda, filtering the JSON object for the data we need in code. So we loaded the file content in memory and filtered it. As this file grew significantly, the Lambda started timing out.

We often need to retrieve the whole file from S3, but if it is large (e.g. 2TB), it will slow down your app. If you are transferring this file Out from Amazon S3 directly to the internet (e.g. if you host your app outside of AWS or you're downloading this file), that's a significant cost increase.
What can we do?
AWS provides a feature in S3 called "S3 Select", where the user can query parts of an object using an SQL-like statement. This is good because the filtering happens in S3 before it reaches your application.
S3 Select works on multiple file types, including CSV, JSON and Parquet.
Please show us the code...
Before getting into the code, the below diagrams could help us visualize how this works.
Get Object

S3 Select

For the rest of this post, we will use Terraform to set up an S3 bucket and a lambda. We will first retrieve an entire object in our Lambda, then change it to query parts of the object using "S3 Select".
If you're impatient, feel free to skip to the "S3 Select" section.
Terraform
I will split the Terraform configuration into multiple files - Feel free to adjust this as you deem appropriate - in an "infrastructure" folder:
- Create a
provider.tfto include AWS as a provider
provider "aws" {
profile = "default"
region = "ap-southeast-2"
}
-
Create a test.json file and add it to an S3 bucket
- Assume we have a JSON file called 'test.json' and has the following content (copied from MDN) - we will keep the size of the file small for this example:
{ "squadName": "Super hero squad", "homeTown": "Metro City", "formed": 2016, "secretBase": "Super tower", "active": true, "members": [ { "name": "Molecule Man", "age": 29, "secretIdentity": "Dan Jukes", "powers": [ "Radiation resistance", "Turning tiny", "Radiation blast" ] }, { "name": "Madame Uppercut", "age": 39, "secretIdentity": "Jane Wilson", "powers": [ "Million tonne punch", "Damage resistance", "Superhuman reflexes" ] }, { "name": "Eternal Flame", "age": 1000000, "secretIdentity": "Unknown", "powers": [ "Immortality", "Heat Immunity", "Inferno", "Teleportation", "Interdimensional travel" ] } ] }
- Add the following content to the `s3.tf` file
```
resource "aws_s3_bucket" "s3-select" {
bucket = var.bucketName
}
resource "aws_s3_bucket_policy" "outoffocus-policy" {
bucket = aws_s3_bucket.s3-select.id
policy = templatefile("s3-policy.json", { bucket = var.bucketName })
}
resource "aws_s3_object" "outoffocus-index" {
bucket = aws_s3_bucket.s3-select.id
key = "test.json"
source = "./test.json"
acl = "public-read"
}
- Create the IAM roles and permissions needed to get the Lambda to interact with the S3 bucket. In a
iam.tffile:
resource "aws_iam_role" "s3_select_lambda_execution_role" {
name = "s3_select_lambda_execution_role"
assume_role_policy = data.aws_iam_policy_document.lambda_assume_role.json
}
data "aws_iam_policy_document" "lambda_assume_role" {
statement {
actions = ["sts:AssumeRole"]
principals {
type = "Service"
identifiers = ["lambda.amazonaws.com"]
}
}
}
resource "aws_iam_role_policy_attachment" "lambda_policies_attachment" {
role = aws_iam_role.s3_select_lambda_execution_role.name
policy_arn = aws_iam_policy.lambda_policies.arn
}
resource "aws_iam_policy" "lambda_policies" {
name = "s3-select-lambda_logging_cloudwatch_access"
description = "lambda logs in CloudWatch"
policy = data.aws_iam_policy_document.lambda_policies_document.json
}
data "aws_iam_policy_document" "lambda_policies_document" {
statement {
actions = [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
]
resources = [
"arn:aws:logs:*:*:*",
]
}
statement {
actions = [
"s3:GetObject"
]
resources = [
"arn:aws:s3:::${var.bucketName}/*"
]
}
}
- Create a
lambda.tffile that would include the following configuration:
resource "aws_lambda_function" "s3-select" {
function_name = "s3-select-lambda"
handler = "index.handler"
runtime = "nodejs16.x"
filename = "lambda_function.zip"
source_code_hash = filebase64sha256("lambda_function.zip")
role = aws_iam_role.s3_select_lambda_execution_role.arn
depends_on = [
aws_iam_role_policy_attachment.lambda_policies_attachment
]
}
- Finally, create a
variables.tffile to include the bucketName variable used earlier ```
variable "bucketName" {
default = "your-unique-s3-bucket-name"
type = string
}
### Lambda Code
Create a new npm project by running `npm init` and following the steps in your terminal. Create a "src" folder with an index.js file in it:
const { S3Client, GetObjectCommand } = require("@aws-sdk/client-s3");
const consumers = require("stream/consumers");
const params = {
Bucket: "your-unique-s3-bucket-name",
Key: "test.json",
};
exports.handler = async (event) => {
const client = new S3Client({});
const command = new GetObjectCommand(params);
const response = await client.send(command);
const objectText = await consumers.text(response.Body);
console.log("here is the returned object", objectText);
return {
statusCode: 200,
body: JSON.stringify("Hello from Lambda!"),
};
};
Of course, this is not optimal (we could use TS and pass the params as env variables, etc.), but this should be sufficient for this blog post.
To package your Lambda into a zip file and copy it to the infrastructure folder, run the following commands:
zip -r lambda_function.zip ./.js ./.json ./node_modules/*
cp lambda_function.zip ../infrastructure/
Once done, deploy your code to AWS by running `terraform init` then `terraform apply` in your "infrastructure" folder.
### S3 Select
There's nothing you would need to do to enable S3 Select. It's an API call where we pass the SQL-Like statement to S3, and everything happens auto-magically from there.
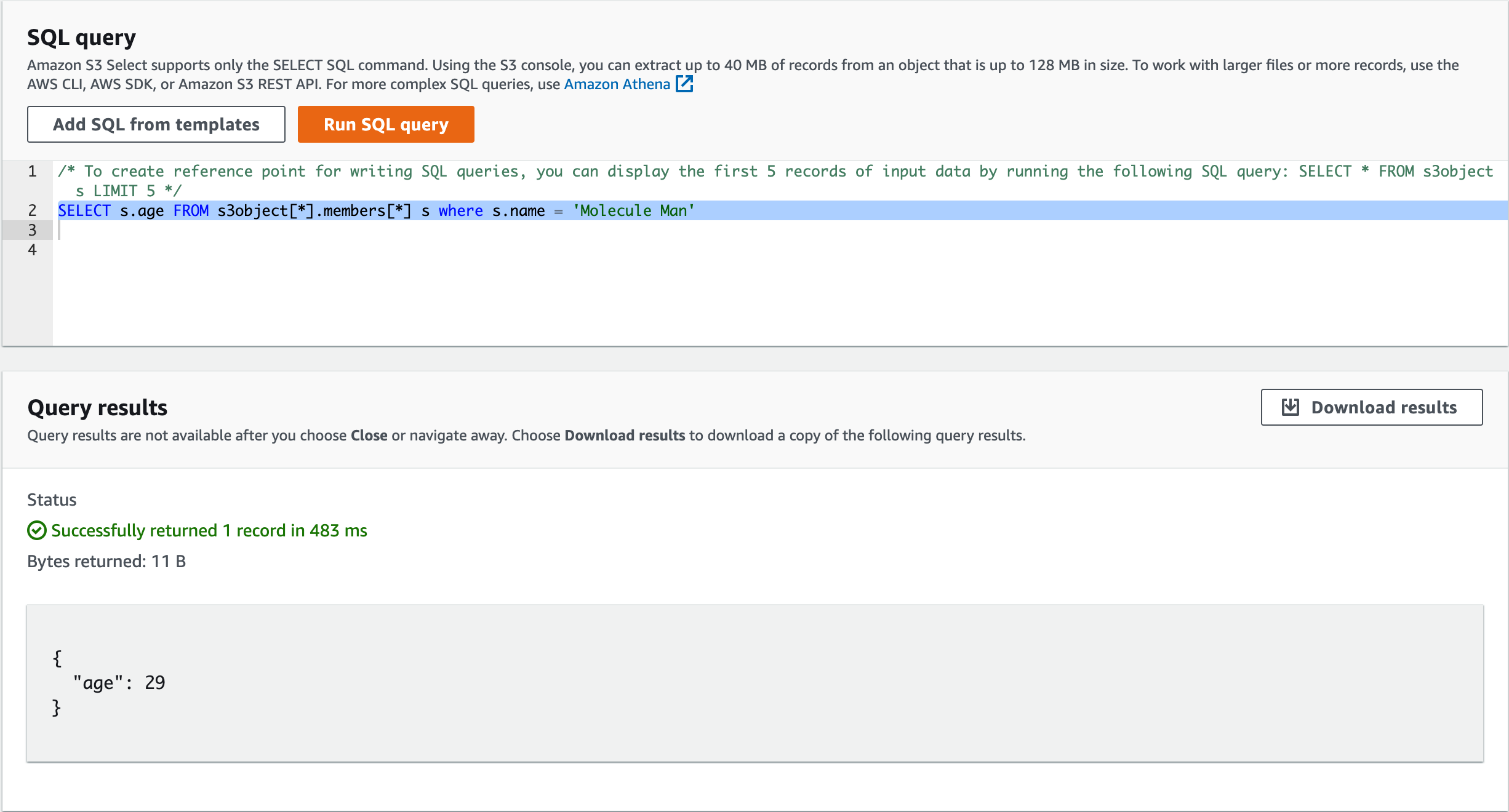
Let's start with writing the SQL statement. Consider we want to return the "Molecule Man" age in the "members" array. The query looks as follows:
SELECT s.age FROM s3object[].members[] s WHERE s.name = 'Molecule Man'
The query isn't precisely SQL, but the syntax is very similar. For more details, check this [page](https://docs.aws.amazon.com/AmazonS3/latest/userguide/s3-glacier-select-sql-reference-select.html). I also find it helpful to try the query in the AWS console. To do that:
- Select the object in the S3 bucket
- Click Action -> S3 Select
- Write the query
The new Lambda function code looks as follows:
const { S3Client, SelectObjectContentCommand } = require("@aws-sdk/client-s3");
const consumers = require("stream/consumers");
const params = {
Bucket: "your-unique-s3-bucket-name",
Key: "test.json",
ExpressionType: "SQL",
Expression:
"SELECT s.age FROM s3object[].members[] s WHERE s.name = 'Molecule Man'",
InputSerialization: {
JSON: {
Type: "DOCUMENT",
},
},
OutputSerialization: {
JSON: {},
},
};
exports.handler = async (event) => {
const client = new S3Client({});
const command = new SelectObjectContentCommand(params);
const response = await client.send(command);
const objectText = await consumers.text(response.Body);
console.log("here is the returned object", objectText);
return {
statusCode: 200,
body: JSON.stringify("Hello from Lambda!"),
};
};
The "InputSerialization" property defines the data format in our query object. The JSON Type could be a "DOCUMENT|LINE" to specify whether the whole file is a JSON object or each line is a JSON object.
The "OutputSerialization" property specifies how the output object is JSON format. We could define a "RecordDelimiter" property inside it, which would be used to separate the output records. Keeping it empty would default to using the newline character ("\n").
For more info, have a look at https://docs.aws.amazon.com/AWSJavaScriptSDK/latest/AWS/S3.html#selectObjectContent-property.
I hope this was helpful. Do you have a different method to query big objects in S3? I'd love to hear from you.
---
Thanks for reading this far. Did you like this article and you think others might find it useful? Feel free to share it on [Twitter](twitter.com/intent/tweet?url=https%3A%2F%2Fdev.to%2Faws-builders%2Fhow-to-query-a-large-file-in-s3-4doa%0A%0A%23aws%20%23awscommunity%20%23awscommunitybuilder%20%23softwaredeveloment&text=Check%20this%20article%20by%20%40Alee_Haydar%20on%20how%20to%20query%20large%20files%20in%20S3%3A%20%F0%9F%91%89) or [LinkedIn](https://www.linkedin.com/sharing/share-offsite/?url=https://dev.to/aws-builders/how-to-query-a-large-file-in-s3-4doa).

Top comments (0)