From the widely recognized GDPR in Europe to Brazil's LGPD regulations, and the more recent introduction of India's DPDP law, over 100 countries now have some form of privacy regulation in place. What's common among many of these regulations is the concept of data residency – the physical location of your data. However, each region's requirements bring their own unique nuances, encompassing restrictions on data transfer, data storage locations, and individual data rights.
Navigating this complex sphere of privacy regulations is a huge burden for many companies born in the cloud. Their data simply ends up everywhere, and tracking down the locations, adhering to local laws, and even storing and using it locally is enormously complex and expensive.
Over the past year, I've engaged with numerous companies eager to expand their businesses into new markets, such as Europe and Australia. However, they've encountered a significant roadblock – the absence of a robust technology solution to address the data residency requirements of these regions. As a result, they face the expensive and nightmarish scenario of duplicating their cloud infrastructure for each new region, which not only hampers operational efficiency but also limits their data analyst and scientists from running analytics globally.
In this blog post, I offer a solution to this pressing technology and business challenge by introducing a PII data privacy vault. This architectural approach to data privacy effectively removes the burden of data residency, compliance, and data security responsibilities from your infrastructure, providing a seamless path for global expansion and data management.
Let’s dive in.
Data Residency and Barriers to Expansion
To grasp the intricacies of regulatory compliance in the context of global expansion, it’s important to understand a few key concepts.
Compliance
Compliance denotes a business's adherence to the laws and regulations governing data privacy and protection. These regulations are contingent on the geographic location of the customer whose data is being collected. Ensuring compliance is imperative for legal reasons as it shields businesses from financial penalties, license revocations, and the erosion of customer trust.
Data Residency
Data residency pertains to the physical location where customer data is stored. For instance, a website may serve customers in the EU, but their data could be hosted on a server located in Chicago. Different countries and regions have precise laws dictating how customer data should be handled, processed, stored, and safeguarded, making data residency a critical consideration.
Varying Regulations
The complexity surrounding data residency and compliance obligations primarily arises from the diversity of regulations worldwide. For instance, the European Union (EU) has GDPR, Brazil follows LGPD, and the United States enforces a patchwork of state-specific laws like CCPA in California and CTDPA in Connecticut. These regulations diverge significantly in terms of their stipulations and penalties.
Barriers to Global Expansion
The disparities in regulations and compliance requirements often pose formidable obstacles for companies striving to attain a global presence. Navigating diverse regulatory frameworks demands significant time, resources, and expertise. The resulting complexity frequently dissuades businesses from venturing into new markets, thereby constraining opportunities for global expansion.
We’ve looked at the problem, now, let’s explore an approach to addressing these challenges.
What is a Data Privacy Vault?
A data privacy vault isolates, protects, and governs access to sensitive customer data. Within the vault, confidential information is securely stored, while abstract and non-sensitive tokens, serving as references, are retained in conventional cloud storage. This means that only non-sensitive tokenized data is accessible to other systems, ensuring the utmost protection and compliance.
In a recent IEEE article, the authors made a case that this architectural approach to data privacy is the future of privacy engineering. Just as any modern system likely contains back end services, a database, and a warehouse, all modern systems need a data privacy vault to safely store, handle, and use of sensitive customer PII.
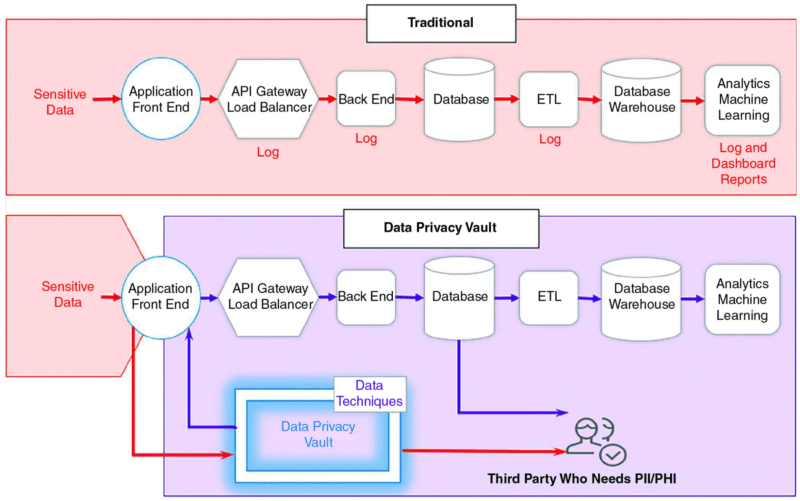
Let's take a look at a specific example for a simple web application. In the image below, a phone number is being collected by a front-end application. For effective de-scoping, it’s ideal to initiate the de-identification process at the earliest stage in the data lifecycle. In this scenario, the phone number is stored directly within the vault during collection at the front end.
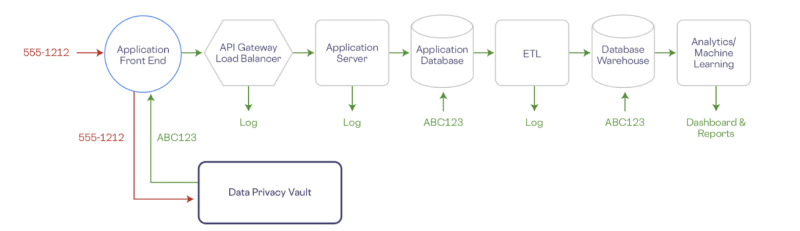
Within the vault, the phone number, alongside any other personally identifiable information (PII), is stored within a robust and isolated environment, segregated from your organization's existing infrastructure. All downstream services, ranging from application databases to data warehouses, analytics platforms, and logging systems, interact solely with tokenized (de-identified) representations of the data. Queries against the PII for specialized operations or algorithmic operations against PII execute directly within the vault.
Access to de-tokenize or re-identify data is controlled through a zero trust model. Policy-based rules control who sees what, when, where, and for how long on a row and column level.
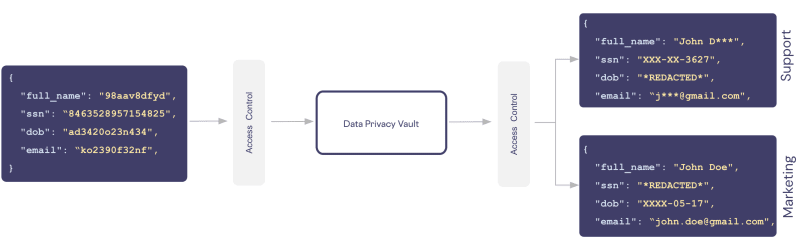
The vault combines the principle of isolation, zero trust, privacy-enhancing technologies, and governance controls to insulate your systems from ever having to touch PII directly. This places your AWS components beyond the scope of regulatory compliance, assuring a higher level of data protection and adherence to data residency requirements.
Your AWS Services Handle Only De-identified Data
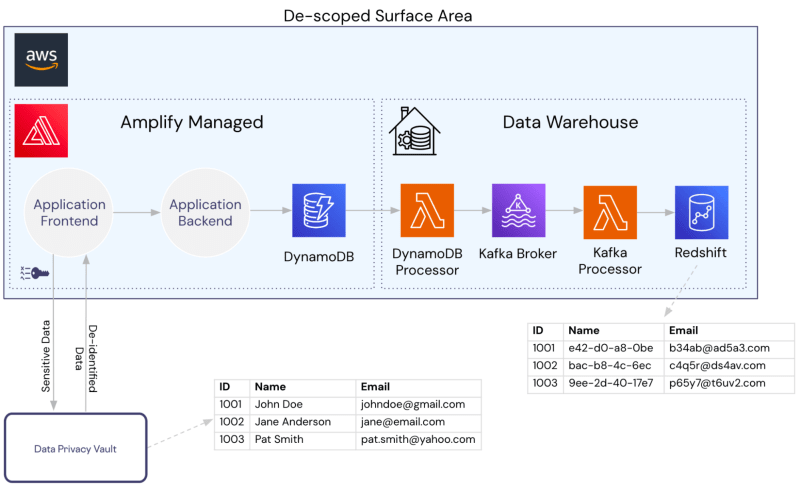
Let’s assume we have a simple application infrastructure as shown below with AWS Amplify providing the web server infrastructure, DynamoDB for application storage, and Redshift for warehousing.
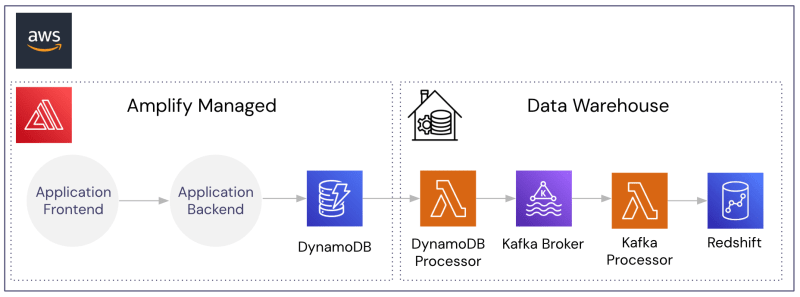
Without a vault in place, everything within our AWS account is under compliance and security scope.
By introducing the vault as shown below (in this example, the collection of PII is handled directly from the vault), we de-scope all our AWS services. The services are only ever handling de-identified data, including the warehouse.
Many analytical operations can be performed with de-identified data provided the data is consistently generated. A warehouse doesn’t need to have access to someone’s name, it only needs a consistently generated representation of the name in order to execute counts, group bys, and joins.
Storing PII to Different Regionalized Vaults
With Skyflow, a data privacy vault company, you can host vaults in various global regions and route sensitive data to a specific regional vault for storage and use. For instance, consider how the following application architecture meets data residency requirements across multiple regions:
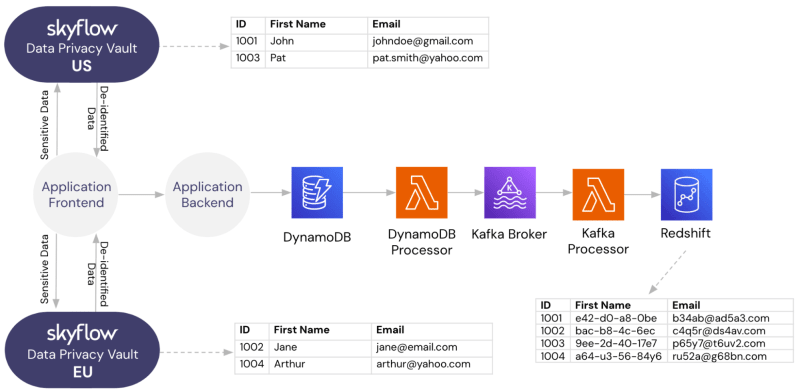
- Your company’s site collects customer PII during account creation.
- On the client side, the website detects the customer’s location.
- Detecting that the customer is in the EU, the client-side code uses Skyflow’s SDK to collect the PII data and store it in your company’s data privacy vault in Frankfurt, Germany. Note: For customers based in the US, the PII data is instead routed to the data privacy vault in the US (in this case, Virginia).
- The EU-based customer’s sensitive PII is stored in the EU-based data privacy vault, and Skyflow responds with de-identified data.
- The client-side code sends the account request, now with de-identified data, to the server.
- The server processes the request, storing the data (now de-identified and tokenized) in cloud storage in the “Oregon, US” region.
- At the end of the week, your company’s Redshift instance in Tokyo, Japan, loads the data (already de-identified and tokenized) from cloud storage to perform analytics.
Deploying multiple vaults situated in different regions streamlines the management of your sensitive data, ensuring compliance with data residency requirements across all your markets.
The data privacy vault architecture significantly simplifies the complexities associated with data residency and compliance. Furthermore, by exempting Redshift (or any warehouse) from the compliance responsibilities tied to data residency, global analytics operations continue seamlessly within a single warehouse instance.
Final Thoughts
Compliance regulations, with their stringent data residency stipulations, necessitate businesses to maintain rigorous standards for data localization, protection, privacy, and security. Adhering to these regulations is essential to mitigating the risks associated with breaches, penalties, and potential damage to reputation. However, enterprises operating in various global regions, serving diverse customer bases, are left to deal with the complex task of navigating multiple regulatory landscapes.
Using data privacy vaults as your core infrastructure for customer PII offers a streamlined solution to simplify global compliance, particularly concerning AWS services and cloud storage.
With a data privacy vault, organizations gain the ability to centralize the security of all sensitive data, effectively removing AWS and cloud storage from their compliance scope. By deploying data privacy vaults in various regions, companies can ensure that sensitive data storage and transmission align with the specific laws and regulations of each operational jurisdiction, thereby enhancing their overall compliance and security posture.
If you have thoughts on this or questions about this approach, please reach out to me on LinkedIn.

Top comments (0)