
AWS Redshift is the name of the data warehousing program provided by Amazon Web Services. Redshift excels at handling enormous volumes of data; it can handle both structured and unstructured data up to the exabyte level. Yet, the service may also be used for large-scale data migrations.
Like many other Amazon services, it provides a range of choices for importing data and can be set up in only a few clicks. For further security, Redshift's data is also continuously encrypted.
Redshift makes it easier to glean crucial insights from massive amounts of data. With the user-friendly Amazon interface, you can create a new cluster in a matter of minutes without having to worry about infrastructure upkeep.
Redshift features
Redshift is a column-oriented OLAP-style (Online Analytical Processing) database. On top of PostgreSQL, it is constructed. This means that Redshift may be used in conjunction with regular SQL queries. Yet this isn't what distinguishes it from other services. Redshift is notable for its lightning-fast replies to queries on enormous databases with exabytes of data.
Quick querying is made possible by the MPP, or massively parallel processing architecture. With MPP, several computer processors run at once to do the required calculations. On rare occasions, processors spread across many servers can deliver processes.
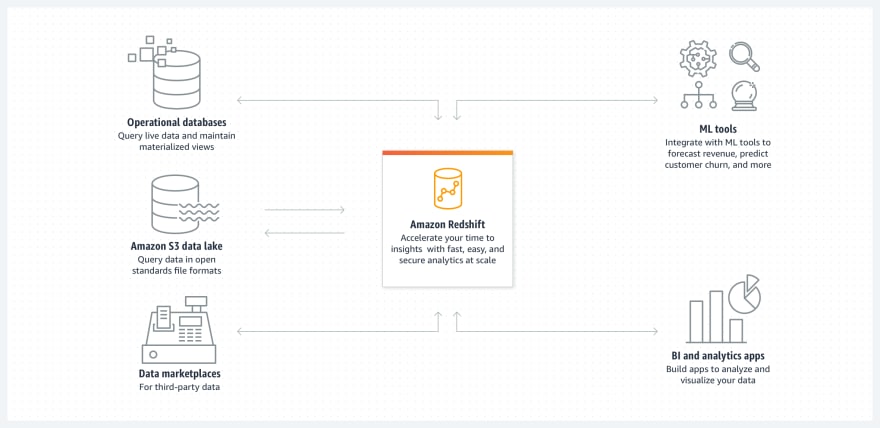
Redshift use-cases
Amazon When there is a ton of data large examine, Redshift is employed. For Redshift to be a practical option, the data must be at least one petabyte in size. Only at such size can Redshift make use of the MPP technology. There are several particular use cases that justify its utilization in addition to the amount of the data.
Data Warehouse
Even smaller businesses frequently use data from several sources, including CRM, customer service, and advertising. To provide a single source of truth, Redshift may be used as a central repository to store data from several sources in a uniform format and structure. This can then feed corporate reporting and analytics.
Analytics at real time
Real-time data must often be the basis for choices made by many businesses, and solutions must frequently be implemented fast. Uber is a good example.
Uber must act swiftly based on past and current data. It must make decisions on surge pricing, where to dispatch drivers, what route to follow, anticipated traffic, and a variety of other factors.
A firm like Uber, which has operations all over the world, must make thousands of these judgments each and every minute. It is necessary to process past data as well as the present stream of data in order to make such judgements and guarantee efficient operations. Redshift may be used in these situations as the MPP technology to speed up data access and processing.
Log analysis
A strong source of insightful data is behavior analytics. With the help of behavior analytics, you can learn how a user interacts with an application, how long they use it for, how many times they click, what sensors they use, and a whole lot more.
The information may be gathered from several sources, such as a web application utilized on a desktop, mobile phone, or tablet, and then compiled and analyzed to learn more about user behavior. Redshift may be used for this coalescence of computational data and complicated datasets.
Traditional data warehousing may also be done using Redshift. However, programs like the S3 data lake would probably be more appropriate in such a situation. Redshift may be used to manipulate data in S3 and store the results in S3 or Redshift.
Production data for development environments
One of the most prevalent obstacles in the development process is obtaining high-quality test data. Developers must frequently overcome obstacles such as significant administrative overhead for duplicating data, higher expenses from data duplication, lengthy downtime, and the danger of losing development artifacts while renewing test environments in order to keep access to high-quality test data.
The data sharing functionality allows Amazon Redshift development clusters to access high-quality production data directly from an Amazon Redshift production or pre-production cluster in a simple, secure, and cost-effective manner, resulting in a highly robust posture.
Business intelligence
An organization's data must be handled by a variety of employees. They are not all data scientists and are unlikely to be conversant with the programming tools used by engineers.
They may rely on detailed reports and information dashboards with simple interfaces. Redshift may be used to create highly functioning dashboards and automatic report generation. It is compatible with Amazon Quicksight as well as third-party solutions developed by AWS partners.
Benefits
The cost-benefit to your company is a highly distinguishing benefit of employing AWS Redshift. It is considerably less expensive (about one-twentieth the price of rivals like Teradata and Oracle).
Redshift has a variety of advantages in addition to being affordable.
Speed
The speed at which massive data sets may be produced is unmatched when MPP technology is used. No other cloud service provider can equal AWS's level of speed and affordability.
Encryption of data
For each aspect of Redshift operation, Amazon offers the option for data encryption. Which operations require encryption and which do not can be chosen by you, the user. An additional degree of protection is provided by data encryption.
Utilize tools you are accustomed to using
PostgreSQL is the foundation of Redshift. With it, all SQL queries function. You may also select any SQL, ETL (Extract, Transform, Load), and Business Intelligence (BI) technologies that you are comfortable using. The utilization of the resources offered by Amazon is optional.
Effective Optimization
There are several ways to query data using the same parameters for a huge data set. The degrees of data usage for the various instructions will vary. Tools and data are available through AWS Redshift to enhance inquiries. It will also offer guidance on how to automatically enhance the database. These can be used to do a task even more quickly and with less resources.
Automation
Automate routine work. Redshift includes features that allow you to automate processes.
API for Redshift
Redshift offers a strong API and thorough documentation. Using API tools, it may be used to send requests and return information. For simpler development, the API may also be utilized inside a Python application.
Security
The security of the cloud is managed by Amazon, and users are responsible for the security of the programmes that are hosted there. To provide an extra layer of security, Amazon offers provisions for access control, data encryption, and virtual private cloud.
Machine learning
Redshift predicts and analyzes requests using machine learning. Redshift performs better than competing products on the market thanks to this and MPP.
Simple Deployment You can launch a Redshift cluster from anywhere in the world.
Simple Deployment
In a matter of minutes, a Redshift cluster may be set up anywhere in the globe from any location. In a matter of minutes, you may have a high-performing data warehousing solution at a fraction of the cost set by rivals.
Regular backup
Amazon often does automated data backups. In the case that there are any errors, failures, or corruption, this can be utilized to restore. The backups are dispersed across many places. So the possibility of errors occurring at a location as a whole is eliminated.
Analytics by AWS
AWS has several analytical tools available. Redshift can coexist peacefully with all of them. Redshift may be integrated with various analytical tools thanks to help from Amazon. Redshift provides the ability to directly integrate with AWS analytics services.
Limitations
Prior to choosing Redshift as your data warehousing solution, it is important to take into account some of its disadvantages.
Multiple uploads
Not all databases are supported for concurrent upload by Redshift. Redshift supports ultra-fast MPP parallel uploads to Amazon S3, EMR, and DynamoDB. Data must be uploaded using different scripts for sources from various sources. This procedure could go quite slowly.
Uniqueness
One of the guiding principles of a database is the existence of unique data and the avoidance of redundancies. AWS Redshift doesn't offer any tools or ways to make sure that the data is unique. Redshift will include duplicate data points if overlapping data from several sources is being migrated there.
Indexing
When Redshift is utilized for data warehousing requirements, this creates a concern. Redshift
Summary
Redshift has reduced the cost of maintaining a data warehouse, which has increased the market that can be served. Redshift's low cost makes it possible to store event-level data, which opens up an entirely new range of use cases. Data-driven services that produce new income streams for businesses are among these use cases.





Latest comments (0)