NOTE: This article has associated with my article about Analytics on AWS — AWS Glue.
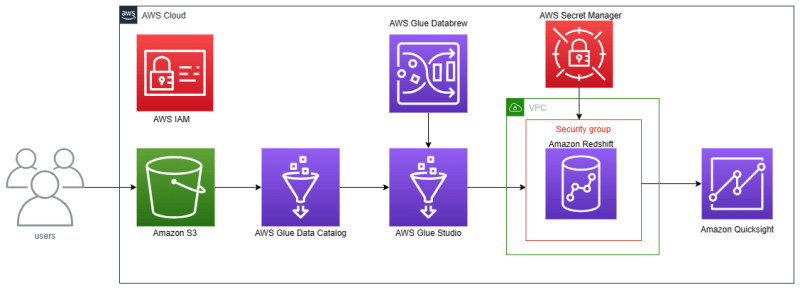
Hello everyone. I am Budi want to explain about Amazon Redshift. Amazon Redshift is an AWS service that serves data warehouses using SQL.
Amazon Redshift has several features like Redshift ML (create, train, and deploy machine learning models using SQL), Redshift Serverless (data warehouse without creating cluster/server), Redshift Streaming Ingestion (ingest real-time data with Amazon Kinesis), and many more.
Amazon Redshift also can connect to SQL Workbench, business intelligence tools like Tableau, Amazon Quicksight, and many more, and ETL tools like AWS Glue with JDBC or ODBC drivers.
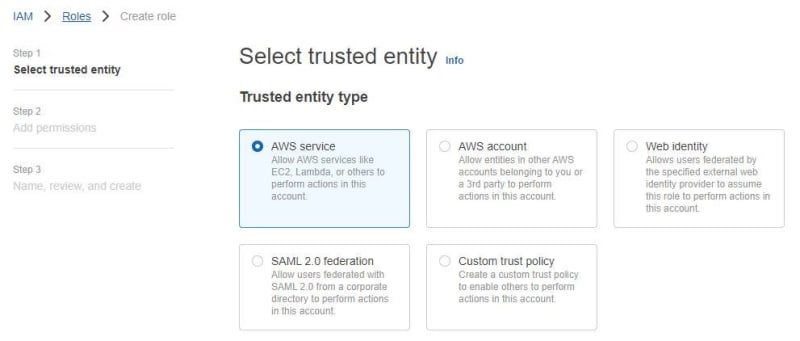
Before creating the Redshift cluster, the first created IAM role for Redshift. Go to Security, Identity, & Compliance section, and search IAM. Next click Roles. Click Create a role in IAM Roles.

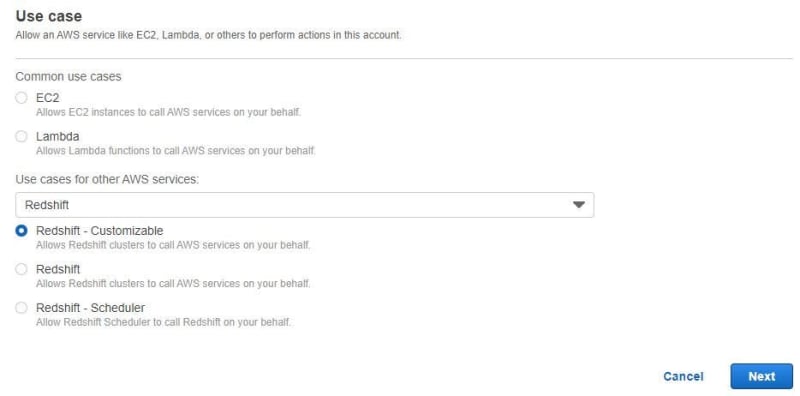
Choose AWS service then chooses Redshift — Customizable. Click Next.
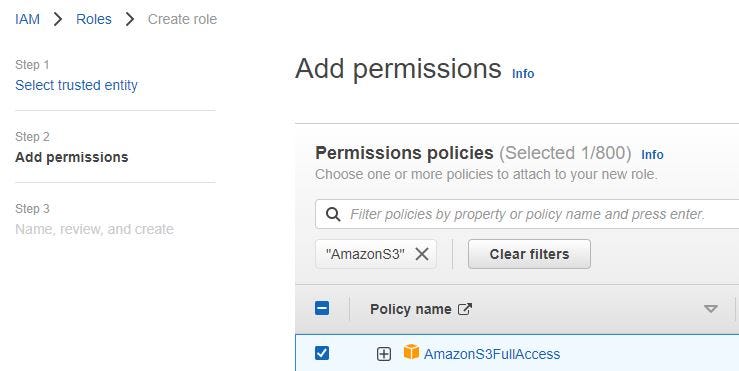
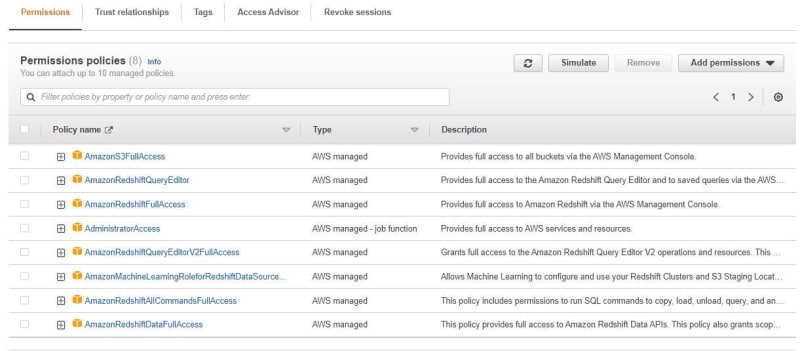
Add permissions to IAM role for Redshift. Filter Amazon S3, Amazon Redshift and click Next.
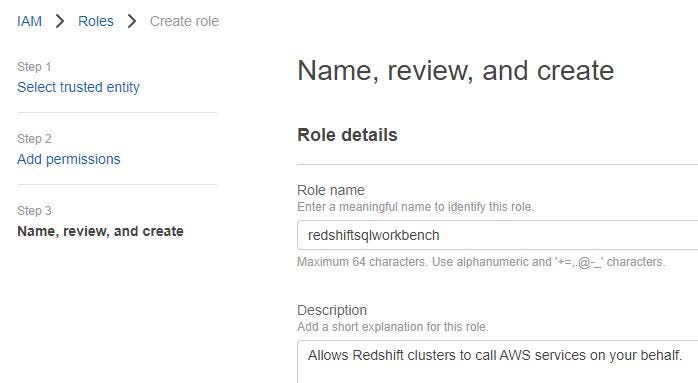
Fill in the IAM role name and click Create role.
After created IAM role for Redshift, you can see permissions policies that needed.
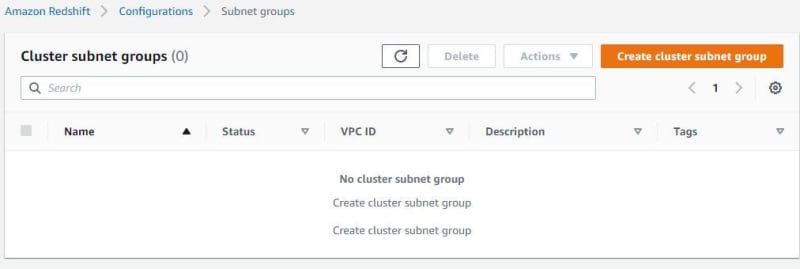
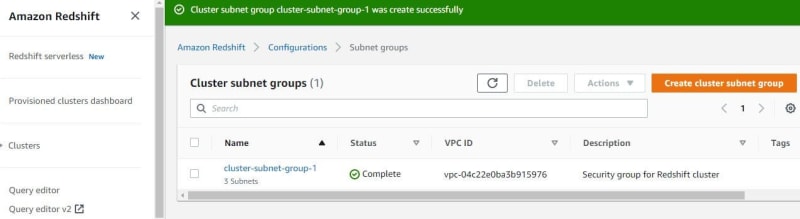
Go to Amazon Redshift. Before creating a Redshift cluster, create Redshift subnet groups to connect to VPC. Click subnet groups. Click cluster subnet group.

Fill in the subnet group name and description. Choose VPC for Redshift cluster. You can create VPC with this link.
Click Add all the subnets for this VPC. My VPC have 3 subnets. Then click create cluster subnet group.
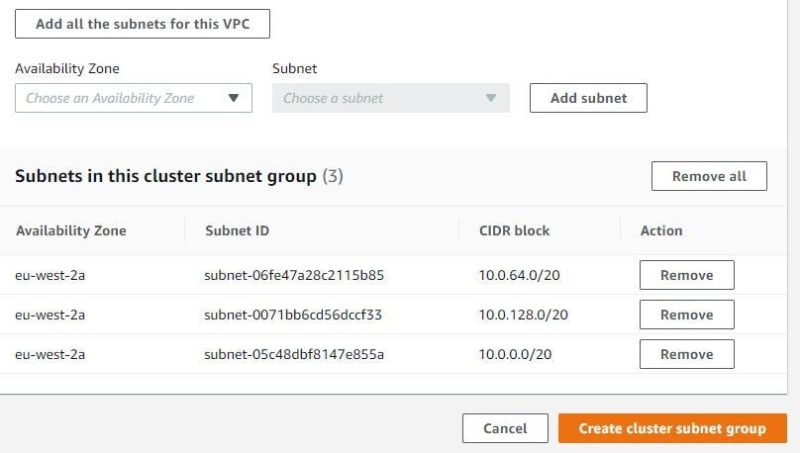
After creating a subnet group, the subnet group has connected to VPC that can be used to create a Redshift cluster.
Click provisioned clusters dashboard, click Create cluster. I want try Redshift Serverless but coming soon.
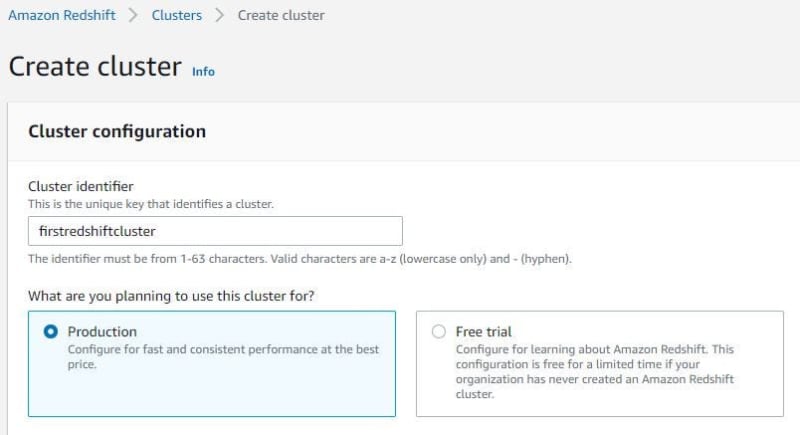
Fill in the cluster name. If you choose free trial, you cannot edit settings VPC and many more. Choose production.
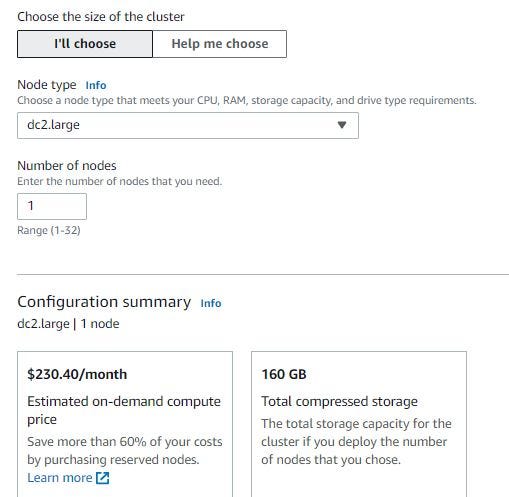
Choose dc2.large for the node type in the Redshift cluster. Btw, dc2.large is free for 2 months if you try the new Amazon Redshift.
Fill in the username and password for login when want query in Redshift cluster.
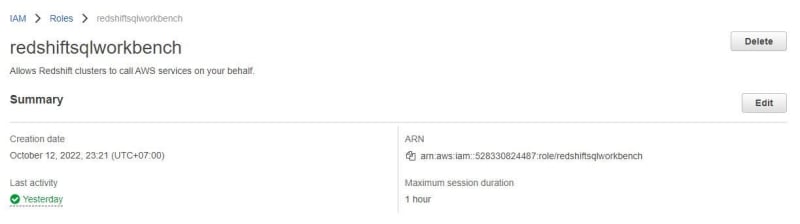
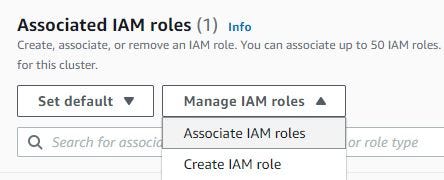
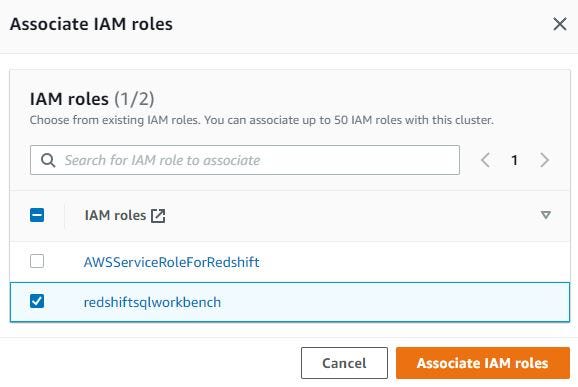
Click Associate IAM roles. Show pop-up IAM roles. Choose redshiftsqlworkbench that already created first and click Associate IAM roles again. The redshiftsqlworkbench IAM roles is default.
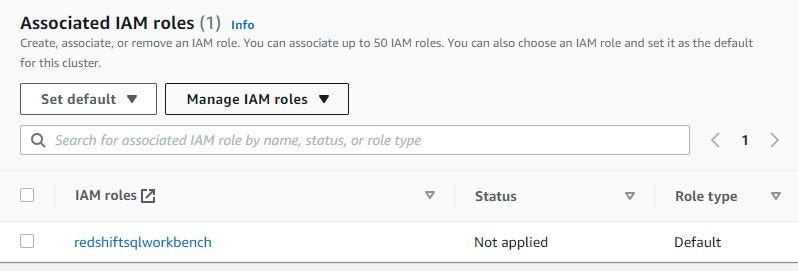
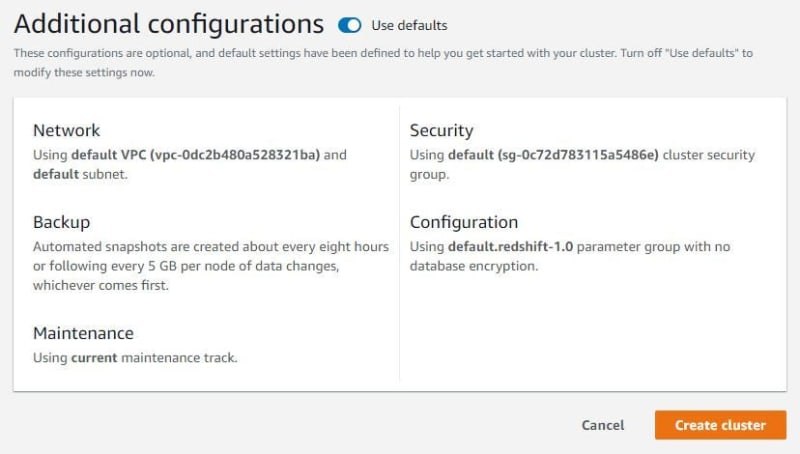
After disabled use defaults, choose VPC that connected to Redshift subnet group.
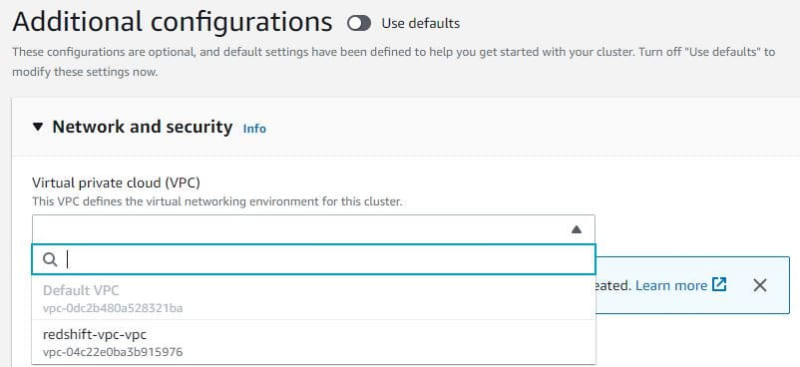
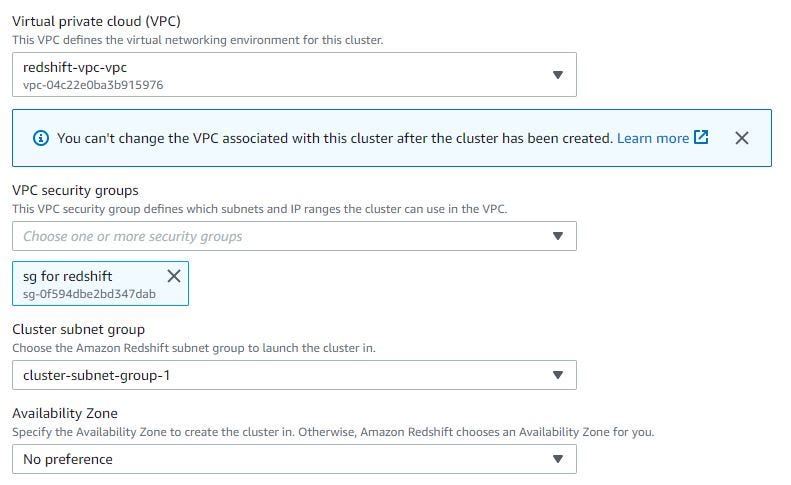
Choose VPC security groups for Redshift. To create VPC security groups, you can see this link. Choose Redshift cluster subnet group that already create first.
Fill in the database name and port.
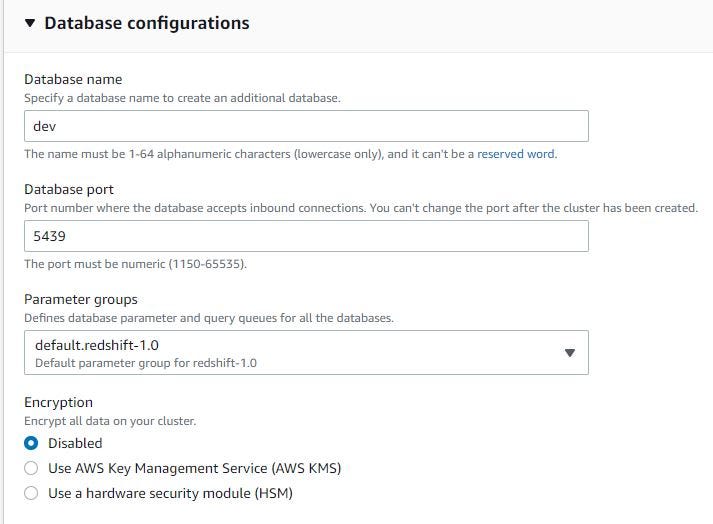
If need automated snapshot for backup, can fill 1–35 days. But if don’t need this, can fill 0 days.
Disabled for cross-region snapshot and cluster relocation. Click create cluster to next step.
Waiting Redshift cluster until the Redshift cluster is available. After the Redshift cluster is available, click the Redshift cluster name.
Click query in query editor version 1 or version 2. For this tutorial, choose version 1.
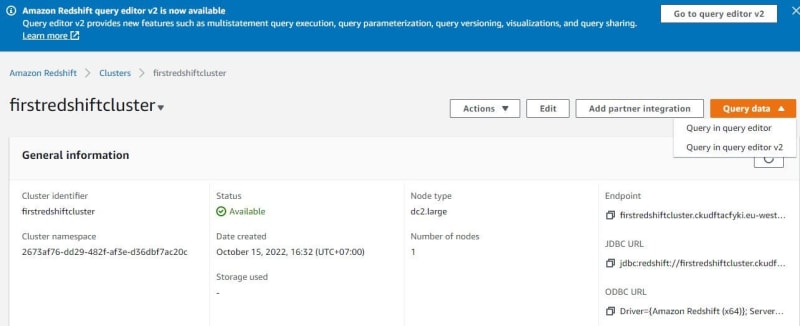
When want query, must connect to the database. Connecting to the database has 2 ways — temporary credentials and AWS Secret Manager. For this tutorial, use AWS Secret Manager.
Temporary credentials based on permissions granted through an AWS Identity and Access Management (IAM) permissions policy to manage the access that your users have to your Amazon Redshift database.
AWS Secret Manager is an AWS service that stores encrypted secrets such as database credentials (on Amazon RDS, Amazon Redshift, and many more) and API keys.
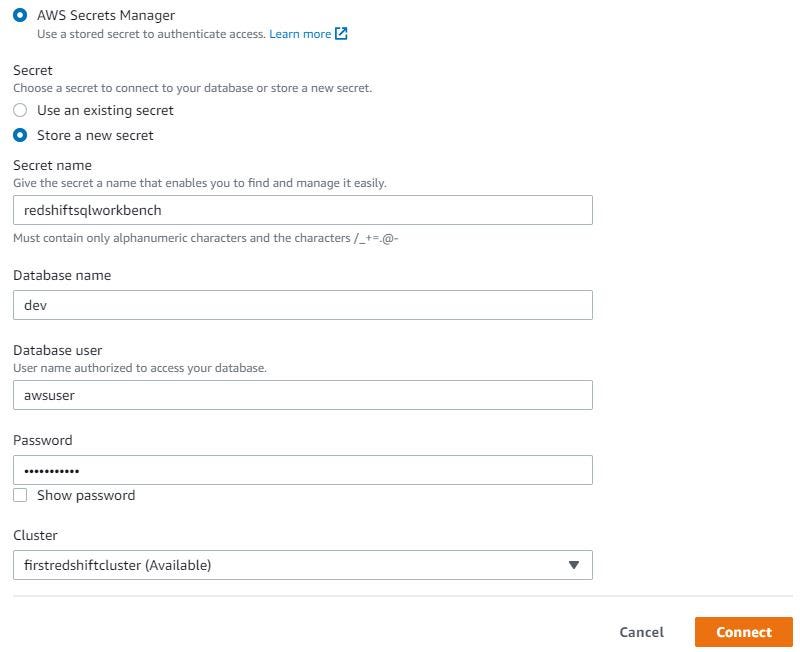
When using AWS Secret Manager, create a secret name. Fill in the database name, database user, and password that was already created when creating Redshift cluster. Then choose Redshift cluster to connect. Click Connect.
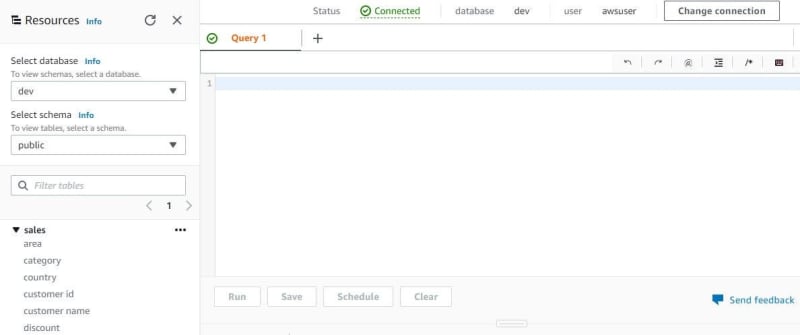
After connecting to the database, now can query with one table — sales from ETL jobs by AWS Glue.
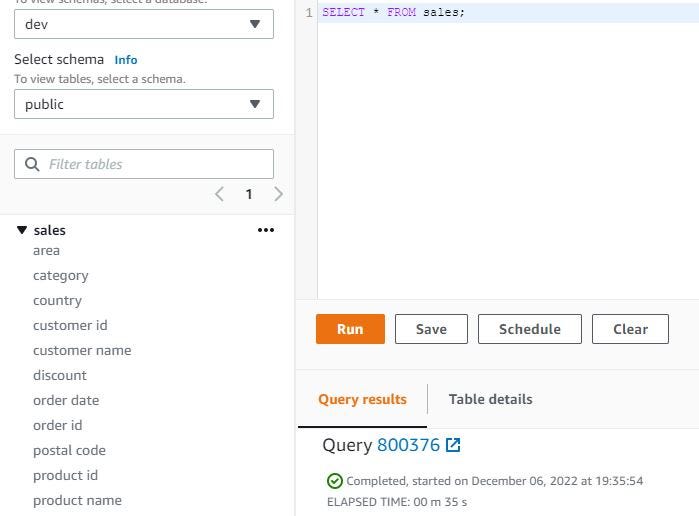
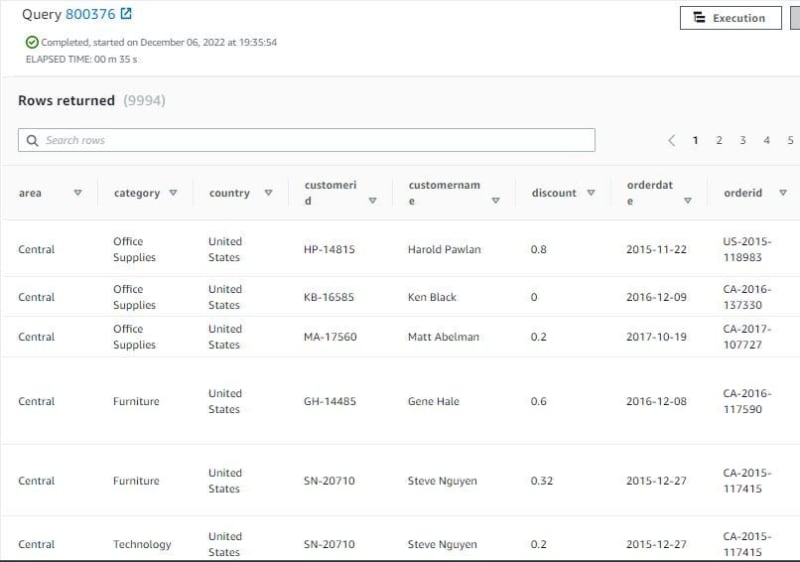
Query sales table. SELECT * FROM sales; need 35 seconds to query this table, show 9994 rows.
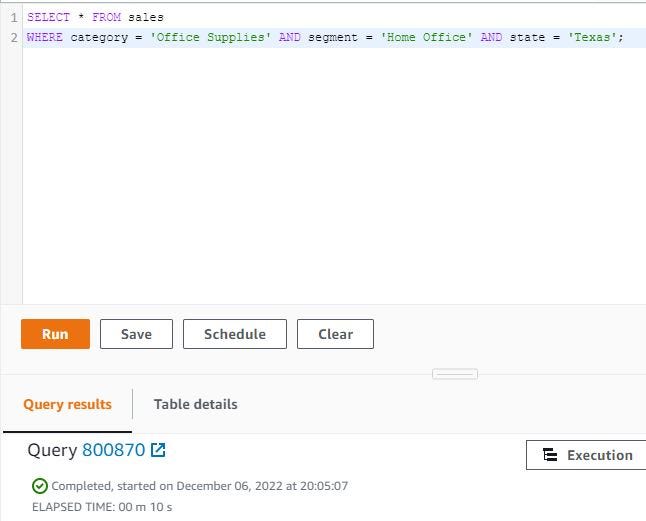
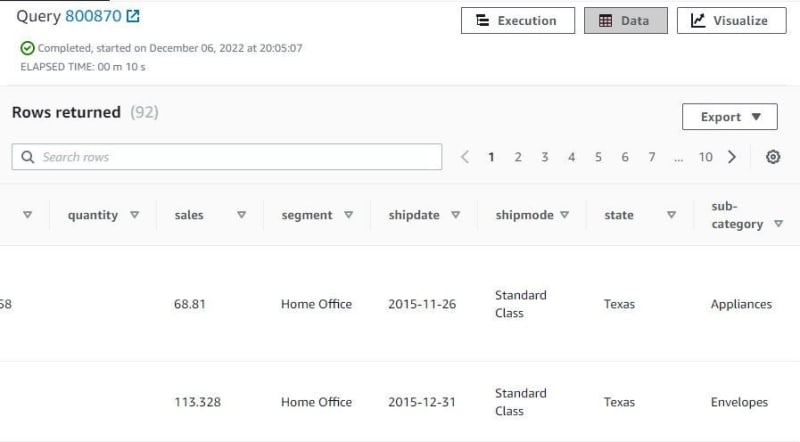
Query sales table with need specific column. Use category, segment and state columns. WHERE category = ‘Office Supplies’ AND segment = ‘Home Office’ AND state = ‘Texas’; need 10 seconds for query this table, show 92 rows because this query show office supplies, home office and Texas only.
If want delete sales table, write DROP TABLE dev.public.sales; click Run and wait until this table is deleted.
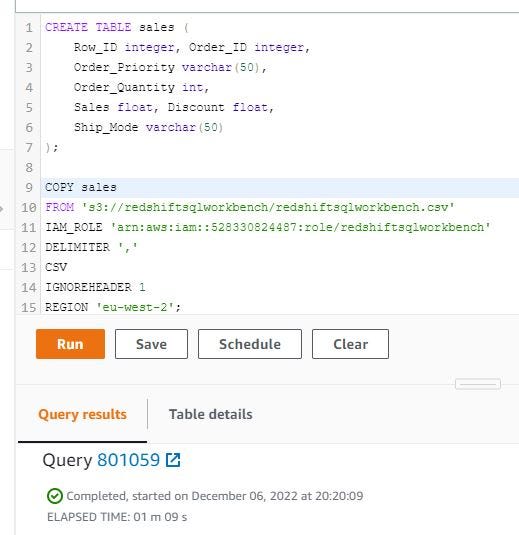
I want to copy the CSV file from Amazon S3 to Amazon Redshift with COPY command. Create a table with table name — sales and create schema and type data. COPY sales table from Amazon S3 CSV path, need IAM role for Redshift, delimiter comma, format file CSV, IGNOREHEADER to skip file headers in a CSV file and region when Redshift cluster is created. Then click Run and wait until finished. Need 69 seconds to process this query.
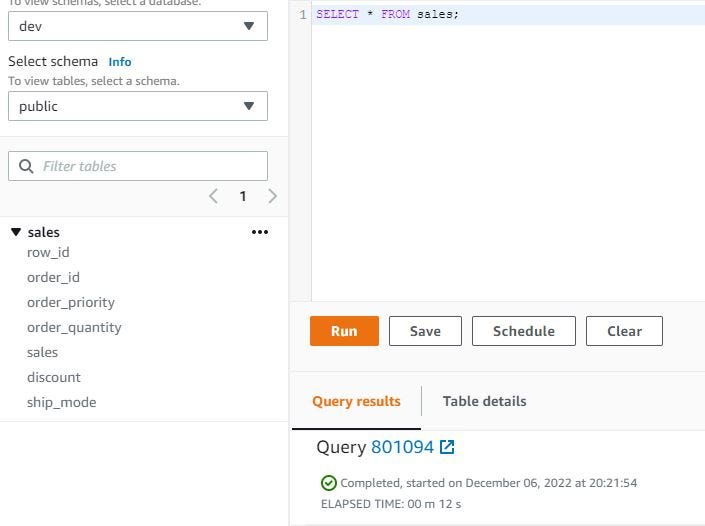
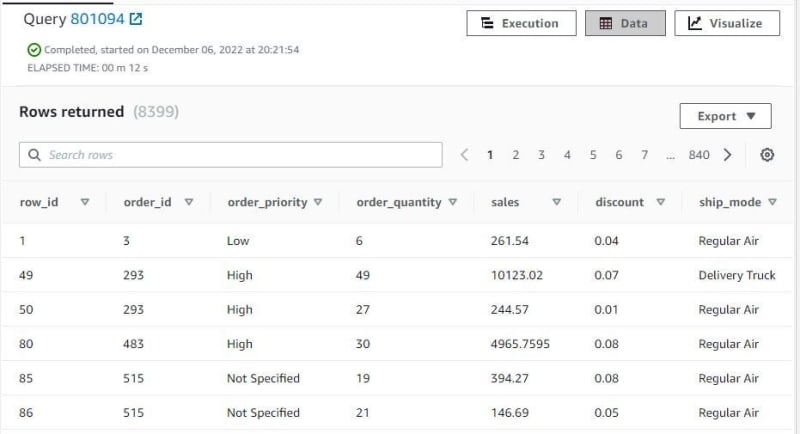
After processing previous query, try check with SELECT * FROM sales; need 12 seconds and show 8399 rows with 7 columns.
Thank you very much for reading this article/tutorial :)





Top comments (0)