
Some technologies have an aura of complexity. Not because of the complexity of use or configuration. Rather, because of the amount of complexity it hides beneath. The sales talk itself is so overwhelming, very few have the courage to go beyond that. However, if you do take that step forward, you are surprised by the simplicity.
Amazon Redshift is one such service. It just comes with too many acronyms and tech jargon. There is a lot that we can do with Redshift. It provides a clean interface to a rather complex architecture. It hides a lot of complexity underneath. But that does not complicate Redshift! This blog will help you understand the core concepts clearly enough to use Redshift in your architecture.
But before we start, let us have a look at some important concepts.
What is Redshift?
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. Now, what exactly is this data warehouse? Let us understand that before we jump in.
A data warehouse is the one central repository of ALL the data available within an enterprise. This may seem conflicting. We talk about DB per MS pattern in microservices. How then can we have one central repository of data? Well, that is the difference between analytics and transactions. Transactional data is split across several systems. And each of them pushes information into the data warehouse — for analysis.
Such data easily exceeds petabytes and that is when we use Redshift. If you have a small setup that barely generates a few KB per day, better not waste money on Redshift. Instead, dig within to find out why you are not generating more data.
Okay, does that mean Redshift is a database with a huge capacity? No! It is far more than a database. It is a complete solution that includes a humungous database, ready integrations, and a variety of tools to analyze such data.
A typical use case of Redis is an enterprise with several applications and components pushing a variety of data streams into the data warehouse — with an automated process analyzing such data — live or in retrospect.
Common Challenges
When we started working with data at such a scale, it brought in a lot of concerns that were not known before. A data warehouse requires a lot more than just database administration.
The volume, variety, and velocity of the incoming data can be really high. The enterprise requires high performance on queries and concurrent access to the data. That may not be just data scientists running SQL queries, to access the data. It could be batch processes on Spark clusters. The data warehouse should be able to sustain that load.
Another major source of complexity is privacy and security constraint. Data is no longer a casual asset. Compliances requirements are complex and the penalties for missing out on those compliances are too high to ignore.
We need Redshift to make productive use of the data while navigating through these challenges.
Quick Demo
Eager to jump over to the AWS console? So am I! Log in to the AWS console and open the Redshift console.
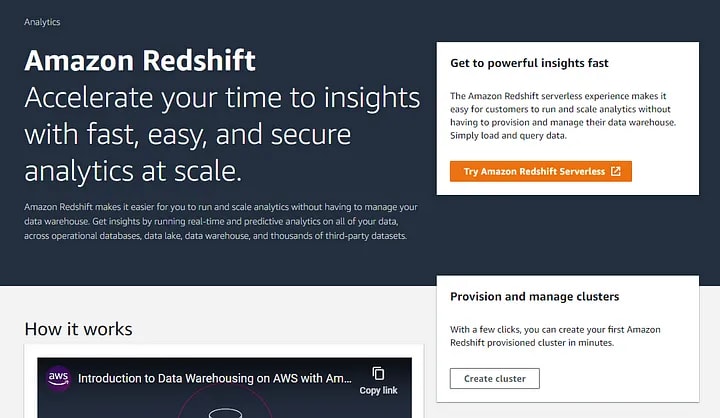
Redshift comes in two flavors — cluster and serverless. You can read volumes of literature on the internet — comparing servers and serverless and I do not want to repeat it here.
Just note one point. The Redshift Serverless is not as cheap as Lambda functions. It does provide a lot under the hood and so AWS will charge us for that. Redshift serverless is quite new at this time, and hence AWS gives us a $300 credit for using it without worrying about the costs. Please confirm that this is still true before you actually create the instance. You can also think of it as an investment toward learning Redshift.
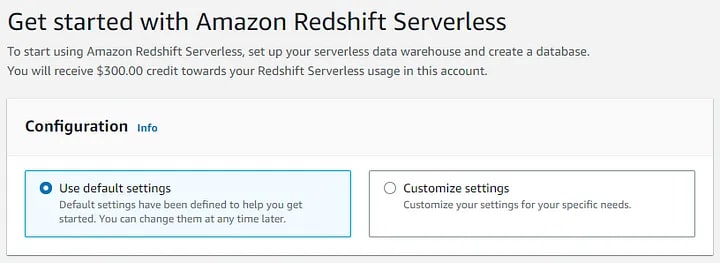
For now, leave everything at default and create it. It will take a couple of seconds. Open the Redshift serverless dashboard.
If you don’t see the default workgroup created, create one by clicking on the “Create workgroup” button.

Specify minimum RPU capacity and default namespace and accept all other defaults.

Click on Query Data to view the built-in data explorer. That is a utility tool for making SQL queries on the data in RedShift.

Expand the workgroup. It comes with some sample data. Click on the link for tickit.
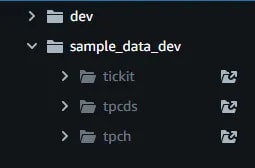
It will open a “tickit-sample-notebook” containing sample queries on the sample data. Try playing with it. Run some queries and view the results.
We can present the output of the query in a table, or also in a variety of graphical formats.
Reminds me of the good old SQL Developer!
More than That
That seems too simple to be useful! Is Redshift a simple relational database?
No way! It provides an SQL interface to the data. That does not mean that it is a relational database. It is way more than that. It can seamlessly connect to a variety of data sources and assimilate that data in a variety of forms. Yet, it covers all that complexity under the hood and allows us an easy interface to query it as if it was petty relational data.
Thus, Redshift provides a complete ecosystem for data analytics at scale. Redshift enables a real-time lakehouse approach, that can combine traditional data sources in relational databases, with event data in an object score like S3, as well as high-speed, real-time transactional data. It provides a common interface to query data.
The main value of Redshift is that we do not have to load all the data in Redshift in order to access it. We have a query federation model — so that the data could be in RDS, in S3 (parquet/CSV), or within Redshift. For the analyst, it is just tables and schemas. We now have a set of tables that map with data, wherever the data resides.
Redshift Architecture

Redshift has a “Massively parallel, shared-nothing architecture”. Let us understand what that means. There are three main types of nodes:
Leader node
This provides an SQL interface to all the data beneath. It coordinates the SQL processing across multiple compute nodes and data sources
Compute node
This is the fleet of nodes that contain the local columnar storage. They can execute queries in parallel. They do all the hard work of loading, unloading, backup, and restoring from S3.
Redshift spectrum
This fleet of nodes executes queries directly on the data lake — the data lying in the S3 in any of the open formats like CSV, JSON, parquet, etc.
Redshift automates most of the tuning, leaving very little responsibility for the analyst. It automates all table maintenance and also offers prescriptive recommendations.
With Redshift, all this complexity is buried under the familiar, traditional SQL interface of relational tables. We can create stored procedures, materialized views, and all that we have been doing for ages.





Top comments (1)
Great.. write-up. Thanks for sharing