Kibana and Elastic Search
[TOC]
What is Kibana?
Kibana is a data visualization and exploration tool used for log and time-series analytics, application monitoring, and operational intelligence use cases. It offers powerful and easy-to-use features such as histograms, line graphs, pie charts, heat maps, and built-in geospatial support. Also, it provides tight integration with Elasticsearch, a popular analytics and search engine, which makes Kibana the default choice for visualizing data stored in Elasticsearch.Kibana works in sync with Elasticsearch and Logstash which together forms the so called ELK stack.
What is ELK Stack?
ELK stands for Elasticsearch, Logstash, and Kibana. ELK is one of the popular log management platform used worldwide for log analysis. In the ELK stack, Logstash extracts the logging data or other events from different input sources. It processes the events and later stores them in Elasticsearch.
Kibana is a visualization tool, which accesses the logs from Elasticsearch and is able to display to the user in the form of line graph, bar graph, pie charts etc. The basic flow of ELK Stack is shown in the image here −

Logstash is responsible to collect the data from all the remote sources where the logs are filed and pushes the same to Elasticsearch. Elasticsearch acts as a database where the data is collected and Kibana uses the data from Elasticsearch to represent the data to the user in the form of bargraphs, pie charts, heat maps as shown below −

For a small-sized development environment, the classic architecture will look as follows:

However, for handling more complex pipelines built for handling large amounts of data in production, additional components are likely to be added into your logging architecture, for resiliency (Kafka, RabbitMQ, Redis) and security (nginx):

This is of course a simplified diagram for the sake of illustration
What is Elasticsearch
It is distributed document stores which means once the document is stored then it can be retrieved from any node of the cluster.
- default port for elasticsearch is 9201
- default port for kibana is 5600
It shows the data on real time basis, for example, day-wise or hourly to the user. Kibana UI is user friendly and very easy for a beginner to understand. The following table gives a direct comparison between these terms−


Every row in RDBMS has an unique row identifier and similarly we have unique document id in elasticsearch for every document.
Elastichsarch built on top of Lucene. Every shard is simply a Lucene index. Lucene index, if simplified, is the inverted index. Every Elasticsearch index is a bunch of shards or Lucene indices. When you query for a document, Elasticsearch will subquery all shards, merge results and return it to you. When you index document to Elasticsearch, the Elasticsearch will calculate in which shard document should be written using the formula
shard = hash(routing) % number_of_primary_shards
Key Concepts
In Elasticsearch terms, Index = Database, Type = Table, Document = Row.
The key concepts of Elasticsearch are as follow
- Node
- It refers to a single running instance of Elasticsearch.
- Cluster
- It is a collection of one or more nodes. Cluster provides collective indexing and search capabilities across all the nodes for entire data.
- Index
- It is a collection of different type of documents and their properties. Index also uses the concept of shards to improve the performance
- Document
- It is a collection of fields in a specific manner defined in JSON format. Every document belongs to a type and resides inside an index. Every document is associated with a unique identifier called the UID.
- Shard
- Indexes are horizontally subdivided into shards. This means each shard contains all the properties of document but contains less number of JSON objects than index. The horizontal separation makes shard an independent node, which can be store in any node.
- Replicas
- Elasticsearch allows a user to create replicas of their indexes and shards.
Checking that Elasticsearch is running
You can test that your Elasticsearch node is running by sending an HTTP request to port 9200 on localhost:
curl -X GET "localhost:9200/?pretty"
response will be as similar to following.
{
"name" : "BLR-AA202394",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "pYm2eSPlTh-EUo8hcVce2A",
"version" : {
"number" : "7.15.2",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "93d5a7f6192e8a1a12e154a2b81bf6fa7309da0c",
"build_date" : "2021-11-04T14:04:42.515624022Z",
"build_snapshot" : false,
"lucene_version" : "8.9.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
Rest API in EL
Every feature of Elasticsearch is exposed as a REST API:
- Index API – Used to document the Index
- Get API – Used to retrieve the document
- Search API – Used to submit your query and get the result
- Put Mapping API – Used to override default choices and define our own mapping
Elasticsearch has its own Query Domain Specific Language, where you specify the query in JSON format. Other queries can also be nested based on your need. Real projects require search on different fields by applying some conditions, different weights, recent documents, values of some predefined fields, and so on. All such complexity can be expressed through a single query.

Document analysis process by Elasticsearch
When a document request for indexing is received by elasticsearch, which in turn is handled by lucene, it converts the document in a stream of tokens. After tokens are generated, the same gets filtered by the configured filter. This entire process is called the analysis process, and is applied on every document that gets indexed.
One thing to learn from this is that the key to an efficient storage and retrieval process is the analysis process defined on the index, as per the application needs.
Sometime we also do
- stemming and this means we convert the word into root word and store in index (Ex: such words are population, populations)
- For synonym, we store single word rather than storing all the words (declined, reduced)
Remember that this same process of document normalization (during inverted index ) needs to be applied during document search query.

The analyzer can be custom or default one and this needs to be specified during Index creation. If the analyzer is not provided then EL uses default standard one.
Remember that, EL standard analyzer will not do do
- stemming (Running to Run)- process of converting word to root word
- stop word removal
Inverted Index
It uses a method called inverted index. Since we are talking about searching a term in a large collection of documents(aka collection of chapters in this case) we can use Inverted Indexes to solve this issue, and yes almost all books use these Inverted Indexes to make your life easier. Just like many other books "Team of Rivals" has inverted indexes at the end of the book as shown in this image.
An inverted index consists of a list of all the unique words that appear in any document, and for each word, a list of the documents in which it appears.

So after checking the Inverted indexes at the end of the book we know that "Baltimore" is mentioned on pages 629 and 630. So there are two parts in this searching for "Baltimore" in the lexicographically ordered Inverted Index list and fetching the pages based on the value of the index (here 629 and 630). The search time is very less for the term in the inverted index since in computing we actually use dictionaries(hash-based or search trees) to keep track of these terms
The purpose of an inverted index, is to store text in a structure that allows for very efficient and fast full-text searches. When performing full-text searches, we are actually querying an inverted index and not the JSON documents that we defined when indexing the documents.
An inverted index consists of all of the unique terms that appear in any document covered by the index.
Here is the diagram which shows a very simplified structure of an inverted index. Here we have separated stop words which are common ones and they also should be excluded from queries.
Post the analysis process, when the data is converted into tokens, these tokens are stored into an internal structure called inverted index. This structure maps each unique term in an index to a document. This data structure allows for faster data search and text analytics. All the attributes like term count, term position and other such attributes are associated with the term. Below is a sample visualization of how an inverted index may look like.
Post the tokens are mapped, document is stored on the disk. One can choose to store the original input of the document along with the analyzed document. The original input gets stored in a system field names "_source". Once can even choose to not analyze the input, and store the document without any analysis. The structure of the inverted index totally depends upon the analyzer chosen for indexing.

Another example:
Document 1: Elasticsearch is fast
Document 2: I want to learn Elasticsearch
Let’s take a peek into the Inverted Index and see the result of the Analysis and Indexing process:
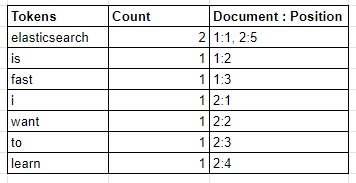
As you can see, the terms are counted and mapped into document identifiers and its position in the document. The reason we don’t see the full document Elasticsearch is fast or I want to learn Elasticsearch is because they go through Analysis process, which is our main topic in this article.
Operation with Elasticsearch
- Inserting a document in elasticsearch means Indexing a document
When you execute the PUT command for the fresh document, Then the document will be created. Such a case result attribute from the response will incite as “created”. When you execute the PUT command for the
second time for the same document, it will not create the new document again if the document already exists in the cluster. Instead, it will update the document. You can confirm that by the result from the
response. The result will indicate as “updated”. But when you execute the PUT command for the fresh document, Then the document will be created. If it's already available, then the document will be updated.
What is indexing
Index as a verb
The process of inserting a document into elasticsearch is called indexing. Indexing a document into elasticsearch is similar to insert the row in a database table. The only difference is, if the document already exists in the cluster, the indexing process will replace the old document.
Indexing a document from Kibana
Before indexing a document into kibana, first we need to decide where this document will be stored. In elasticsearch, a document belongs to a type and the type stays within an Index. An elasticearch cluster may contain multiple indexes and V7 allows only one type for per index. One index which belong to one type, may contain multiple documents and each document may have multiple fields.
Base command for an indexing a document is
{{host}}/:index/_alias/:alias
Here is a sample indexing which will create the index and have document added. I have also added following index pattern into elasticsearch.yml to enable auto indexing.
action.auto_create_index: .monitoring*,.watches,.triggered_watches,.watcher-history*,.ml*,.doc*,.json*,_json*,_doc*,*subscriber*,*product*,*event*
Note: Passing _doctype value (here it is json) is deprecated into current V7.
Indexing request:
Here intentionally i have used PUT request as this one requires ID value to be provided. My aim is here is to search by subscriberId and hence I am passing the ID value. Otherwise we can use POST command like “ POST /subscriber/json/” which will be auto generate id.
PUT /subscriber/json/5159683
{
"Addresses": [
{
"City": "TX",
"Country": "USA",
"LineOne": "Parkway Suite Houston",
"PostalCode": "77047",
"State": "TX",
"DefaultBilling": true,
"DefaultHome": false,
"DefaultPostal": true,
"DefaultService": true,
"DefaultShipping": false,
"DefaultWork": false,
"Id": 1412213,
"Created": "2021-11-22T16:05:40.943Z",
"Modified": "2021-11-22T16:05:40.943Z",
"Name": "Parkway E Suite Houston",
"ShipToName": "India",
"Status": 1,
"StatusName": "Active",
"TaxPCode": null,
"Verifiable": true,
"Verified": true
}
],
"Subscriber": {
"Category": 1,
"CompanyName": "IH-163759714",
"ConvergentBillerId": "40003771",
"Created": "2021-11-22T16:05:40.890Z",
"ExternalReference": "IH-EX163759714",
"Id": 5159683,
"Language": "en-GB",
"Login": "aa@mallinator.com",
"State": 0,
"StateChangeDate": "2021-11-22T16:05:40.840Z",
"Status": 1,
"SubscriberTypeCode": 10121,
"AdditionalProperties": [
{
"ExternalReference": "Invoice_Ref",
"Id": 1886,
"Name": "CustomerInvoiceRef",
"Values": []
},
{
"ExternalReference": "Bill_From_Address",
"Id": 1888,
"Name": "BillFromAddress",
"Values": [
"add-sws"
]
}
],
"ContactPreferences": [
{
"ContactEventType": 12,
"ContactMethod": 40,
"Id": 2702216,
"OptIn": true
}
],
"EffectiveStartDate": "2021-11-22T16:05:40.863Z",
"HomeCountry": "USA",
"InvoiceConfiguration": {
"HideZeroAmount": false,
"InvoiceDetailLevel": 1
},
"StateName": "Prospect",
"StatusName": "Active",
"SubscriberCurrency": "USD",
"SubscriberTypeDetails": {
"AccountingMethod": 2,
"BillCycle": "40002163",
"BillCycleDay": 1,
"BillCycleName": "BillCycle_1",
"IsReadOnly": false,
"PaymentDueDays": 10,
"PostpaidAccountNumber": "CAQ400037719"
},
"TermsAndConditionsAccepted": "2021-11-22T16:05:40.883Z"
}
}
Indexing response:
- here the type has been set with our input value
- index has been set to our input subscriber
- result value has set as created
- sequence no has ben set as 3 and this is being set by elasticsearch
#! [types removal] Specifying types in document index requests is deprecated, use the typeless endpoints instead (/{index}/_doc/{id}, /{index}/_doc, or /{index}/_create/{id}).
{
"_index" : "subscriber",
"_type" : "json",
"_id" : "5159684",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1
}
Here is the request when i passed on the input for an existing id and result value shows as updated which means the indexing has been updated. version has been set to 3 and this means the document has been updated 3 times. Every document in elasticsearch has version. So PUT request for existing document will update the version and for new request it will create
The _index mentions the index name for this document.
Any attribute starts with _ with document are called document metadata.
#! [types removal] Specifying types in document index requests is deprecated, use the typeless endpoints instead (/{index}/_doc/{id}, /{index}/_doc, or /{index}/_create/{id}).
{
"_index" : "subscriber",
"_type" : "json",
"_id" : "5159683",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}
Finding if a document available?
The HEAD command is being used to see if the document is available and this will respond us http 200 as shared below.
HEAD /subscriber/_doc/5159685
200 - OK
Retrieve an Index document
Here we are passing the Index name, document type and Id to retrieve the index.
GET /subscriber/json/5159685
and response will have the document along with its metadata. The found has value set to true which means the document has been found.
{
"_index" : "subscriber",
"_type" : "json",
"_id" : "5159685",
"_version" : 1,
"_seq_no" : 7,
"_primary_term" : 1,
"found" : true,
"_source" : {
"Addresses" : [
{
"City" : "TX",
"Country" : "USA",
"LineOne" : "Parkway E Suite Houston",
"PostalCode" : "77047",
"State" : "TX",
"DefaultBilling" : true,
"DefaultHome" : false,
"DefaultPostal" : true,
"DefaultService" : true,
"DefaultShipping" : false,
"DefaultWork" : false,
"Id" : 1412213,
"Created" : "2021-11-22T16:05:40.943Z",
"Modified" : "2021-11-22T16:05:40.943Z",
"Name" : "Parkway E Suite 100 Houston",
"ShipToName" : "MARLINK GROUP USA - HOUSTON",
"Status" : 1,
"StatusName" : "Active",
"TaxPCode" : null,
"Verifiable" : true,
"Verified" : true
}
],
"Subscriber" : {
"Category" : 1,
"CompanyName" : "IH1-163759714",
"ConvergentBillerId" : "400033771",
"Created" : "2021-11-22T16:05:40.890Z",
"ExternalReference" : "IH-EX163759714",
"Id" : 5159685,
"Language" : "en-GB",
"Login" : "IH16375339714@aaar.com",
"State" : 0,
"StateChangeDate" : "2021-11-22T16:05:40.840Z",
"Status" : 1,
"SubscriberTypeCode" : 10121,
"AdditionalProperties" : [
{
"ExternalReference" : "Invoice_Ref",
"Id" : 1886,
"Name" : "CustomerInvoiceRef",
"Values" : [ ]
},
{
"ExternalReference" : "Bill_From_Address",
"Id" : 1888,
"Name" : "BillFromAddress",
"Values" : [
"xxxx"
]
}
],
"ContactPreferences" : [
{
"ContactEventType" : 12,
"ContactMethod" : 40,
"Id" : 2702216,
"OptIn" : true
}
],
"EffectiveStartDate" : "2021-11-22T16:05:40.863Z",
"HomeCountry" : "USA",
"InvoiceConfiguration" : {
"HideZeroAmount" : false,
"InvoiceDetailLevel" : 1
},
"StateName" : "Prospect",
"StatusName" : "Active",
"SubscriberCurrency" : "USD",
"SubscriberTypeDetails" : {
"AccountingMethod" : 2,
"BillCycle" : "40002163",
"BillCycleDay" : 1,
"BillCycleName" : "BillCycle_1",
"IsReadOnly" : false,
"PaymentDueDays" : 10,
"PostpaidAccountNumber" : "CAQ400037719"
},
"TermsAndConditionsAccepted" : "2021-11-22T16:05:40.883Z"
}
}
}
Updating an Index document
Having a PUT request for an ID will update if the document is already existing. The response will have result as updated.
Note that PUT request will update the whole document with new content and that means our new PUT request needs to contain all the elements. PUT request update the complete document.
If we want to update partially and don't want pass on all document elements then we should use POST request. POST request update the relevant element only.
Key point to note here are:
- POST command has _update to let elasticsearch know about update
- doc keyword has to be added as elastic search stores documents within doc
- if we provide any new attribute into post request then it will be added into document.
- Following logic gets triggered by elasticsearch after post request
- retrieves the existing document
- apply changes requested in post request
- removes the old document
- indexes new document (with update) in the place of old document
POST /subscriber/_update/5159683
{
"doc":
{
"Addresses": [
{
"City": "Austin"
}
]
}
}
Deleting an document
Request is similar to get request
DELETE /subscriber/json/5159699
The response will have result element populated with deleted value.
{
"_index" : "subscriber",
"_type" : "json",
"_id" : "5159699",
"_version" : 2,
"result" : "deleted",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 33,
"_primary_term" : 2
}
Bulk Insert
For bulk request, individual items are separated by newline characters (not commas) and th*ere are no square brackets at the end (ie the payload is a sequence of JSON documents*. The documents must be on a single line, no newlines are allowed within them. It seems bit unintuitive I know since resources don't have to be on a single line when you create them using PUT or POST for non-bulk operations
POST _bulk
{"index": {"_index": "subscriber", "_id": "5159199"}}
{"Subscriber": {"Category": 1, "CompanyName": "IH-163759714","ConvergentBillerId": "40003771", "Created": "2021-11-22T16:05:40.890Z","ExternalReference": "IH-EX163759714","Id": 5159199,"Language": "en-GB","Login": "1@1.com","State": 0, "StateChangeDate": "2021-10-22T16:05:40.840Z","Status": 1,"SubscriberTypeCode": 10121}}
{"index": {"_index": "subscriber", "_id": "5159099"}}
{"Subscriber": {"Category": 1, "CompanyName": "IH-163759714","ConvergentBillerId": "40003771", "Created": "2021-11-22T16:05:40.890Z","ExternalReference": "IH-EX163759714","Id": 5159099,"Language": "en-GB","Login": "1@1.com","State": 0, "StateChangeDate": "2021-10-22T16:05:40.840Z","Status": 2,"SubscriberTypeCode": 10122}}
Bulk insert response will return status of each document insert as shared below.
- status code will be set to 201
{
"took" : 20,
"errors" : false,
"items" : [
{
"index" : {
"_index" : "subscriber",
"_type" : "_doc",
"_id" : "5159199",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 34,
"_primary_term" : 2,
"status" : 201
}
},
{
"index" : {
"_index" : "subscriber",
"_type" : "_doc",
"_id" : "5159099",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 35,
"_primary_term" : 2,
"status" : 201
}
}
]
}
Bulk update
Here i am updating all the attributes of the documents.
POST _bulk
{"index": {"_index": "subscriber", "_id": "5159199"}}
{"Subscriber": {"Category": 1, "CompanyName": "IH-163759714","ConvergentBillerId": "40003771", "Created": "2021-11-22T16:05:40.890Z","ExternalReference": "IH-EX163759714","Id": 5159199,"Language": "en-GB","Login": "1@1.com","State": 1, "StateChangeDate": "2021-10-22T16:05:40.840Z","Status": 1,"SubscriberTypeCode": 10121}}
{"index": {"_index": "subscriber", "_id": "5159099"}}
{"Subscriber": {"Category": 1, "CompanyName": "IH-163759714","ConvergentBillerId": "40003771", "Created": "2021-11-22T16:05:40.890Z","ExternalReference": "IH-EX163759714","Id": 5159099,"Language": "en-GB","Login": "1@1.com","State": 1, "StateChangeDate": "2021-10-22T16:05:40.840Z","Status": 2,"SubscriberTypeCode": 10122}}
The response has status code set to 200 as shared below.
{
"took" : 9,
"errors" : false,
"items" : [
{
"index" : {
"_index" : "subscriber",
"_type" : "_doc",
"_id" : "5159199",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 36,
"_primary_term" : 2,
"status" : 200
}
},
{
"index" : {
"_index" : "subscriber",
"_type" : "_doc",
"_id" : "5159099",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 37,
"_primary_term" : 2,
"status" : 200
}
}
]
}
Full text Search basics of Elasticsearch
Note: Whatever analyzer was using during Index creation, the same will be used during query operation. Every query term goes through analysis process.
English analyzer in EL does following
- does tokenization based on white space
- does stemming
- removes stop words
Getting a document by Id
GET /subscriber/_doc/5159199
The response has found set to true as shared below which indicate that the id has been found. The original document is found under metadata "_source".
{
"_index" : "subscriber",
"_type" : "_doc",
"_id" : "5159199",
"_version" : 2,
"_seq_no" : 36,
"_primary_term" : 2,
"found" : true,
"_source" : {
"Subscriber" : {
"Category" : 1,
"CompanyName" : "IH-163759714",
"ConvergentBillerId" : "40003771",
"Created" : "2021-11-22T16:05:40.890Z",
"ExternalReference" : "IH-EX163759714",
"Id" : 5159199,
"Language" : "en-GB",
"Login" : "1@1.com",
"State" : 1,
"StateChangeDate" : "2021-10-22T16:05:40.840Z",
"Status" : 1,
"SubscriberTypeCode" : 10121
}
}
}
Searching an Index
The following one will allow to search for all documents into the index.
GET /subscriber/_search
The search result will have following metadata and element hits.value.total will indicate how many documents been returned. Here timed_out set to false and this means request has not been timed out. the default timeout set to is 60 sec and we can specify this value in the request also to override the default value.
The value max_score equal to 1.0 means all the search results are relevant to search query.
{
"took": 11,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 12,
"relation": "eq"
},
"max_score": 1.0,
"hits": [{
"_index": "subscriber",
"_type": "json",
"_id": "5159698",
"_score": 1.0,
"_source": {
..........
}
}
]
}
}
Searching by query string
we can pass on query string as shown below accompanied by q. Here elasticsearch is searching all the documents for the value 10122 irrespective of the field.
GET /subscriber/_search?q="10122"
The response has relation field value set to eq which means search happened with document string compare. The search result is ordered by _score and 1st one has _score se to 2/302585 as it had maximum time of query string 10122 match found.
{
"took" : 429,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 6,
"relation" : "eq"
},
"max_score" : 2.302585,
"hits" : [
{
"_index" : "subscriber",
"_type" : "json",
"_id" : "49",
"_score" : 2.302585,
"_source" : {
"Subscriber" : {
"Category" : 1,
"CompanyName" : "IH-10122",
"ConvergentBillerId" : "10122",
"Created" : "2021-11-22T16:05:40.890Z",
"ExternalReference" : "IH-EX163759714",
"Id" : 49,
"Language" : "en-GB",
"Login" : "1@1.com",
"State" : 1,
"StateChangeDate" : "2021-10-22T16:05:40.840Z",
"Status" : 1,
"SubscriberTypeCode" : 10121
}
}
},
{
"_index" : "subscriber",
"_type" : "json",
"_id" : "79",
"_score" : 1.7917595,
"_source" : {
"Subscriber" : {
"Category" : 1,
"CompanyName" : "IH-163759714",
"ConvergentBillerId" : "10122",
"Created" : "2021-11-22T16:05:40.890Z",
"ExternalReference" : "IH-EX163759714",
"Id" : 79,
"Language" : "en-GB",
"Login" : "1@1.com",
"State" : 1,
"StateChangeDate" : "2021-10-22T16:05:40.840Z",
"Status" : 2,
"SubscriberTypeCode" : 10122
}
}
},
{
"_index" : "subscriber",
"_type" : "json",
"_id" : "5159099",
"_score" : 1.0,
"_source" : {
"Subscriber" : {
"Category" : 1,
"CompanyName" : "IH-163759714",
"ConvergentBillerId" : "40003771",
"Created" : "2021-11-22T16:05:40.890Z",
"ExternalReference" : "IH-EX163759714",
"Id" : 5159099,
"Language" : "en-GB",
"Login" : "1@1.com",
"State" : 1,
"StateChangeDate" : "2021-10-22T16:05:40.840Z",
"Status" : 2,
"SubscriberTypeCode" : 10122
}
}
},
{
"_index" : "subscriber",
"_type" : "json",
"_id" : "59099",
"_score" : 1.0,
"_source" : {
"Subscriber" : {
"Category" : 1,
"CompanyName" : "IH-163759714",
"ConvergentBillerId" : "40003771",
"Created" : "2021-11-22T16:05:40.890Z",
"ExternalReference" : "IH-EX163759714",
"Id" : 59099,
"Language" : "en-GB",
"Login" : "1@1.com",
"State" : 1,
"StateChangeDate" : "2021-10-22T16:05:40.840Z",
"Status" : 2,
"SubscriberTypeCode" : 10122
}
}
},
{
"_index" : "subscriber",
"_type" : "json",
"_id" : "599",
"_score" : 1.0,
"_source" : {
"Subscriber" : {
"Category" : 1,
"CompanyName" : "IH-163759714",
"ConvergentBillerId" : "40003771",
"Created" : "2021-11-22T16:05:40.890Z",
"ExternalReference" : "IH-EX163759714",
"Id" : 599,
"Language" : "en-GB",
"Login" : "1@1.com",
"State" : 1,
"StateChangeDate" : "2021-10-22T16:05:40.840Z",
"Status" : 2,
"SubscriberTypeCode" : 10122
}
}
},
{
"_index" : "subscriber",
"_type" : "json",
"_id" : "19",
"_score" : 1.0,
"_source" : {
"Subscriber" : {
"Category" : 1,
"CompanyName" : "IH-163759714",
"ConvergentBillerId" : "40003771",
"Created" : "2021-11-22T16:05:40.890Z",
"ExternalReference" : "IH-EX163759714",
"Id" : 19,
"Language" : "en-GB",
"Login" : "1@1.com",
"State" : 1,
"StateChangeDate" : "2021-10-22T16:05:40.840Z",
"Status" : 2,
"SubscriberTypeCode" : 10122
}
}
}
]
}
}
Searching by specific element of document
We can pass document element name into query string and this will return all the documents matching with the value of the specific field.
GET /subscriber/_search?q=SubscriberTypeCode:"10121"
The response will have max_score value of 1 for all the returned elements as this is value compare by element name.
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "subscriber",
"_type" : "json",
"_id" : "149",
"_score" : 1.0,
"_source" : {
"Category" : 1,
"CompanyName" : "IH-10122",
"ConvergentBillerId" : "12",
"Created" : "2021-11-22T16:05:40.890Z",
"ExternalReference" : "IH-EX163759714",
"Id" : 149,
"Language" : "en-GB",
"Login" : "1@1.com",
"State" : 1,
"StateChangeDate" : "2021-10-22T16:05:40.840Z",
"Status" : 1,
"SubscriberTypeCode" : 10121
}
},
{
"_index" : "subscriber",
"_type" : "json",
"_id" : "139",
"_score" : 1.0,
"_source" : {
"Category" : 1,
"CompanyName" : "IH-10122",
"ConvergentBillerId" : "12",
"Created" : "2021-11-22T16:05:40.890Z",
"ExternalReference" : "IH-EX163759714",
"Id" : 139,
"Language" : "en-GB",
"Login" : "1@1.com",
"State" : 1,
"StateChangeDate" : "2021-10-22T16:05:40.840Z",
"Status" : 1,
"SubscriberTypeCode" : 10121
}
}
]
}
}
Query DSL
If we see the above query curl command then it is as below and the curl command has the query in the url which can be exploited by hackers.
curl -XGET "http://localhost:9200/subscriber/_search?q=SubscriberTypeCode:"10121""
So instead of passing query into url, we will pass the query into the body which is more secured. All query of EL will be under query string and here is one example of match query where value is being compared.
GET /subscriber/_search
{
"query":
{
"match": {
"SubscriberTypeCode": "10122"
}
}
}
match
Now, lets see the corresponding curl command for this query dsl one and the url does not have any more id or field details. So query is specified in request body instead of url.
curl -XGET "http://localhost:9200/subscriber/_search" -H 'Content-Type: application/json' -d'
{
"query":
{
"match": {
"SubscriberTypeCode": "10122"
}
}
}'
Now, lets see the following query and its response below. The field value is being sent in lower case but still the query returned result. This is because during indexing, EL does the analysis process first which involves converting into lower case, stemming, root word etc.
GET /subscriber/_search
{
"query":
{
"match": {
"ExternalReference": "ih-EX163759714"
}
}
}
and the response of the above query
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 0.21072102,
"hits" : [
{
"_index" : "subscriber",
"_type" : "json",
"_id" : "149",
"_score" : 0.21072102,
"_source" : {
"Category" : 1,
"CompanyName" : "IH-10122",
"ConvergentBillerId" : "12",
"Created" : "2021-11-22T16:05:40.890Z",
"ExternalReference" : "IH-EX163759714",
"Id" : 149,
"Language" : "en-GB",
"Login" : "1@1.com",
"State" : 1,
"StateChangeDate" : "2021-10-22T16:05:40.840Z",
"Status" : 1,
"SubscriberTypeCode" : 10121
}
},
{
"_index" : "subscriber",
"_type" : "json",
"_id" : "179",
"_score" : 0.21072102,
"_source" : {
"Category" : 1,
"CompanyName" : "IH-163759714",
"ConvergentBillerId" : "16",
"Created" : "2021-11-22T16:05:40.890Z",
"ExternalReference" : "IH-EX163759714",
"Id" : 179,
"Language" : "en-GB",
"Login" : "1@1.com",
"State" : 1,
"StateChangeDate" : "2021-10-22T16:05:40.840Z",
"Status" : 2,
"SubscriberTypeCode" : 10122
}
},
{
"_index" : "subscriber",
"_type" : "json",
"_id" : "139",
"_score" : 0.21072102,
"_source" : {
"Category" : 1,
"CompanyName" : "IH-10122",
"ConvergentBillerId" : "12",
"Created" : "2021-11-22T16:05:40.890Z",
"ExternalReference" : "IH-EX163759714",
"Id" : 139,
"Language" : "en-GB",
"Login" : "1@1.com",
"State" : 1,
"StateChangeDate" : "2021-10-22T16:05:40.840Z",
"Status" : 1,
"SubscriberTypeCode" : 10121
}
},
{
"_index" : "subscriber",
"_type" : "json",
"_id" : "169",
"_score" : 0.21072102,
"_source" : {
"Category" : 1,
"CompanyName" : "IH-163759714",
"ConvergentBillerId" : "16",
"Created" : "2021-11-22T16:05:40.890Z",
"ExternalReference" : "IH-EX163759714",
"Id" : 169,
"Language" : "en-GB",
"Login" : "1@1.com",
"State" : 1,
"StateChangeDate" : "2021-10-22T16:05:40.840Z",
"Status" : 2,
"SubscriberTypeCode" : 10122
}
}
]
}
}
Limiting search result
Here, we are limiting result by size parameter.
GET /blogposts/_search
{
"query": {
"match": {
"status": "draft"
}
},
"size": 5
The following query shows how we can implement pagination in search query.
GET /blogposts/_search
{
"query": {
"match": {
"status": "draft"
}
},
"size": 5,
"from": 10
}
Limiting Number of elements/attrbutes
Sometime, the input document may have lot of elements and we may not need all the elements in search result. In elastic search, search result stays within source attribute and in following way we can reduce number of elements.
GET /blogposts/_search
{
"query": {
"match": {
"status": "draft"
}
},
"size": 5,
"from": 5,
"_source": ["title","status"]
}
There can be scenarios, where we want to exclude only one field and in that scenario, we need to add excludes conditions.
GET /blogposts/_search
{
"query": {
"match": {
"status": "draft"
}
},
"size": 5,
"from": 5,
"_source": {
"excludes": "tags"
}
match_all
The following match_all allows elastic search to query all and return all documents from the index. Here within _source, we are specifying what are elements required from documents.
GET /blogposts/_search
{
"query": {
"match": {
"status": "draft"
}
},
"size": 5,
"from": 5,
"_source": ["title","status"]
multi_match
it allows to search a query string for two elements in a document as shared below. It does full text search.
GET /subscriber/_search
{
"query": {
"multi_match": {
"query": "ih",
"fields": ["ExternalReference","CompanyName"]
}
}
}
curl -XGET "http://localhost:9200/subscriber/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"multi_match": {
"query": "ih",
"fields": ["ExternalReference","CompanyName"]
}
}
}'
post_filter
The post_filter is applied to the search hits at the very end of a search request, after aggregations have already been calculated. Its purpose is best explained by example:
Imagine that you are selling shirts that have the following properties:
PUT /shirts
{
"mappings": {
"_doc": {
"properties": {
"brand": { "type": "keyword"},
"color": { "type": "keyword"},
"model": { "type": "keyword"}
}
}
}
}
PUT /shirts/_doc/1?refresh
{
"brand": "gucci",
"color": "red",
"model": "slim"
}
Imagine a user has specified two filters:
color:red and brand:gucci. You only want to show them red shirts made by Gucci in the search results. Normally you would do this with a bool query:
GET /shirts/_search
{
"query": {
"bool": {
"filter": [
{ "term": { "color": "red" }},
{ "term": { "brand": "gucci" }}
]
}
}
}
However, you would also like to use faceted navigation to display a list of other options that the user could click on. Perhaps you have a model field that would allow the user to limit their search results to red Gucci t-shirts or dress-shirts.
This can be done with a terms aggregation:
GET /shirts/_search
{
"query": {
"bool": {
"filter": [
{ "term": { "color": "red" }},
{ "term": { "brand": "gucci" }}
]
}
},
"aggs": {
"models": {
"terms": { "field": "model" }
}
}
}
| Returns the most popular models of red shirts by Gucci. | |
|---|---|
But perhaps you would also like to tell the user how many Gucci shirts are available in other colors. If you just add a terms aggregation on the color field, you will only get back the color red, because your query returns only red shirts by Gucci.
Instead, you want to include shirts of all colors during aggregation, then apply the colors filter only to the search results. This is the purpose of the post_filter:
GET /shirts/_search
{
"query": {
"bool": {
"filter": {
"term": { "brand": "gucci" }
}
}
},
"aggs": {
"colors": {
"terms": { "field": "color" }
},
"color_red": {
"filter": {
"term": { "color": "red" }
},
"aggs": {
"models": {
"terms": { "field": "model" }
}
}
}
},
"post_filter": {
"term": { "color": "red" }
}
}
| The main query now finds all shirts by Gucci, regardless of color. | |
|---|---|
The colors agg returns popular colors for shirts by Gucci. |
|
The color_red agg limits the models sub-aggregation to red Gucci shirts. |
|
Finally, the post_filter removes colors other than red from the search hits. |
must and must_not condition
This condition allows us to match one condition and stops another condition. Ex: Our requirement is to filter all documents where subtypeid is not 10222 but externalreference is having IH then for the 1st clause we need to use must not and 2nd one shd have must.
GET /subscriber/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"ExternalReference": "ih"
}
}
]
, "must_not": [
{
"match": {
"SubscriberTypeCode": "10121"
}
}
]
}
}
}
sorting
We need to add sorting on the query result. Here you can see the sort is placed outside of query as the query result is passed to sorting.
Note: Text fields are analyzed and then tokenized. So it is not possible to sort the text fields.
GET /blogposts/_search
{
"query": {
"match": {
"status": "draft"
}
},
"size": 10,
"from": 3,
"_source": ["title","status"],
"sort": [
{
"published_date": {
"order": "desc"
}
}
If we have to sort text field then we need to use keyword fields as they are non-analyzed but that will be slow.
Full match condition
Here, we are doing full match which is identified by operator and and this is based on title field.
GET /blogposts/_search
{
"query": {
"match": {
"title":{
"query":"Introduction to elasticsearch"
, "operator": "and"
}
}
}
Minimum match condition
It is sometime necessary to match defined words at minimum level and we don't want full all words to be matched as per our search text.
GET /blogposts/_search
{
"query": {
"match": {
"title":{
"query":"Introduction to elasticsearch",
"minimum_should_match": 2
}
}
}
}
we also can give % wise match rather than specifying perfect no of terms.
GET /blogposts/_search
{
"query": {
"match": {
"title":{
"query":"Introduction to elasticsearch",
"minimum_should_match": "25%"
}
}
}
}
Term and match query
Term query does not go through analysis process. match query goes through analysis process. Lets understand through following example.
Lets see the following two example of match query returning us records. This is because the elasticsearch is storing Draft as draft due to lowercase in analysis process. Hence searching by Draft or draft will return us same set of query results.
GET /blogposts/_search
{
"query": {
"match": {
"status": "draft"
}
}
}
GET /blogposts/_search
{
"query": {
"match": {
"status": "Draft"
}
}
}
Now, lets look at the term query and since elasticsearch has lowercase filter here so all texts are stored in lower case,
- 1st query here will not return any data
- 2nd query here will return data
GET /blogposts/_search
{
"query": {
"term": {
"status": {
"value": "Draft"
}
}
}
}
GET /blogposts/_search
{
"query": {
"term": {
"status": {
"value": "draft"
}
}
}
}
terms filter
This is used when we want to add multiple term filter together. Here “tags” is the document element name and “elasticsearch” and “fast” are element value to compare. Note: This is or condition and any document having tags value of elasticsearch or fast will be returned in result.
GET /blogposts/_search
{
"query": {
"terms": {
"tags": [
"elasticsearch",
"fast"
]
}
}
}
prefix query
Remember that, this query does not go through analysis process and hence exact string needs to be passed. It does not calculate score and all score remains as 1.
GET /blogposts/_search
{
"query": {
"prefix": {
"title": {
"value": "intro"
}
}
}
}
wildcard query
This is same as prefix query.
GET /blogposts/_search
{
"query": {
"wildcard": {
"title": {
"value": "n*ro"
}
}
}
}
Complex Queries
Lets take the following requirement and see how we can write the query.
- blogpost must not be in draft status
- blogpost should have elasticsearch
- blogpost should have like > 10
Lets break this business problem into multiple phases.
Solution
- First, we try to achieve the condition to remove draft blogposts from query.
- We need query here for searching
- Since there will be multiple conditions, so we need to use bool type of query
- we need to filter blogposts which are in draft status and this is case insensitive search. So we i have used must_not and then match filter with field name status
GET /blogposts/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"status": "draft"
}
}
]
}
}
}
-
Now, we will need to allow all blogpost which are having elasticsearch into tag.
- So we need to use must clause into bool query
- we will then use match clause as we want to have case insensitive search
GET /blogposts/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"status": "draft"
}
}
],
"must": [
{
"match": {
"tags": "elasticsearch"
}
}
]
}
}
}
- Now we need to add condition of greater than.
- So we need filter condition as it will take search result out to further filter data as per where clause.
- we need to add range condition here as our condition of >10 is based on range
So, our *final query will be *
GET /blogposts/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"status": "draft"
}
}
],
"must": [
{
"match": {
"tags": "elasticsearch"
}
}
],
"filter": [
{"range": {
"no_of_likes": {
"gte": 10
}
}}
]
}
}
}
Query Relevence
We can use the score value in the search result to understand how the document is relevant to original query. Relevancy score is represented by a positive floating number.
The scoring of a document is determined based on the field matches from the query specified and any additional configurations you apply to the search.
Refer the article How scoring works for more in-depth analysis on this.
Document matching happens in
- binary sense (matching with exact values)
- relevancy sense matching
Scoring Function
Uses following and this means more time a term appears in a document then the document is more relevant while more time the term appears across other documents then it is less relevant.
- Term Frequency (TF)
- Inverse document Frequency (IDF)


When a document matches the query, Lucene calculates the score by combining the score of each matching term. This scoring calculation is done by the practical scoring function.
score(q,d) =
queryNorm(q)
· coord(q,d)
· ∑ (
tf(t in d)
· idf(t)²
· t.getBoost()
· norm(t,d)
) (t in q)
- score(q,d) is the relevance score of document d for query q.
- queryNorm(q) is the query normalization factor.
- coord(q,d) is the coordination factor.
- The sum of the weights for each term t in the query q for document d.
- tf(t in d) is the term frequency for term t in document d.
- idf(t) is the inverse document frequency for term t.
- t.getBoost() is the boost that has been applied to the query.
- norm(t,d) is the field-length norm, combined with the index-time field-level boost, if any.
Boosting
The _boost field (document-level boost) was removed, but field-level boosts, and query boosts still work just fine. If we want to boost matches on field1:
Boosting can be of:
- Index time boosting
- stores at index. boost value cant be changed in future other than re-indexing
- query time boosting
- Allows to define at query time and can be changed anytime
"bool": {
"should": [{
"terms": {
"field1": ["67", "93", "73", "78", "88", "77"],
"boost": 2.0
}
}, {
"terms": {
"field2": ["68", "94", "72", "76", "82", "96", "70", "86", "81", "92", "97", "74", "91", "85"]
}
}, {
"terms": {
"category": ["cat2"]
}
}]
}
We can add also like this,,,
- A class of boost 2 means it is twice as important compare to others
- Boost figure is relative.
- Tough to finalize correct boost value and this is more an iterative process to find out optimal relevency score
GET /blogposts/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"title":{
"query": "Elasticsearch",
"boost": 2
}
}
},
{
"match": {
"content":{
"query": "Elasticsearch"
}
}
}
]
}
}
}
Filter Search basics of Elasticsearch
Filter condition allows us to add more condition into search criteria. Here we see first condition is must and this means it will retrieve all documents where ExternalReference has ih text. This is being set as must. Next condition is filter based one which will be triggered. here filter condition will be based on status greater than 1. Here since i need range bound one so have used range filter.
Always first filter context gets executed and then query context gets executed. This is to ensure filtered objects are available for document search by query objects. Score does not gets calculated for filter query results by elasticsearch. Score only gets calculated for query context.
GET /subscriber/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"ExternalReference": "ih"
}
}
]
, "filter": [
{
"range": {
"Status": {
"gte": 1
}
}
}
]
}
}
}
There can be filter based on term which is where we compare the value. term filter has been used here to compare the value. in case of date range, we need to use range filter.
GET /subscriber/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"ExternalReference": "ih"
}
}
]
, "filter": [
{
"term": {
"Status": "2"
}
}
]
}
}
}
Cluster Node
Cluster has a master node and any node can become master node. Every node knows where each document leaves. When an index is sharded, a given document within that index will only be stored within one of the shards.


There are two main reasons why sharding is important, with the first one being that it allows you to split and thereby scale volumes of data. So if you have growing amounts of data, you will not face a bottleneck because you can always tweak the number of shards for a particular index. The other reason why sharding is important, is that operations can be distributed across multiple nodes and thereby parallelized. This results in increased performance, because multiple machines can potentially work on the same query. This is completely transparent to you as a user of Elasticsearch.
So how do you specify the number of shards an index has? You can optionally specify this at index creation time, but if you don’t, a default number of 5 will be used. This is sufficient in most cases, since it allows for a good amount of growth in data before you need to worry about adding additional shards.

Primary and Replica shard
There are two types of shards: primaries and replicas. Each document in an index belongs to one primary shard. ... The number of primary shards in an index is fixed at the time that an index is created, but the number of replica shards can be changed at any time, without interrupting indexing or query operations.
Elasticsearch uses the concept of the shard to subdivide the index into multiple pieces and allows us to make one or more copies of index shards called replicas. Please refer to this SO answer to get a detailed understanding of shards and replicas.
To set the number of shards and replicas as properties of index: Here it means number of primary shard will be 6 and for each primary shard there will be 2 replica shard available.
PUT /indexName
{
"settings": {
"index": {
"number_of_shards": 6,
"number_of_replicas": 2
}
}
}
Some important tips for choosing the number of shards and replicas:
- The number of shards cannot be changed after an index is created. If you later find it necessary to change the number of shards, then you will have to reindex all the documents again.
- To decide no of shards, you will have to choose a starting point and then try to find the optimal size through testing with your data and queries.
- Replicas tend to improve search performance (not always). But, it is recommended to have at least 1 replica (so that data is preserved in case of hardware failure)
- Refer this medium article, that states that number of nodes and number of shards (primary shard + replicas), should be proportional to each other. This is important for Elasticsearch to ensure proper load balancing.
- As stated in this article it is recommended to keep the number of shards per node below 20 per GB heap it has configured.
- According to this blog when you’re planning for capacity, try and allocate shards at a rate of 150% to 300% (or about double) the number nodes that you had when initially configuring your datasets
Replication serves two purposes, with the main one being to provide high availability in case nodes or shards fail. For replication to even be effective if something goes wrong, replica shards are never allocated to the same nodes as the primary shards, which you can also see on the above diagram. This means that even if an entire node fails, you will have at least one replica of any primary shards on that particular node. The other purpose of replication — or perhaps a side benefit — is increased performance for search queries. This is the case because searches can be executed on all replicas in parallel, meaning that replicas are actually part of the cluster’s searching capabilities.

Replication between Primary and Replica
So how does Elasticsearch keep everything in sync? Elasticsearch uses a model named primary-backup for its data replication.
Adding, updating, or removing documents — are sent to the primary shard. The primary shard is then responsible for validating the operations and ensuring that everything is good. This involves checking if the request is structurally invalid, such as trying to add a number to an object field or something like that. When the operation has been accepted by the primary shard, the operation will be performed locally on the primary shard itself. When the operation completes, the operation will be forwarded to each of the replica shards in the replica group. If the shard has multiple replicas, the operation will be performed in parallel on each of the replicas. When the operation has completed successfully on every replica and responded to the primary shard, the primary shard will respond to the client that the operation has completed successfully. This is all illustrated in the below diagram.

Search Operation and its combine
There are two phases of search operation in elasticsearch,
- query all the matching documents from all the sherds
- combine all the search records in master node from all the sherds for the respective documents
Distributed searching
A search request can be accepted by any node in the Elasticsearch cluster. Each of the nodes in the cluster is aware of all the other nodes. The catch being that, the node receiving the search request, by default is unaware of where the data that is to be queried resides. Hence, the node has no choice but to broadcast the request to all the shards and then gather their responses into a globally sorted result set that it can return to the client.

The process of determining which shard a particular document resides in is termed as routing. By default, routing is handled by Elasticsearch. The default routing scheme hashes the ID of a document and uses it as the partition key to find a shard. This includes both user-provided IDs and randomly generated IDs picked by Elasticsearch. Documents are assigned shards by hashing the document ID, dividing the hash by the number of shards and taking the remainder.

Index Components
Manually Index creation
We can create index manually and mainly we need to provide shard and replica related configuration.
PUT /blogposts/
{
"settings": {
"number_of_shards": 2
, "number_of_replicas": 1
}
}
Here, we can define index element datatype and it is better that we always define explicitly datatype rather than relying on Elasticsearch.
Key datatype are:
- string
- Float
- Double
- date
- boolean
- array (Can only hold one datatype data. It cant hold multiple data type like string and Boolean)
- Keyword
PUT /blogposts/_mapping
{
"properties":{
"title":{"type":"text"},
"content": {"type": "text"},
"published_date":{"type":"date"}
}
}
Response from Elasticsearch will be acknowledgement one.
{
"acknowledged" : true
}
How index components are?
We can find out details of index by GET command with Index name.
GET /subscriber/
Elasticsearch defines index fields mapping and its data types during 1st document insert by default. So if later new datatype has been sent into any field then Elasticsearch will give error. So it is always good to define the index mapping explictly rather than allowing Elasticsearch to assume it by default.
The search result will have following 3 components
aliases
-
settings
- It will have following informations
- number_of_shards (Elasticsearch will set this by default to 1)
- provided_name
- index creation date
- uuid (Unique identifier of the index)
- number_of_replicas (Elasticsearch will set this by default to 1)
"settings" : {
"index" : {
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_content"
}
}
},
"number_of_shards" : "1",
"provided_name" : "subscriber",
"creation_date" : "1637599846785",
"number_of_replicas" : "1",
"uuid" : "L4jp0hosRq2Pjqk3hHxP5w",
"version" : {
"created" : "7150299"
}
}
}
-
mappings
- defines how the index should be distributed. Mapping is either generated automatically or we can define explicitly.
- It will have all element names for documents we have indexed.
- Elasticsearch detects field types from its values.
"PostalCode" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
{
"subscriber" : {
"aliases" : { },
"mappings" : {
"properties" : {
"Addresses" : {
"properties" : {
"City" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"Country" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"Created" : {
"type" : "date"
},
"DefaultBilling" : {
"type" : "boolean"
},
"DefaultHome" : {
"type" : "boolean"
},
"DefaultPostal" : {
"type" : "boolean"
},
"DefaultService" : {
"type" : "boolean"
},
"DefaultShipping" : {
"type" : "boolean"
},
"DefaultWork" : {
"type" : "boolean"
},
"Id" : {
"type" : "long"
},
"LineOne" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"Modified" : {
"type" : "date"
},
"Name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"PostalCode" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"ShipToName" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"State" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"Status" : {
"type" : "long"
},
"StatusName" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"Verifiable" : {
"type" : "boolean"
},
"Verified" : {
"type" : "boolean"
}
}
},
"Category" : {
"type" : "long"
},
"CompanyName" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"ConvergentBillerId" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"Created" : {
"type" : "date"
},
"ExternalReference" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"Id" : {
"type" : "long"
},
"Language" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"Login" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"State" : {
"type" : "long"
},
"StateChangeDate" : {
"type" : "date"
},
"Status" : {
"type" : "long"
},
"Subscriber" : {
"properties" : {
"AdditionalProperties" : {
"properties" : {
"ExternalReference" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"Id" : {
"type" : "long"
},
"Name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"Values" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"Category" : {
"type" : "long"
},
"CompanyName" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"ContactPreferences" : {
"properties" : {
"ContactEventType" : {
"type" : "long"
},
"ContactMethod" : {
"type" : "long"
},
"Id" : {
"type" : "long"
},
"OptIn" : {
"type" : "boolean"
}
}
},
"ConvergentBillerId" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"Created" : {
"type" : "date"
},
"EffectiveStartDate" : {
"type" : "date"
},
"ExternalReference" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"HomeCountry" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"Id" : {
"type" : "long"
},
"InvoiceConfiguration" : {
"properties" : {
"HideZeroAmount" : {
"type" : "boolean"
},
"InvoiceDetailLevel" : {
"type" : "long"
}
}
},
"Language" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"Login" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"State" : {
"type" : "long"
},
"StateChangeDate" : {
"type" : "date"
},
"StateName" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"Status" : {
"type" : "long"
},
"StatusName" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"SubscriberCurrency" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"SubscriberTypeCode" : {
"type" : "long"
},
"SubscriberTypeDetails" : {
"properties" : {
"AccountingMethod" : {
"type" : "long"
},
"BillCycle" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"BillCycleDay" : {
"type" : "long"
},
"BillCycleName" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"IsReadOnly" : {
"type" : "boolean"
},
"PaymentDueDays" : {
"type" : "long"
},
"PostpaidAccountNumber" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"TermsAndConditionsAccepted" : {
"type" : "date"
}
}
},
"SubscriberTypeCode" : {
"type" : "long"
},
"TermsAndConditionsAccepted" : {
"type" : "date"
}
}
},
"settings" : {
"index" : {
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_content"
}
}
},
"number_of_shards" : "1",
"provided_name" : "subscriber",
"creation_date" : "1637599846785",
"number_of_replicas" : "1",
"uuid" : "L4jp0hosRq2Pjqk3hHxP5w",
"version" : {
"created" : "7150299"
}
}
}
}
}
Analyzer
An analyzer — whether built-in or custom — is just a package which contains three lower-level building blocks: character filters, tokenizers, and token filters.
- Character filters
Character filters are used to preprocess the stream of characters before it is passed to the tokenizer. An example is HTML stripc character filter that strips HTML elements from a text and replaces HTML entities with their decoded value (e.g, replaces
&with &).
- Tokenizers
A tokenizer receives a stream of characters, breaks it up into individual tokens (usually individual words), and outputs a stream of tokens.
- Token filters
Token filters accept a stream of tokens from a tokenizer and can modify tokens (eg lowercasing), delete tokens (eg remove stopwords) or add tokens (eg synonyms). An example is a lowercase token filter that simply changes token text to lowercase. ASCII folding token filter converts alphabetic, numeric, and symbolic characters that are not in the Basic Latin Unicode block (first 127 ASCII characters) to their ASCII equivalent, if one exists. For example, the filter changes à to a.

There can be multiple token filters as shown and each token filter does different work. There can be different query time and Index time analyzer.
Characteristics of an analyzer**
- An analyzer may have zero or more character filters, which are applied in order.
- An analyzer must have exactly one tokenizer.
- An analyzer may have zero or more token filters, which are applied in order.
- Tokenizer generates tokens, which will be passed on to the token filter and then eventually become terms in the inverted index.
- Certain tokenizers like ngram, edgengram can generate lots of tokens, which can cause higher disk usage.
The analyzer will affect how we search the text, but it won’t affect the content of the text itself. With this example, if we search for let, the Elasticsearch will still return the full text Let’s build an autocomplete! instead of only let.

Elasticsearch’s Analyzer has three components you can modify depending on your use case:
- Character Filters
- Tokenizer
- Token Filter
Character Filter
The character filter has the ability to perform addition,removal or replacement actions on the input text given to them.
Here is a sample request
POST _analyze/?pretty
{
"tokenizer": "standard",
"char_filter": ["html_strip"],
"text": "The <b> Auto-generation </b> is a success"
}
curl -XPOST "http://localhost:9200/_analyze/?pretty" -H 'Content-Type: application/json' -d'
{
"tokenizer": "standard",
"char_filter": ["html_strip"],
"text": "The <b> Auto-generation </b> is a success"
}'
The response shows that, html tag has been removed and the resulting tokens are like below:
"tokens" : [
{
"token" : "The",
"start_offset" : 0,
"end_offset" : 3,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "Auto",
"start_offset" : 8,
"end_offset" : 12,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "generation",
"start_offset" : 13,
"end_offset" : 23,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "is",
"start_offset" : 29,
"end_offset" : 31,
"type" : "<ALPHANUM>",
"position" : 3
},
{
"token" : "a",
"start_offset" : 32,
"end_offset" : 33,
"type" : "<ALPHANUM>",
"position" : 4
},
{
"token" : "success",
"start_offset" : 34,
"end_offset" : 41,
"type" : "<ALPHANUM>",
"position" : 5
}
]
}
Tokenizer
The input text after its transformation from the Character filter is passed to the tokeniser. The tokenizer would split this input text into individual tokens (or terms) at specific characters. The default tokenizer in elasticsearch is the “standard tokeniser”, which uses the grammar based tokenisation technique.
The above command shows the resulting tokens are like below:
“The”,”Auto”,”generation”,”is”,”a”,”success”
The words are split whenever there is a white-space and also a hyphen (-).
Standard Tokenizer
- default analyzer of the Elasticsearch
- It uses grammar based Tokenization specified in https://unicode.org/reports/tr29/
- Does following
- Tokenizer
- Standard Tokenizer
- Token Filters
- Lower Case Token Filter
- Stop Token Filter (disabled by default)
Simple Analyzer
The simple analyzer breaks text into tokens at any non-letter character, such as numbers, spaces, hyphens and apostrophes, discards non-letter characters, and changes uppercase to lowercase. It does not remove stop words.
POST _analyze
{
"analyzer": "simple",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
The simple analyzer parses the sentence and produces the following tokens:
[ the, quick, brown, foxes, jumped, over, the, lazy, dog, s, bone ]
Whitespace analyzer
The whitespace analyzer breaks text into terms whenever it encounters a whitespace character. The whitespace analyzer is not configurable. If you need to customize the whitespace analyzer then you need to recreate it as a custom analyzer and modify it, usually by adding token filters. This would recreate the built-in whitespace analyzer and you can use it as a starting point for further customization:
POST _analyze
{
"analyzer": "whitespace",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
The above sentence would produce the following terms:
[ The, 2, QUICK, Brown-Foxes, jumped, over, the, lazy, dog's, bone. ]
Stop analyzer
The stop analyzer is the same as the simple analyzer but adds support for removing stop words. It defaults to using the _english_ stop words.
POST _analyze
{
"analyzer": "stop",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
The above sentence would produce the following terms:
[ quick, brown, foxes, jumped, over, lazy, dog, s, bone ]
Keyword analyzer
The keyword analyzer is a “noop” analyzer which returns the entire input string as a single token.
POST _analyze
{
"analyzer": "keyword",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
The above sentence would produce the following single term:
[ The 2 QUICK Brown-Foxes jumped over the lazy dog's bone. ]
Fingerprint analyzer
The fingerprint analyzer implements a fingerprinting algorithm which is used by the OpenRefine project to assist in clustering.
Input text is lowercased, normalized to remove extended characters, sorted, deduplicated and concatenated into a single token. If a stop word list is configured, stop words will also be removed.
- creates fingerprint which can be used for duplicate detection
- input is lowercased, normalized to remove extended character, sorted, de-duplicated and concatenated
POST _analyze
{
"analyzer": "fingerprint",
"text": "Yes The customer is not honest. He is not reliable for company."
}
Output:
{
"tokens" : [
{
"token" : "company customer for he honest is not reliable the yes",
"start_offset" : 0,
"end_offset" : 63,
"type" : "fingerprint",
"position" : 0
}
]
}
Custom Analyzer
Here for custom analyzer, we have provided following
- analyzer name which is being set as amit_custom_analyze
- analyzer type is set to custom
- char_filter is set to html stripping. we can have 0 or more character filter and hence it is array type
- tokenizer filter is set to standard one
- token filter is being set as lowercase to convert into lower case
This custom analyzer now can be associated with any of the index element.
PUT /blogposts
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 1,
"analysis": {
"analyzer": {
"amit_custom_analyze":{
"type": "custom",
"char_filter": ["html_strip"],
"tokenizer": "standard",
"token_filters": ["lowercase"]
}
}
}
}
}
Response:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "blogposts"
}
Custom Index with Custom Analyzer
Here:
- mapping provides each element types and its allowed data type
- setting provides Index metadata attributes
PUT /blogposts
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 1,
"analysis": {
"analyzer": {
"amit_custom_analyze":{
"type": "custom",
"char_filter": ["html_strip"],
"tokenizer": "standard",
"token_filters": ["lowercase"]
}
}
}
},
"mappings": {
"properties": {
"title":{"type": "text", "analyzer": "amit_custom_analyze"},
"content":{"type": "text", "analyzer": "amit_custom_analyze"},
"published_date":{"type": "date"},
"no_of_likes":{"type": "text"}
}
}
}
response:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "blogposts"
}
Here is one example of using custom analyzer during analysis process:
Example shows
- html content removed
- converted to lower case
POST /blogposts/_analyze
{
"analyzer": "amit_custom_analyze",
"text": ["This is <html> kayal exploring elasticsearch"]
}
{
"tokens" : [
{
"token" : "This",
"start_offset" : 0,
"end_offset" : 4,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "is",
"start_offset" : 5,
"end_offset" : 7,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "kayal",
"start_offset" : 15,
"end_offset" : 20,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "exploring",
"start_offset" : 21,
"end_offset" : 30,
"type" : "<ALPHANUM>",
"position" : 3
},
{
"token" : "elasticsearch",
"start_offset" : 31,
"end_offset" : 44,
"type" : "<ALPHANUM>",
"position" : 4
}
]
}
How to create customer tokenizer and filters
Here, I have shown an example of Index creation command where custom tokenizer and filters have been defined.
- punctuation is the name of the tokenizer and similarly symbol is the name of the char_filter
- tokenizer will look for pattern @# and tokenize
- symbol will look for emoji :) and :( to convert them into happy and sad
PUT /blogposts
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 1,
"analysis": {
"analyzer": {
"amit_custom_analyze":{
"type": "custom",
"tokenizer": "punctuation",
"char_filter":"symbol"
}
},
"tokenizer": {
"punctuation":{
"type":"pattern",
"pattern":"@#"
}
},
"char_filter": {
"symbol":{
"type":"mapping",
"mappings": [":) ==> happy",":( ==> sad"]
}
}
}
},
"mappings": {
"properties": {
"title":{"type": "text", "analyzer": "amit_custom_analyze"},
"content":{"type": "text", "analyzer": "amit_custom_analyze"},
"published_date":{"type": "date"},
"no_of_likes":{"type": "text"}
}
}
}
Aggregation
Every aggregation is combination of one or more buckets and metrices. Aggregation refers to the collection of documents or a set of documents obtained from a particular search query or filter. Aggregation forms the main concept to build the desired visualization in Kibana.
Aggregation always works on top of query and filter result. This is true unless we use post_filter.
Buckets
- A bucket mainly consists of a key and a document. When the aggregation is executed, the documents are placed in the respective bucket.
- Bucket aggregations categorize sets of documents as buckets. The type of bucket aggregation determines whether a given document falls into a bucket or not.
- use bucket aggregations to implement faceted navigation (usually placed as a sidebar on a search result landing page) to help you’re users narrow down the results.
- Buckets are similar to GROUP BY
Note: Here the tag is keyword field and not an analyzed one. If this is analyzed one then we need nested raw one.
We can have sub-aggregation within buckets also.
Metric aggregations—This aggregation helps in calculating matrices from the fields of aggregated document values.
Pipeline aggregations—As the name suggests, this aggregation takes input from the output results of other aggregations.
Matrix aggregations (still in the development phase)—These aggregations work on more than one field and provide statistical results based on the documents utilized by the used fields.
Steps are
Document ==> Filter ==> Query ==> Query Result ==> Aggregation ==> Aggregation Result
GET /blogposts/_search
{
"aggs": {
"tag_wise_stats": {
"terms": {
"field": "tags",
"size": 10
}
}
}
}
GET /shirts/_search
{
"query": {
"bool": {
"filter": [
{ "term": { "color": "red" }},
{ "term": { "brand": "gucci" }}
]
}
},
"aggs": {
"models": {
"terms": { "field": "model" }
}
}
}
Metrices
- Metric Aggregation mainly refers to the maths calculation done on the documents present in the bucket. For example if you choose a number field the metric calculation you can do on it is COUNT, SUM, MIN, MAX, AVERAGE etc.
Logstash
Logstash is typically used as the “processing” engine for any log management solution (or systems that
deal with changing data streams).
These data can be structured, semi-structured, or unstructured, and can have many different schemas. To Logstash, all these data are “logs” containing “events”. Logstash can easily parse and filter out the data from these log events using one or more filtering plugins that come with it. Finally, it can send the filtered output to one or more destinations. Again, there are prebuilt output interfaces that make this task simple.



Logstash itself doesn’t access the source system and collect the data, it uses input plugins to ingest the data from various sources.
Note: There’s a multitude of input plugins available for Logstash such as various log files, relational databases, NoSQL databases, Kafka queues, HTTP endpoints, S3 files, CloudWatch Logs, log4j events or Twitter feed.
Once data is ingested, one or more filter plugins take care of the processing part in the filter stage.
Here is a sample logstash config file which allows to push data into elasticsearch host. This config file which allows logstash to takes data from STDIN and and pushes into blogposts index of elasticsearch running in localhost port 9200.
input { stdin {codec => json } }
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "blogposts"
document_type => _doc
}
stdout { }
}
Filters are an in-line processing mechanism that provide the flexibility to slice and dice your data to fit your needs. Let’s take a look at some filters in action. The following configuration file sets up the grok and date filters.
input { stdin { } }
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
}
output {
elasticsearch { hosts => ["localhost:9200"] }
stdout { codec => rubydebug }
}
Sample Filter Plugin

Reference Architecture


Top comments (1)
Low-quality post with many grammar and spelling mistakes, typos, and other errors. But, sure I've managed to learn something new