In this blog post, I will demonstrate how to create a loop that prints messages along with loop index values, displaying digits from 0 to 30 using both AArch64 and x86_64 architectures.
AArch64
.text
.globl _start
min = 0
max = 31
_start:
mov x19, min
mov x17, 10
loop:
mov x0, 1
adr x1, msg
mov x2, len
mov x18, x19
udiv x9, x18, x17
add x13, x9, 0x30
msub x10, x9, x17, x18
add x14, x10, 0x30
adr x15, msg
strb w13, [x15, 7]
strb w14, [x15, 8]
mov x8, 64
svc 0
add x19, x19, 1
cmp x19, max
b.ne loop
.data
msg: .ascii "Loop : \n"
len= . - msg
Result
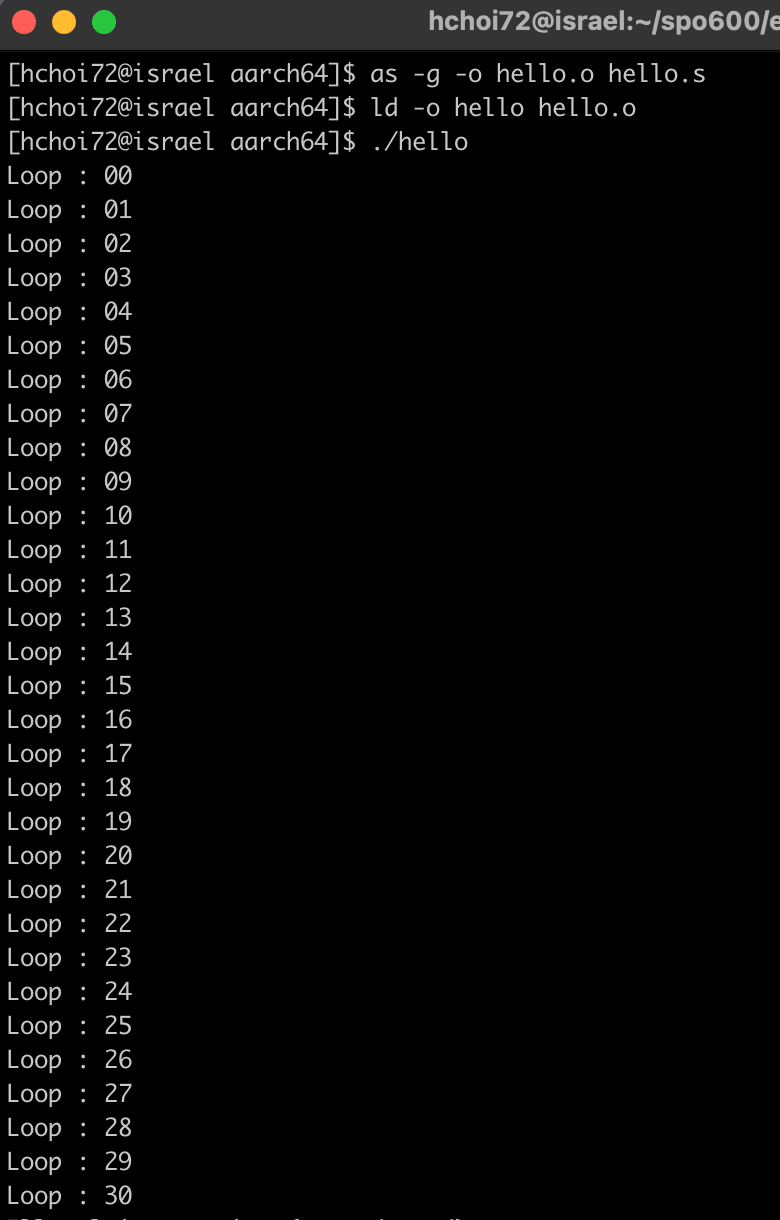
x86_64
.globl _start
min = 0
max = 31
_start:
movq $min, %r15
movq $0x30, %r12
loop:
movq $min, %rdx
movq %r15, %rax
movq $10, %r10
div %r10
movq %rax, %r14
movq %rdx, %r13
add $0x30, %r14
add $0x30, %r13
mov %r13b, msg+8
cmp %r12, %r14
mov %r14b, msg+7
movq $len, %rdx
movq $msg, %rsi
movq $1, %rdi
movq $1, %rax
syscall
inc %r15
cmp $max, %r15
jne loop
movq $min, %rdi
movq $60, %rax
syscall
.section .data
msg: .ascii "Loop : \n"
len = . - msg
Result
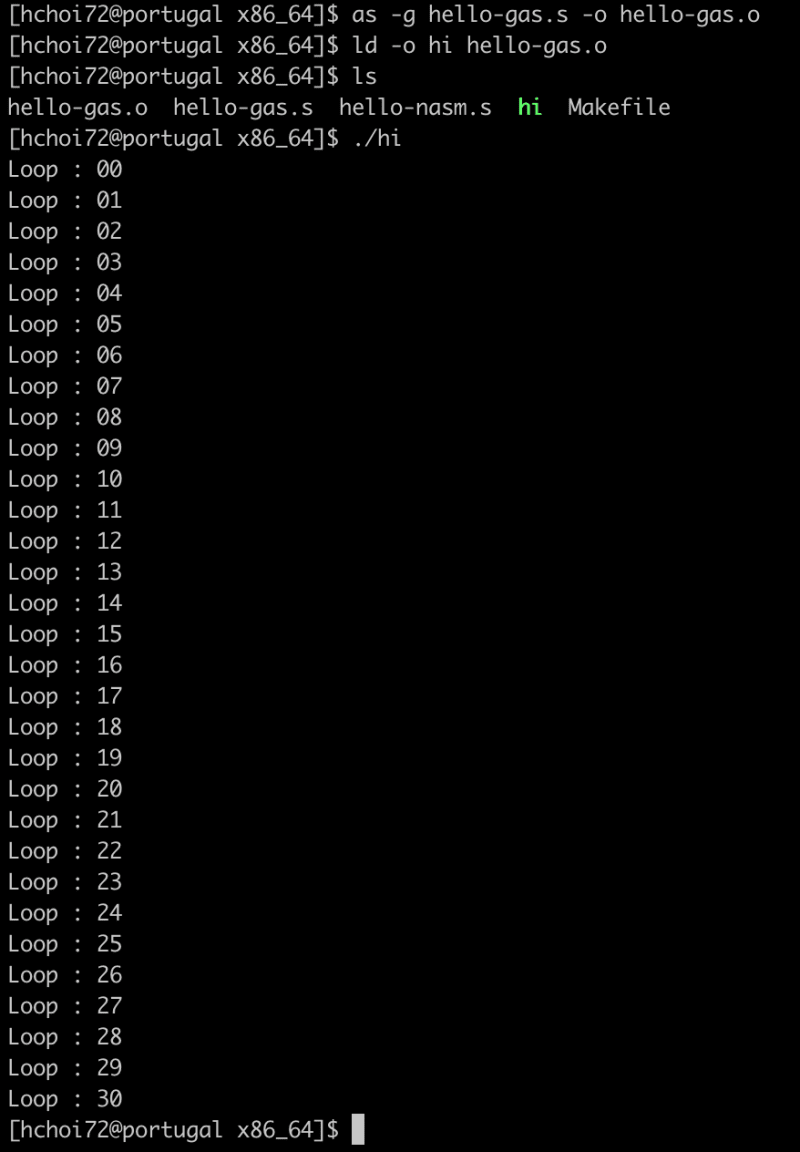
AArch64 vs x86_64
I find the instruction set of AArch64 to be more straightforward and user-friendly, as I don't have to prefix every number with a '$' sign. Additionally, achieving the same task in x86_64 requires much longer lines of code compared to AArch64, which can be a bit time-consuming.
Experience in general
The debugging process was challenging for me, as a solid grasp of memory addresses, registers, and stacks is essential to uncover what's happening in the code. Furthermore, my lack of familiarity with the syntax of each architecture added an extra layer of difficulty to this project.
Another challenge for me was to remove the leading zero when dealing with single digits. For example, the desired output should be 0, 1, 2, ... 29, 30 instead of 00, 01, 02, ... 29, 30. Unfortunately, I couldn't figure out how to suppress the leading zero in this lab.

Top comments (0)