About two years ago, a significant event happened at Stack Overflow: a new system, named Providence, was released. Providence would allow us to tell which technologies a visitor is interested in, and measure the "fitness" between a visitor and a job.
More generally, the release of Providence marked a stepping stone in Stack Overflow's continuous effort to be "smarter" and invest in data science. There's a great series of blog posts about Providence if you want to know more about it. Go ahead and read it, I'll wait.
As a developer on the Jobs team, I started working on using this new power to help you find a new, better job. My adventures in doing so is what this blog post will (mostly) be about.

How to immediately fail
Job matches. Interesting jobs. Recommended jobs. Whatever we call them, they are tricky to get right. Every person has a different set of requirements and different preferences. Some people want to relocate from the USA to Norway, and some people won't consider a job that is more than 5 miles away from home. Some people don't want to work at a startup; some people exclusively want to work at a startup. You see what I'm getting at: there's no one solution that fits it all. But that's what we tried to do anyway.

Before we introduced personalized job search results ("job matches"), the default sort on Stack Overflow Jobs was "most recent." It was okay, but not great. One of its problems was that it would show you jobs that had just been posted, regardless of your interests, and even if they were on the other side of the planet. We could clearly do better.
With Providence, we now had a new tool in our toolbox. We could determine, for each job, a score between 0 and 1 representing how well a job's technologies fit those of a visitor. Instead of showing most recent jobs first, why not show jobs that are a good fit in terms of technologies? It's not perfect either, but at least it's relevant to you, so it should perform better, right?
Well, not exactly. Our first A/B test showed a dramatic drop in CTR (Click Through Rate). Nearly 50% fewer visitors were clicking on search results! This first failure opened the door to a question which is harder than it looks…

What the heck makes a job interesting?
We knew that Providence alone was not working (the user-job fit in terms of technologies). But we also knew that most recent jobs were not great either. So, where to go from there?
We knew that distance was an important factor: most people want to work near where they live. And maybe showing recent jobs was not that bad: after all, it performed better than our new and fancy "Providence value function".
So we did just that: we multiplied the user-job distance (we got the user's location from their IP address) by the age of the job (the number of days since it was posted). That gave us a "score", and we sorted jobs by that.
// The formula of the first matching algorithm.
// distance and age are normalized between 0 and 1
score = (1 - distance) * (1 -age)
This time, it worked! Actually, it worked great.

We now knew two things:
- The age of the job is important
- The distance between the user and the job is important too
But in what measure? Is the distance as important as the age? Is the distance 3x more important? To answer this question we created a lot of charts, like these:
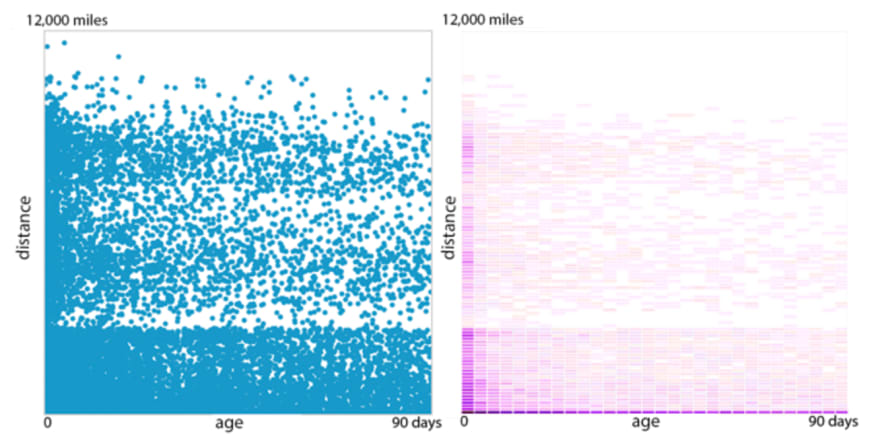
The right-hand graph (in purple) tells us that the density of applications decreases with distance. It makes sense: visitors prefer nearby jobs. The age of the job doesn't have as much of an impact, except for very recent jobs (published within the last day) which receive a lot of applications.
Using this density data, we performed linear regression to predict, based on a (distance, age) pair, how likely it is for a user to apply.


Since the number of applications decreases exponentially with distance (not linearly), we need to use a slightly fancier equation with an exponential:
// The matching algorithm formula
score = Math.exp(A * distance + B * age + C * (1 – distance) * (1 – age))
Note that it's still linear regression: we just predicted the logarithm of the number of applications instead of, previously, the raw number of applications.)
Providence, we haven't given up on you
So, now we have a formula, based on recency and distance, which surfaces jobs that are relevant to visitors. Great! But wasn't the whole point of "interesting jobs" to leverage the power of Providence (which tells us how well a job fits a visitor in terms of technologies)?
After failing to use Providence correctly, we went off-track for a while. But we're still convinced that our newest tool can give us some special insight about our visitors. And now we're ready to give it a second try.
At this point, re-introducing Providence was simply a matter of adding a new parameter to our density analysis and our formula. The computer is still in charge of deciding how much importance we give to each of our three parameters (with "linear regression"): distance, age, and, now, Providence score. (While we're at it, let's move away from linear regression and use Poisson regression instead: it's a more relevant technique since we're trying to predict the number of applications, a natural number.)
Finally, why only three parameters? There are many other important factors when deciding which job is interesting for you.

Job match preferences
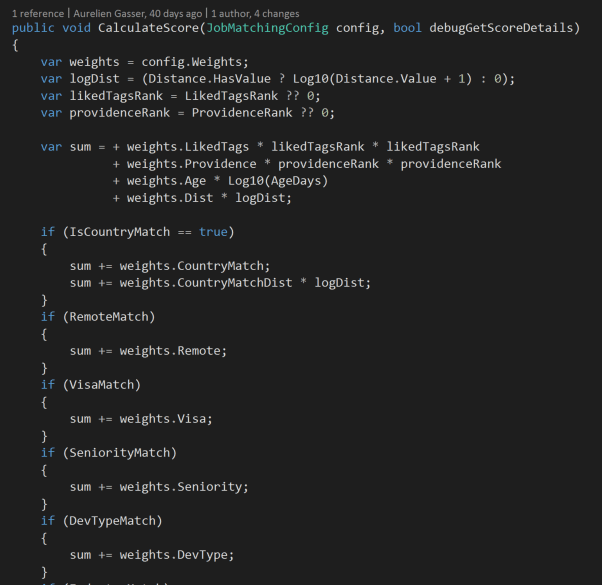
We know there are even more dimensions that might make a job relevant to you, like seniority, salary, industry, developer type ("full stack", "mobile") and others. To express these, we introduced job match preferences.
As you'll recall from above, each parameter in our "interestingness" formula has an associated weight. It determines how much this parameter impacts the match score (aka interestingness score). Initially, we didn't have any data: job matches preferences were very new, and as such mostly empty. Because of the lack of data, we couldn't calculate the weight of these new parameters (like we did previously with Poisson regression). So we made the weights up. We referred to them as "yay weights" because why not?
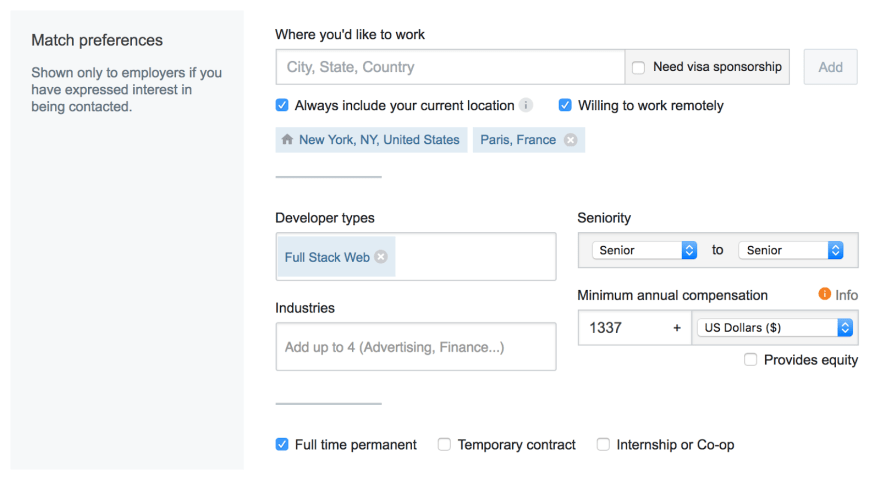
However, users did fill up their match preferences over time. It supplied us with enough data to identify correlations between user match preferences, job listings, and job applications. We were able to use this data to run Poisson regression and calculate new weights.
We had achieved our goal: we didn't have to choose how each parameter should affect the interestingness of a job. Instead, data analysis could tell us.
But we still had an issue: the interestingness formula was biased by the availability of jobs. For instance, let's imagine that 95% of the job applications in our database are remote jobs (jobs which allow remote work). Our method would infer that remote jobs are much more interesting than non-remote jobs. But that's not necessarily true! It could simply mean that our database contains many more remote jobs than non-remote jobs! Following the same logic, we were giving too much (or too little) importance to some parameters in the interestingness formula. We corrected this issue by normalizing the number of applications based on job availability.

Simulation and genetic algorithms
The matching algorithm was improving, and we were seeing more engagement.

Regularly, we would introduce some kind of change to the matching algorithm (add a new parameter, like "salary" or "industry" for instance), or we would fix a bug in the generation of the input dataset.
In those cases, we would re-run the learning process (Poisson regression, remember?) and collect a new set of weights. We had no guarantee whatsoever that these new weights were better than the previous ones. We basically just hoped so. We crossed our fingers and started an A/B test, which would take weeks to detect an improvement, and most of the times it didn't detect anything. Our process to improve the matching algorithm was very slow, and we were wasting a lot of time.
So we took a new approach. For each past job application, we simulated what the search results would have looked like for the visitor who applied.

Here's how the job matching simulator works:
- Take a set of weights, e.g.
{ age: 0.2, distance: 1.42, industry: 3.08Â … } - For each past job application, for each job listing which was running at the time of the application, compute a score using this set of weights, i.e.
score = 0.2 * AgeDays + 1.42 * LogDistanceMiles + 3.08 * IndustryMatch … - Sort the jobs by descending score and check the position in this sorted list of the job the candidate applied to: this gives us a rank. For example: "for application 123, we ranked the job in the 6th position"
- Compute the average of ranks across all job applications
Averaging the ranks would then give us a measure of the performance of the matching algorithm. The smaller the average rank, the better we were at sorting jobs. We could try many variations of the interestingness formula, many different combinations of weights, run a simulation, and get a measure of how much better we were at sorting jobs within seconds. Much better than having to wait several weeks for the results of an A/B test!
The average rank is only one of the measures we used to evaluate the performance of the matching algorithm. Instead, we currently use the "probability that a job at this rank will be clicked" – based on actual measured clicks by rank (see chart below)

We were now able to try a new set of weights, and get an almost instantaneous measure of its performance: why not take advantage of it? We developed a genetic algorithm which would try thousands of possible sets of weights, and keep only the best one. Until recently, that's how we obtained the matching algorithm weights used in production.
Matches, matches everywhere
Job matching was maturing, and we were ready to take full advantage of it. More than ever, we were confident in its potential to help our users find their dream job. And we knew it could give Stack Overflow Jobs a competitive advantage. As a result, we made some changes to make job matches more prominent throughout our features.
Until that point, the matching algorithm had exclusively been used on the homepage of Stack Overflow Jobs. In other words, as soon as you entered a keyword like "C++" or a filter like "junior jobs" the matching algorithm was not used anymore. Instead, jobs were sorted using our underlying search engine, Elasticsearch. We decided to make the "matches" sort the default sort option for all searches: A/B testing confirmed this change increased the number of job views and applications. Yay.

Job alerts, which allow you to receive new job listings directly in your email inbox, were updated to take advantage of the matching algorithm. This meant that the most interesting jobs would now be displayed first in the email. Wanna try it out? Enter your search criteria and click "Create alert."

Around the same time, we introduced many other improvements to job search, including a ton of new search filters and a revamped, more efficient UI.
R and optimization
Using a genetic algorithm to find optimal job matching weights worked great, but it was very inefficient. Actually, it's only when we discovered a better alternative that we realized how inefficient it really was.
Finding the optimal combination of weights for the matching algorithm is an optimization problem: our goal is to minimize the median rank of the jobs applied to. The lower the median rank, the better we are at predicting the jobs the visitors are going to apply to. There are many techniques to tackle optimization problems. What worked best is the optim function offered by the R language. It uses a technique called gradient descent, which performs much better than genetic algorithms in our case. The weights it finds are slightly better, and more importantly, it is about 70x faster. Concretely, finding the best combination of weights now takes about 10 minutes, versus about 12 hours with a genetic algorithm!

Writing our own genetic algorithm in C# was a bad idea. It took us weeks to implement, test, and optimize. Not to mention all the time spent waiting for results. There was a better solution available all along (the optim function in R). Because we didn't do proper research, we overlooked it and lost time. Sigh.
Switching from a C# implementation to R offered other benefits, like the possibility to create beautiful R Markdown reports, and much faster simulation with native matrix operations. Indeed, since the interestingness score is a linear combination (score = a * Distance + b * Age + c * ProvidenceScore…) we can calculate the scores of all the user-job combinations at once.
We can do so by multiplying a matrix of user-job parameters (dimensions M x N) by a vector of weights (dimension N), where:
- M is the number of user-job pairs in our dataset (M ≃ 15 Millions)
- N is the number of matching parameters ( N ≃ 14: Distance, Age, ProvidenceScore, …)
Once we have computed a new set of weights (or "version"), we measure how well it performs compared to the previous version. We do so by running two simulations on a testing dataset: once using the old weights, once using the new weights. In addition, we use a technique called bootstrapping where we make the old and new versions compete in a tournament involving subsets of the testing dataset. We record which version "wins" more often.

Performance
At Stack Overflow, performance is a feature. We always grind our gears to make things fast and job search is, of course, no exception.

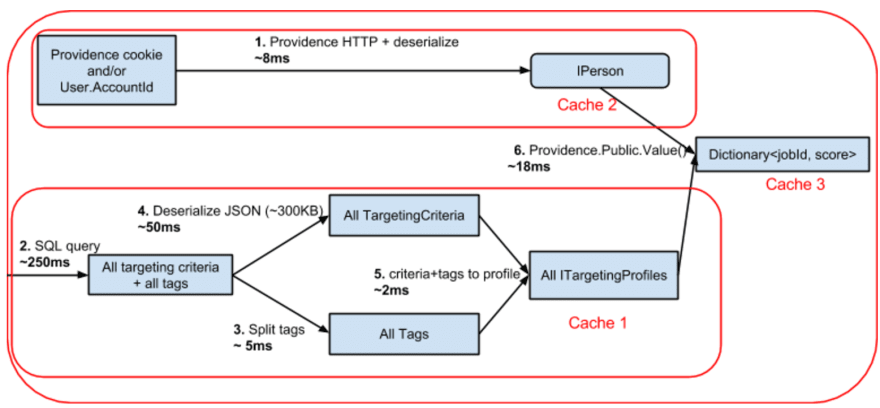
About two years ago, we moved away from SQL Server for job search. Instead, we started using Elasticsearch, a search engine based on Apache Lucene. It provides great features such as stemming and suggestions. In a typical job search, the following steps are executed:
- (0 ms) Transform the query string (e.g. query=java&location=london) into a an expression tree
- (5 to 60 ms) Pass the expression tree to Elasticsearch, and retrieve the list of matching job identifiers (duration depends on number of results)
- (0 ms) Retrieve job details for said identifiers from cache: either from the web server's internal memory (L1) or from redis (L2). Since L1 is virtually always populated, this operation is effectively free.
- (1 to 10 ms) Sort the jobs in memory using the matching algorithm and return the desired page of results (duration depends on number of results)
Retrieving job ids from Elasticsearch is the most expensive step. That's because, since we want to sort the jobs using the matching algorithm, we need Elasticsearch to return all the results for a given search (not just the Nth page of results). Put in another way: the most interesting job could be any of the jobs returned by Elasticsearch, so in doubt we need to return them all. We have plans to make this faster by running the matching algorithm as an Elasticsearch plugin, allowing us to perform step 2, 3 and 4 in a single step (and return only the desired page of results).
A few weeks ago, we shipped another optimization: we now perform all non-keyword searches directly in the web server's memory (L1 cache), removing the need for Elasticsearch altogether (for those types of searches).
"What about user information?" I hear you ask:
- Fetching + deserializing a user's job preferences (JSON stored in SQL) takes less than 1ms
- Fetching + deserializing a visitor's Providence profile (JSON retrieved from internal API) takes less than 5ms
- In both cases, the data is cached in the web server's memory (L1), so subsequent requests from the same user get it for free.
Future work
Stack Overflow's job search has come a long way in the past few years, going from virtually no intelligence to a sophisticated matching algorithm. And there is much more left to do.
Recently, we've tried being smarter about job tags by using tag synonyms. We've also tried surfacing the jobs that were published since your last visit. Unfortunately, none of these attempts were successful in showing more relevant results..
But some other ideas were successful.
We analyzed the most commonly searched terms and optimized our search results to account for variations of the same phrase. For instance, searches for "ML" give the same results as "machine learning." In addition, we've incorporated the Elasticsearch internal score to our matching algorithm, so that the interestingness score takes into account how well a job listing matches the keywords entered by the user.
Another idea is to leverage experience tags from users' Developer Stories: If a user has an open source project which uses redis and a recent professional experience in Java, there is an increased likelihood that this user would be interested in Java / redis jobs. This is something we have been meaning to do for a long time, and is now on the backlog. It should be ready in 6 to 8 weeks.
Finally, the matching algorithm optimizes for applications: it surfaces jobs we think you would be interested in applying to. But you know what would be even better? Optimizing for hires. If we can collect more information about which applications lead to a hire, we can not only surface jobs you are likely to apply to, but jobs you are likely to be hired for.
Thank you for all your feedback and bug reports on Meta Stack Overflow. It is extremely valuable to us, and we are very grateful for your help.
Looking for a new job? Browse new opportunities on Stack Overflow Jobs.

Top comments (5)
Great post. I have a general question: how much value does your team put into the interpretability of the model? I'd guess the highest priority is making good matches and getting users to click, but at what point are you willing to sacrifice slightly better performance for the ability to explain what's going on to someone without statistical expertise?
So far, we've put our focus exclusively on optimizing for job applications. We've had plans to make the inner works of the algorithm more transparent, and this blog post is a step in that direction. I'm not sure we'll compromise relevance of results for the sake of making them easier to explain. But explaining within the site how we sort search results is something we'd like to do.
+1 Good Question
Thank you for sharing! One of my favorite things about Stack Overflow is that they don't stop when something is done, not even when it's close to great, it must be the best. :)
Matching algorithms are no small feat, and yet they're popping up all over (dating sites, adoption / pet adoption sites). Good work & brilliant insight.
This is fascinating. It's clear Stack Overflow's mindset is that they can build a moat in terms of data to deliver the ideal user experience with a really solid product. It would be easier to fall back on the mindset "we have the biggest community, let's just throw up a job board and it will be useful to some people".