Audioflux is a deep learning tool library for audio and music analysis, feature extraction. It supports dozens of time-frequency analysis transformation methods and hundreds of corresponding time-domain and frequency-domain feature combinations. It can be provided to deep learning networks for training, and is used to study various tasks in the audio field such as Classification, Separation, Music Information Retrieval(MIR) and ASR etc.
Project: https://github.com/libAudioFlux/audioFlux
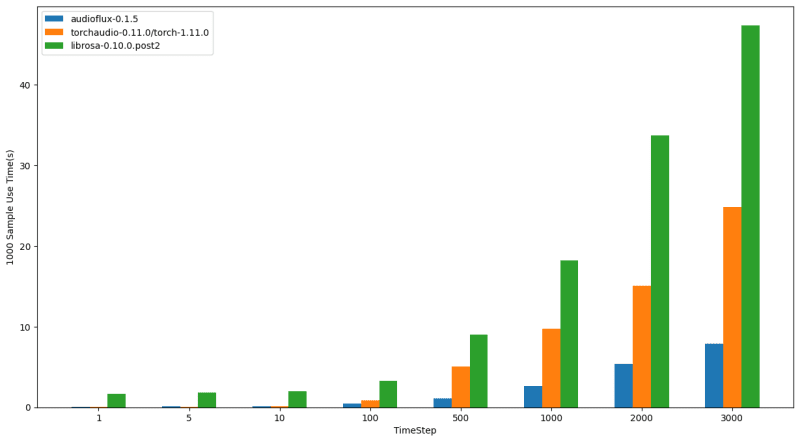
Benchmark: https://github.com/libAudioFlux/audioFlux/issues/22

Top comments (2)
To install the audioFlux package, Python >=3.6, using the released python package.Using PyPI:
pip install audiofluxMel & MFCC demo
In the field of deep learning for audio, the mel spectrogram is the most commonly used audio feature. The performance of mel spectrogram features can be benchmarked and compared using audio feature extraction libraries such as the following: