![Cover image for Saving Millions of Images Series [Part Two]](https://media2.dev.to/dynamic/image/width=1000,height=420,fit=cover,gravity=auto,format=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2Fozu3sno5vxtj5blju6pb.png)
Saving assets
Ok, I agree with you that one of the easiest way is to work with S3 bucket. But there is more to talk about.
Lets’s talk about how to organize the storing of images. We can have a long discussion about how to store "paths to images."
A guy from a StackOverflow posted this: https://stackoverflow.com/questions/3748/storing-images-in-db-yea-or-nay/3751#3751
What about image names? can be something like this:
I would store the image hash in the database along with a
DATE / DATETIME / TIMESTAMP field indicating when the image was uploaded/processed and then place the image in a structure like this

Or
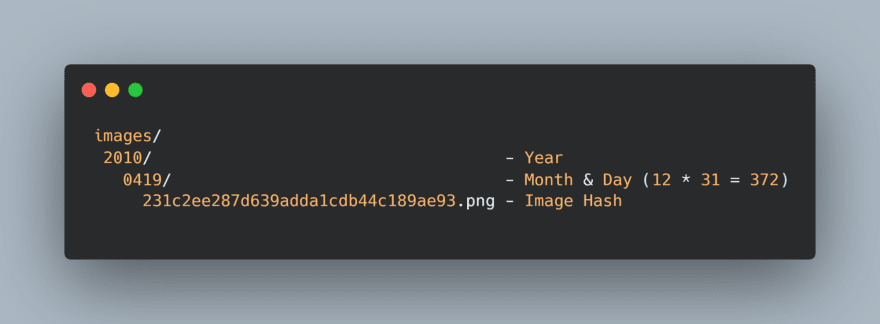
Ok, this method is more descriptive; I get it. But this structure is significant to host hundreds of thousands (depending on your file system boundaries) of images per day for several thousand years, this is how WordPress does it, and I think they got it right.
Duplicated images could be easily queried on the database, and you'd have to create symlinks.
I dont like to operate with user IDs unless you don't have that info available in your database, because of:
- Disclosure of usernames in the URL
- Usernames are volatile (you may be able to rename folders, but again...)
- A user can hypothetically upload a large number of images
Don't forget about CDN! This scheme might work well with CDN. At least I don't see anything bad
Read those >= 10 articles about uploading images or check out these simple examples
- How to Upload and Display Images with JavaScript
- Using files from web applications - Web APIs | MDN
- How to Preview image before uploading in Javascript - DEV Community
- [Solved] Javascript how to upload image file from url using FileReader API? - Code Redirect
- https://javascript.plainenglish.io/upload-images-in-your-node-app-e05d0423fd4a?gi=75cd4825bb8e
- JavaScript SDK image and video upload | Cloudinary
- Saving images in a database or in the project's folder? - DEV Community
- Client-side image upload in JavaScript without managing storage
- How to make a simple image upload using Javascript/HTML - Stack Overflow
- How to Build an Angular Image Feed | Hacker Noon
- Three Ways of Storing and Accessing Lots of Images in Python
- https://vemto.app/blog/how-to-create-an-image-upload-viewer-with-alpinejs
- Upload image to Blob Storage with VSCode - App Service/Cosmos DB - Azure | Microsoft Docs
- GitHub - pqina/filepond: 🌊 A flexible and fun JavaScript file upload library
- Image upload and view with pure JavaScript - simple and easy
- File upload input
- React Image Preview & Upload
Previous Article:
https://dev.to/atherdon/saving-millions-of-images-series-part-one-od1





Top comments (0)