
Hi! Welcome to this post about lyrics/text generation in Tensorflow
The project described in this post can be found on my Github here
And here this my Github profile here
I'd appreciate any feedback on anything on my profile and, if you look anything you see, please leave a star on it too.
Aim
What is our aim in this post?
We want to create a bot that, given a starting phrase, would generate its own lyrics, powered by a machine learning model that would have learned from the lyrics of previously written songs.
How will we go about doing this?
There are 3 main steps we have to take
- Prepare our training data
- Build our machine learning model
- Train and use our model
How will our model work
Before we do anything, we must think about how our model would work, since this would then tell us how we should go about preparing our training data.
Our model will take a one-hot encoded sequence of characters and will try to predict the next character in the sequence, based on the characters before.
Example...
input: "hello worl"
input -> model -> "d" (next predicted character)
Note
One-hot encoding is a way of vectorising data where the data can be categorised and each category has an integer ID.
In our case, for the sequence of characters, we can assign each unique character their own ID (we have categorised the text into unique characters).
For example...
"a" = 0
"b" = 1
"c" = 2
...
One-hot encoding takes these IDs and represents them as a vector. This vector has a length equal to the number of different categories. The vector consists of all zeroes except the index of the corresponding ID, which is populated with a 1.
For example, if we wanted to encode the letter "a"...
We know it's ID is 0 and that there are 26 total categories (since there are 26 letters in the alphabet)
So, the one-hot encoding would be a vector of length 26 with index 0 being a 1 and the rest being a 0.
[1, 0, 0, 0 ... 0, 0] //"a"
Similarly, for "b" we know the ID for it is 1, so the encoding would be a vector of length 26 and index 1 being a 1.
[0, 1, 0, 0 ... 0, 0] //"b"
Preparing the training data
For my project, I decided to use 8 Metallica songs as the dataset for the model to train on.
Note
This is quite a small dataset for machine learning standards, so our model wouldn't produce amazing results. However, it allows for quicker training times and we would get to see results quicker. If you would like to have a much more accurate model, I would suggest using a larger dataset.
I saved all the lyrics as text files for each song and named them as the following...
data1.txt
data2.txt
data3.txt
...
data8.txt
Now, we need to process out data into inputs and outputs.
Our inputs are a sequence of characters and the outputs are characters that should come next in the input sequence.
We can process our texts by taking each substring of a chosen length in our text and splitting it so that the last character is the output and the rest of the characters in the substring are the input sequence.
For example, if there was a substring "tensorflow is cool", this would be split as such
input sequence: "tensorflow is coo"
output: "l"
We do this process for every substring in our lyrics data.
We can encode both the input and outputs and put them into input/output arrays.
In my project, I chose for the input character sequence to be length 15.
Here is the code for prepping our dataset
def get_character_count():
#returns the number of possible characters
alphabet = get_alphabet()
return len(alphabet)
def get_alphabet():
#returns the list of all characters we will allow from our dataset (the lower case alphabet, spaces and new lines)
return list("abcdefghijklmnopqrstuvwxyz \n")
def text_to_vector(text):
#takes in a text and returns it as a sequence of one-hot encodings, representing each character in the text
alphabet = get_alphabet()
vector = []
for char in text:
if char.lower() in alphabet:
one_hot = [0] * get_character_count()
index = alphabet.index(char.lower())
one_hot[index] = 1
vector.append(one_hot)
return vector
def prep_dataset(file):
#this function takes the file name of where certain text data is stored and returns the input sequences array and output characters array
text = open(file, "r").read()
vec = text_to_vector(text) #one-hot encoding the text
xs = [] #input sequence array
ys = [] #output character array
i = 0
while i < len(vec) - 15: #loop for finding each substring of length 15
x = vec[i:i+15] #input sequence
y = vec[i+15] #output character
xs.append(x)
ys.append(y)
i += 1
return xs, ys
if __name__ == "__main__":
x = [] #input sequences
y = [] #output characters
for i in range(1, 9): #goes through all the dataset files and adds the inputs and outputs to x and y
a, b = prep_dataset(f"data{i}.txt")
for i in a:
x.append(i)
for i in b:
y.append(i)
Building our model
Now that we have prepared our data, we can build our model.
Remember, our model will take a sequence of characters and will predict the next character in that sequence.
When dealing with sequential data, it is best to use recurrent neural networks.
If you don't know how a normal neural network works, I would suggest researching how they work first.
Recurrent neural networks are very useful when working with sequential data.
In sequential data, each data point is influenced by the data points before it, so for predicting the next thing to come in a sequence, having context is crucial.
Normal feed-forward neural networks simply can not model sequential data, since they only pass data from layer to layer, so no notion of time is considered.
Recurrent neural networks, however, have layers that loop their outputs back into themselves, which allows for the network to have context.
The layer looks at each element/time-step in the sequence and produces an output and what is known as a hidden state. This hidden state is then passed back into the layer when it looks at the next time step, which preserves context.
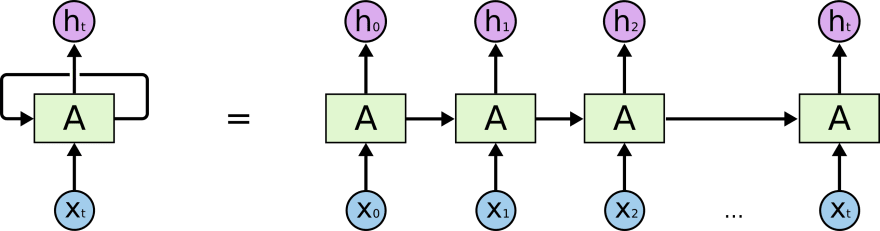
https://colah.github.io/posts/2015-08-Understanding-LSTMs/img/RNN-unrolled.png
Vanishing Gradients
RNNs, however, suffer from "short term memory loss".
This means that, information from far back in the sequence gets lost as the time-step increases. This is caused by vanishing gradients.
When a neural network trains, it calculates the derivative/gradient of its loss function with respect to all its weights. This gradient is then used to adjust the weights. As the loss is backpropagated through each layer, the gradient gets smaller and smaller, meaning that it will have a small effect on the weights in those layers. The early layers of a neural network do very little learning because of this.
With RNNs, this vanishing gradient means that early time-steps in a sequence and "forgot" about by the network, so have no influence in the output.
This can be fixed by using LSTMs and GRUs, which are special types of RNNs which solve the vanishing gradient problem. They have gates which determine what to preserve or remove from the hidden states it receives, which allow it to have "long term memory".
This post here explains RNNs to greater detail.
With the theory out the way, we can use Tensorflow to build our model.
The code should be self-explanatory if you are familiar with the Tensorflow API.
def build_model():
model = tf.keras.Sequential([
tf.keras.layers.LSTM(128, input_dim=get_character_count(), return_sequences=True),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64)),
tf.keras.layers.Dense(32),
tf.keras.layers.Dense(get_character_count(), activation="softmax")
])
model.compile(loss=tf.keras.losses.CategoricalCrossentropy(), optimizer=tf.keras.optimizers.Adam(0.01))
return model
def train_model(model, x, y):
print ("Training...")
model.fit(x, y, epochs=30)
model.save("save")
Training and using our model
To train our model, all we have to do is add a few more lines to our code.
Here is what our final code for training our model will look like
#train.py
import numpy as np
import tensorflow as tf
def get_character_count():
#returns the number of possible characters
alphabet = get_alphabet()
return len(alphabet)
def get_alphabet():
#returns the list of all characters we will allow from our dataset (the lower case alphabet, spaces and new lines)
return list("abcdefghijklmnopqrstuvwxyz \n")
def text_to_vector(text):
#takes in a text and returns it as a sequence of one-hot encodings, representing each character in the text
alphabet = get_alphabet()
vector = []
for char in text:
if char.lower() in alphabet:
one_hot = [0] * get_character_count()
index = alphabet.index(char.lower())
one_hot[index] = 1
vector.append(one_hot)
return vector
def prep_dataset(file):
#this function takes the file name of where certain text data is stored and returns the input sequences array and output characters array
text = open(file, "r").read()
vec = text_to_vector(text) #one-hot encoding the text
xs = [] #input sequence array
ys = [] #output character array
i = 0
while i < len(vec) - 15: #loop for finding each substring of length 15
x = vec[i:i+15] #input sequence
y = vec[i+15] #output character
xs.append(x)
ys.append(y)
i += 1
return xs, ys
def build_model():
model = tf.keras.Sequential([
tf.keras.layers.LSTM(128, input_dim=get_character_count(), return_sequences=True),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64)),
tf.keras.layers.Dense(32),
tf.keras.layers.Dense(get_character_count(), activation="softmax")
])
model.compile(loss=tf.keras.losses.CategoricalCrossentropy(), optimizer=tf.keras.optimizers.Adam(0.01))
return model
def train_model(model, x, y):
print ("Training...")
model.fit(x, y, epochs=30)
model.save("save")
if __name__ == "__main__":
model = build_model()
x = [] #input sequences
y = [] #output characters
for i in range(1, 9): #goes through all the dataset files and adds the inputs and outputs to x and y
a, b = prep_dataset(f"data{i}.txt")
for i in a:
x.append(i)
for i in b:
y.append(i)
train_model(model, np.array(x, dtype=float), np.array(y, dtype=float))
Name that file "train.py"
And now all we need to do is use our model.
We want our bot to ask the user for an input string and we will use our model to produce some lyrics.
However, since our model only produces one letter at a time, we would need to do the following.
1. Start with input sequence
2. Pass input sequence to model to predict next character
3. Add this character to the input sequence and drop off the first letter of the sequence
4. Repeat steps 2 and 3 however times you want to produce a set of lyrics
#run.py
import tensorflow as tf
import numpy as np
from train import get_alphabet, text_to_vector
from autocorrect import Speller
spell = Speller()
def gen_text(model, inp, len):
#inp = input sequence
#len = no. of characters to produce
alphabet = get_alphabet()
res = inp #final output
for i in range(len):
vec = text_to_vector(inp) #encoding the input
vec = np.expand_dims(vec, axis=0) #formatting it so it matches the input shape for our model
index = np.argmax(model.predict(vec)) #passing the input to our model
letter = alphabet[index] #decoding our output to a letter
res += letter #adding the letter to our output string
inp += letter #adding the letter to the input sequence
inp = inp[1:] #dropping off the first letter of input sequence
return spell(res) #return spell checked output
model = tf.keras.models.load_model("save")
while True:
print ("============================")
print (gen_text(model, input("Enter seed phrase: "), 500))
print ("============================")
Since we are producing text on character-level, there are bound to be a quite a few spelling mistakes. I decided to use an autocorrect library in order to clean up our resulting text.
Here are the results
python run.py
[...Tensorflow warnings]
============================
Enter seed phrase: Never will it mend
Never will it mend
now the truth of me
of live
all silence the exist
cannot kill the the family
battery
never
fire
to begin whipping one
no nothing no the matters breath
oh it so met mor the role me can see
and it just free the find
never will the time
nothing is the ear fire
truth wind to see
man me will the death
writing dawn aninimine in me
cannot justice the battery
pounding either as taken my stream
to the will is the existing there is bore
make it our lothenent
born one row the better the existing fro
============================
============================
Enter seed phrase: hold my battery of breath
hold my battery of breath of eyes to set death
oh straw hat your humanity
late the ust comes before but they su
never cared to be
i the estimate it life the lost fill dead
so red
so true
battery
no nothing life now i me crossing ftin
dare
so true myself in me
now pain i mean
so net would
to be
no ripped to are
so prmd
imply solute more is to you hear
taken my end
truth the within
so let it be worth
tro finding
something
mutilation cancellation cancellation
austin
so let it be resting spouses the stan
serve goth
============================
As you can see, the resulting text doesn't make too much sense...
However, it can string together some phrases that make sense.
This can be improved by implementing a model to produce text on a word level or using a larger dataset.
You could also look into using technologies like GPT, which has billions of parameters and produces extremely human-like text.

{kind=link}
Top comments (0)