
Facial Recognition, Object Detection and automated cancer detection... how do these all work?
At the core of many state-of-the-art image processing models lies Convolutional networks, which use what are known as convolutions to accurately capture the features of an image.
Not only can CNNs be used for image processing, they can also be handy in NLP tasks, often serving as an alternative to recurrent neural nets, due to the fact they can be trained much faster. This article, however, will focus mainly on CNNs with an image processing task in mind.
What are Convolutions?
At the core of CNNs is an operation known as a "convolution".
Each convolutional layer performs this operation.
A convolution uses a filter and passes this filter over a given 2D array of numbers, performing a weighted sum using the numbers the filter passes over to create a feature map.
For example...

As the diagram shows, a 3x3 filter and a 6x6 2D array of numbers have been setup.
Now let's do the first step of passing this filter over the 2D array...

The filter is applied to the first 3x3 section of the 2D array, performing a weighted sum of the numbers it covers.
In this case, the weighted sum is (0.4*1) + (0.2*0) + (1.0*1) + (0.7*0) + (0.1*2) + (0.2*0) + (0.7*1) + (0.3*0) + (1.0*1) = 3.3
The result of this sum is then added into the feature map.
Stride length specifies how many columns the filter should move across after doing a weighted sum. In our example, we will set the stride length to 1.
This means the following occurs...

This process repeats until the filter has passed through the whole 2D array, forming a full feature map.
In terms of image processing, images can be represented as a 2D array of numbers, with each element representing an image pixel.
After a convolution is applied, the feature map, if a useful filter is used, should represent a meaningful feature of the image.
Exploring convolution filters
There are some commonly known filters, which result in interesting feature maps.
Below is a Gaussian blur filter...
and here is a short script which applies this convolves an image using this filter and shows the result...
from matplotlib import image
from matplotlib import pyplot
from scipy.ndimage import convolve
import numpy as np
def rgb2gray(rgb):
r, g, b = rgb[:,:,0], rgb[:,:,1], rgb[:,:,2]
gray = 0.2989 * r + 0.5870 * g + 0.1140 * b
return gray
image = rgb2gray(image.imread('city.jpg')) #converts to grayscale for simpler convolving
blur_kernel = np.array([[0, 1, 0], [1, 1, 1], [0, 1, 0]])
pyplot.imshow(image, cmap="gray", vmin=np.min(image), vmax=np.max(image))
pyplot.show()
convolved = convolve(image, blur_kernel)
pyplot.imshow(convolved, cmap="gray", vmin=np.min(image), vmax=np.max(image))
pyplot.show()
Using this script, if we inputted this image...

the convolution's feature map would look like this...
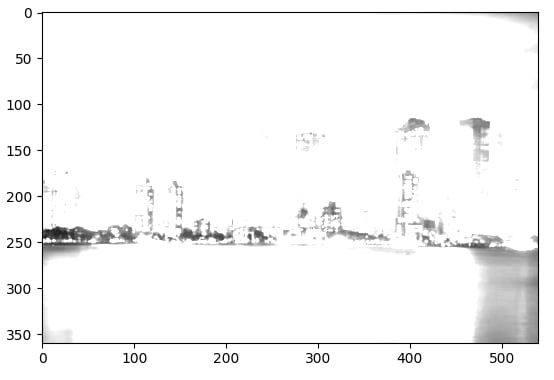
As you can see, this particular filter blurs an image its given.
Another well known filter is this edge detection filter...
Here is the same script, but the kernel/filter has been changed
from matplotlib import image
from matplotlib import pyplot
from scipy.ndimage import convolve
import numpy as np
def rgb2gray(rgb):
r, g, b = rgb[:,:,0], rgb[:,:,1], rgb[:,:,2]
gray = 0.2989 * r + 0.5870 * g + 0.1140 * b
return gray
image = rgb2gray(image.imread('city.jpg'))
edge_kernel = np.array([[0, 1, 0], [1, -4, 1], [0, 1, 0]])
pyplot.imshow(image, cmap="gray", vmin=np.min(image), vmax=np.max(image))
pyplot.show()
convolved = convolve(image, edge_kernel)
pyplot.imshow(convolved, cmap="gray", vmin=np.min(image), vmax=np.max(image))
pyplot.show()
and here is the resulting image...

As shown, this particular filter detects any edges in the input image.
Hopefully, you can see that filters are used to pick out specific features in an image and we can use different filters to pick out different features we would like to see.
How are Convolutions used in CNNs?
Learning Filters
Obviously, manually specifying what convolution filters the network should use would most likely yield poor results.
CNNs initially start with random filters and adjust them during the training process, which eventually results in the optimal filters which pick out specific features in the input, which would not be obvious to a human eye.
Multiple Filters
A convolutional layer does not just use one filter - they learn many filters in parallel, usually from 32 to 512 filters.
This allows the network to look at the input from different perspectives and pick up very specific details within the image e.g certain curve shapes.
Multiple Channels
Coloured images consists of channels, usually having one channel for each RGB value.
Images will now have a 3D shape, meaning the filter must also have a 3D shape e.g having a 3x3x3 filter instead of a 3x3.
The mechanism is the same, instead the weighted sum happens across multiple channels instead of one.
Working with multiple channels allows the network to work with more data from images and, therefore, develop more complex understandings of them.
Pooling
Along with Convolutional layers, pooling layers are commonly used.
There are 3 main types of Pooling:
-Average Pooling
-Max Pooling
-Global Pooling
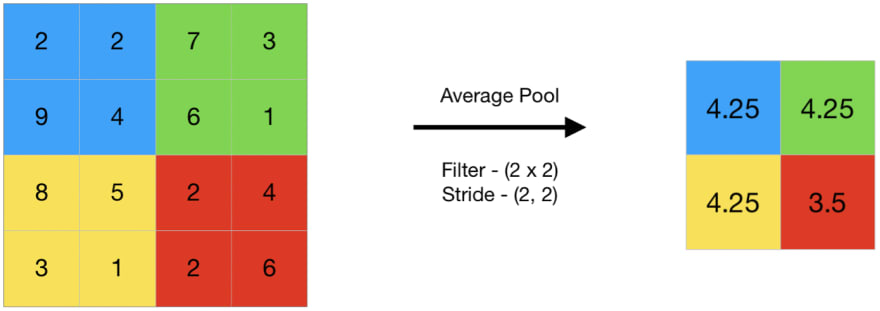
Pooling is a type of dimensional reduction, where a window slides across a 2D array of numbers and the numbers in within this window is reduced to a single number.
Average Pooling
The average of all numbers within the window is taken and kept into the new resulting 2D array.
Max Pooling
The largest number within the window is taken and kept into the new resulting 2D array.

Global Pooling
If you wanted to pool a 3D array (meaning the input has channels), you could either Global Max Pool it or Global Average Pool it.
They reduce the 3 channels into 1 channel using the maximum channel values or average channel values respectively.
Thank You
Thank you for reading and hopefully you understand the theory behind CNNs.
If you are interested in implementing a CNN, here is how you could do it in Tensorflow.

Top comments (0)