
A good database index can improve your SQL query speeds by 99% or more.
Let’s take a table with 1 billion, 16 byte names and a disk with a 10ms seek time and a 10MB/s transfer rate.
If we wanted to find "John Smith" in this table, a regular search that has to check every single name in sequential order would take ~2 hours (.016ms transfer time * 500M rows on average, assume 0 seek time because sequential).
This same search with a database index would only take ~0.3 seconds ((10ms seek time + .016ms transfer time) * log(1*10^10)). A 99.99% speed improvement.
But database indexes also use increased overhead and can degrade performance if not used correctly.
This article will cover the main considerations for creating the right index for your database:
- Index type
- Selecting the correct column
- Choosing how many indexes to create
Download Arctype to follow along with the examples below and create an index on your own database.
What is a Database Index?
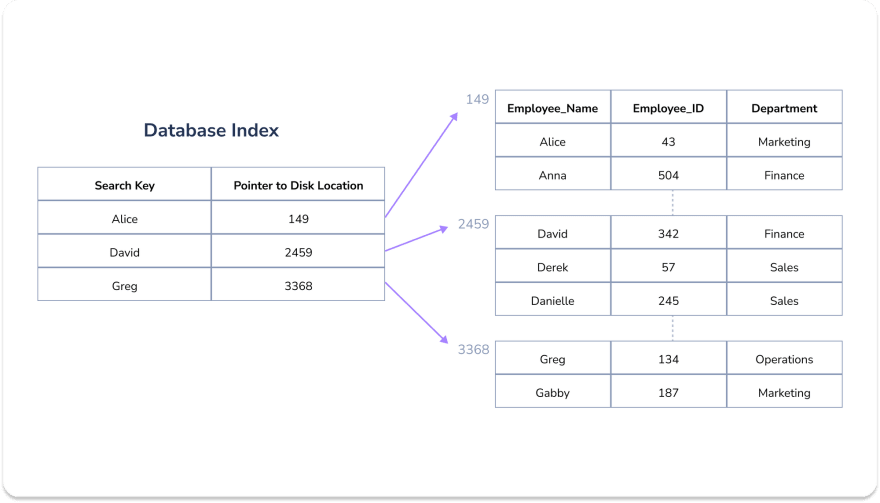
A database index is a data structure used to organize data so that it is easier to search.
Indexes consist of a set of tuples. The first tuple value is the search key, and the second contains a pointer(s) to a block on the hard drive where the entire row of data is stored.
These tuples are then organized into different data structures (i.e. B-tree, Hash, etc) depending on the database index type.
To understand how a tree data structure speeds up search performance, I recommend playing with some of the interactive visualizations online.
Which Postgres Index Type Should You Use?
Postgres offers 6 different index types to solve for different use cases.
Here's a breakdown of their advantages and disadvantages:
| Type | Performance | When to use? |
|---|---|---|
| B-Tree (Most common) | O(log(n)) insertions and queries | Can be used for both equality and range queries (i.e. <, =, >, BETWEEN, IN, etc) |
| Hash | O(1) (faster than B-tree) | Only works for equality comparisons. Hash indexes are not recommended by Postgres beecause they can product inaccurate results |
| Generalized Search Tree (GiST) | O(log(n)) for insertion and queries | Used for operations for beyond equality and range comparisons on geometric data types (i.e. <) |
| Space-partitioned GiST (SP-GiST) | O(log(n)) for insertion and queries | Non-balanced, disk-based data structures (i.e. quad-trees, k-d trees) |
| Generalized Inverted Indexes (GIN) | O(log(n) for queries. Longer insertion time. | Indexing data types that map multiple values to one row (i.e. arrays and full text search) |
| Block Range Index (BRIN) | 20X faster than B-tree and a 99%+ space savings | Table entries have to be ordered in the same format as the data on disk |
Choosing the Right Database Index
Creating an index does not guarantee better database performance. Every time you write to a table with an index, the database engine is updating both the table and any impacted indexes.
This is how you can decide which table columns to use for an index:
- Choose a column that is frequently queried but not frequently changed (add/delete)
- The column has a referential integrity constraint
- The column has a UNIQUE key integrity constraint.
Every modern database engine also has a query planner that decides how each query will be run. In some scenarios it's possible that queries you would expect to use your index are actually doing sequential scans. To check if the query plan is using your index, you can run EXPLAIN.
For instance, running EXPLAIN on this example shows that it is using a sequential scan instead of an index.
EXPLAIN SELECT * FROM tenk1 WHERE unique1 < 7000;
QUERY PLAN
-----------------------------------------------------------------
Seq Scan on tenk1 (cost=0.00..483.00 rows=7001 width=244)
Filter: (unique1 < 7000)
How many indexes should I use?
It depends. If you're managing a table with frequent changes, then you probably want less overhead with indexes. But on the other hand if you're making mostly reads from the table, then adding additional indexes would probably speed up performance.
Before adding a new index, check if your current indexes are actually slowing down your CPU.
How to Create an Index in Postgres - Syntax
Postgres index examples are provided in the following sections. In the scope of this article, the examples include:
- Create Index : Defining a new index.
- Drop Index : Removing an index.
- List Index : Listing all indexes.Unique Index: Defining unique indexes.
- Unique Index: Defining unique indexes.
How to create an index
CREATE INDEX index_name ON table_name USING [method]
(
column_name [ASC | DESC] [NULLS {FIRST | LAST }],
...
);
The optional ASC/DESC and NULLS LAST parameters are beneficial for data that you plan on retrieving in sorted order, and you want the null values to appear first or last in the last.
How to create a partial index
You can also create an index on only a subset of a table.
CREATE INDEX employee_index ON employees (employee_id)
WHERE employee_id > 200;
A partial index is beneficial in situations where there are large clusters of data with the same index value. Even if this data is indexed, the Postgres query planner will usually use a sequential search because the data has the same values. So a partial index can remove clusters of data with the same index value and save space.
How to remove an index
DROP INDEX index_name;
How to find existing indices
Postgres automatically creates a pg_indexes table that you can query to find existing indexes in a database.
SELECT
indexname,
indexdef
FROM
pg_indexes
WHERE
tablename = 'employees';
Postgres Reindex Explained
Reindex drops an existing index in a table and rebuilds it using the current table values. The most common scenario for using reindex is when the data has changed significantly, and there are now existing pages that are inefficiently using space.
A routine reindexing of your database can reduce the index size and improve performance.
## Rebuild a specific index
REINDEX INDEX my_index;
## Rebuild every index in a table
REINDEX TABLE my_table;
## Rebuild every index in a database
REINDEX DATABASE my_database;
Takeaways
A properly created database index can improve query performance by 99% or more.
This article covered the main considerations for creating a database index that improves performance instead of slowing it down:
- Index type
- Selecting the correct column
- Choosing how many indexes to create
Now that you've optimized your query performance, it's time to speed up your SQL workflow. Arctype's collaborative SQL client allows you to easily share databases, queries, and visualizations with anyone.

Top comments (0)