
Explore some of the best Python libraries and frameworks available for web scraping and learn how to use them in your projects.
Getting started with web scraping in Python
Python is one of the most popular programming languages out there and is used across many different fields, such as AI, web development, automation, data science, and data extraction.
For years, Python has been the go-to language for data extraction, boasting a large community of developers as well as a wide range of web scraping tools to help scrapers extract almost any data they wish from the web.
This article will explore some of the best libraries and frameworks available for web scraping in Python and provide a quick sample of how to use them in different scraping scenarios.
Requirements
To fully understand the content and code samples showcased in this post, you should:
Have Python installed on your computer
Have a basic understanding of CSS selectors
Be comfortable navigating the browser DevTools to find and select page elements
HTTP Clients
In the context of web scraping, HTTP clients are used for sending requests to the target website and retrieving information such as the website's HTML code or JSON payload.
Requests

Requests is the most popular HTTP library for Python. It is supported by solid documentation and has been adopted by a huge community.
⚒️ Main Features
Keep-Alive & Connection Pooling
Browser-style SSL Verification
HTTP(S) Proxy Support
Connection Timeouts
Chunked Requests
⚙️ Installation
pip install requests
💡 Code Sample
Send a request to the target website, retrieve its HTML code, and print the result to the console.
import requests
response = requests.get('https://news.ycombinator.com/')
print(response.text)
HTTPX

HTTPX is a fully featured HTTP client library for Python 3, including an integrated command-line client while providing both sync and async APIs.
⚒️ Main Features
A broadly requests-compatible API
An integrated command-line client
Standard synchronous interface, but with async support if you need it
Fully type annotated
⚙️ Installation
# Using pip
pip install httpx
# For Python 3 macOS users
pip3 install httpx
💡 Code Sample
Similar to the Requests example, we will send a request to the target website, retrieve the HTML of the page and print it to the console along with the request status code.
import httpx
response = httpx.get('https://news.ycombinator.com/')
status_code = response.status_code
html = response.text
print(status_code, html)
HTML and XML parser
In web scraping, HTML and XML parsers are used to interpret the response we get back from our target website, often in the form of HTML code.* A library such as Beautiful Soup will help us parse this response and extract data from websites.*
Beautiful Soup

Beautiful Soup (also known as BS4) is a Python library for pulling data out of HTML and XML files with just a few lines of code. BS4 is relatively easy to use and presents itself as a lightweight option for tackling simple scraping tasks with speed.
⚒️ Main features
Implements a subset of core jQuery, providing developers with a familiar and easy-to-use syntax.
Works with a simple and consistent DOM model, making parsing, manipulating, and rendering incredibly efficient.
Offers great flexibility, being able to parse nearly any HTML or XML document.
⚙️ Installation
pip install beautifulsoup4
💡 Code Sample
Let's now see how we can use Beautiful Soup + HTTPX to extract the title content, rank, and URL from all the articles on the first page of Hacker News.
from bs4 import BeautifulSoup
import httpx
response = httpx.get("https://news.ycombinator.com/news")
yc_web_page = response.content
soup = BeautifulSoup(yc_web_page)
articles = soup.find_all(class_="athing")
for article in articles:
data = {
"URL": article.find(class_="titleline").find("a").get('href'),
"title": article.find(class_="titleline").getText(),
"rank": article.find(class_="rank").getText().replace(".", "")
}
print(data)
A few seconds after running the script, we will see a dictionary containing each article's URL, ranking, and title printed on our console.
Output example:
{'URL': 'https://vpnoverview.com/news/wifi-routers-used-to-produce-3d-images-of-humans/', 'title': 'WiFi Routers Used to Produce 3D Images of Humans (vpnoverview.com)', 'rank': '1'}
{'URL': 'https://openjdk.org/jeps/8300786', 'title': 'JEP draft: No longer require super() and this() to appear first in a constructor (openjdk.org)', 'rank': '2'}
{'URL': 'item?id=34482433', 'title': 'Ask HN: Those making $500+/month on side projects in 2023 -- Show and tell', 'rank': '3'}
{'URL': 'https://www.solipsys.co.uk/new/ThePointOfTheBanachTarskiTheorem.html?wa22hn', 'title': 'The Point of the Banach-Tarski Theorem (solipsys.co.uk)', 'rank': '4'}
{'URL': 'https://initialcommit.com/blog/git-sim', 'title': 'Git-sim: Visually simulate Git operations in your own repos (initialcommit.com)', 'rank': '5'}
{'URL': 'https://www.cell.com/cell-reports-medicine/fulltext/S2666-3791(22)00474-8', 'title': 'Brief structured respiration enhances mood and reduces physiological arousal (cell.com)', 'rank': '6'}
{'URL': 'https://en.wikipedia.org/wiki/I,_Libertine', 'title': 'I, Libertine (wikipedia.org)', 'rank': '7'}
{'URL': 'item?id=34465956', 'title': 'Ask HN: Why did BASIC use line numbers instead of a full screen editor?', 'rank': '8'}
{'URL': 'https://arxiv.org/abs/2203.03456', 'title': 'Negative-weight single-source shortest paths in near-linear time (arxiv.org)', 'rank': '9'}
{'URL': 'https://onesignal.com/careers', 'title': 'OneSignal (YC S11) Is Hiring Engineers (onesignal.com)', 'rank': '10'}
{'URL': 'https://neelc.org/posts/chatgpt-gmail-spam/', 'title': "Bypassing Gmail's spam filters with ChatGPT (neelc.org)", 'rank': '11'}
{'URL': 'https://cyber.dabamos.de/88x31/', 'title': 'The 88x31 GIF Collection (dabamos.de)', 'rank': '12'}
{'URL': 'https://www.middleeasteye.net/opinion/david-graeber-vs-yuval-harari-forgotten-cities-myths-how-civilisation-began', 'title': 'The Dawn of Everything challenges a mainstream telling of prehistory (middleeasteye.net)', 'rank': '13'}
{'URL': 'https://blog.thinkst.com/2023/01/swipe-right-on-our-new-credit-card-tokens.html', 'title': 'Detect breaches with Canary credit cards (thinkst.com)', 'rank': '14'}
{'URL': 'https://www.atlasobscura.com/articles/heritage-appalachian-apples', 'title': 'Appalachian Apple hunter who rescued 1k 'lost' varieties (2021) (atlasobscura.com)', 'rank': '15'}
{'URL': 'https://www.workingsoftware.dev/software-architecture-documentation-the-ultimate-guide/', 'title': 'The Guide to Software Architecture Documentation (workingsoftware.dev)', 'rank': '16'}
{'URL': 'https://arstechnica.com/tech-policy/2023/01/supreme-court-allows-reddit-mods-to-anonymously-defend-section-230/', 'title': 'Supreme Court allows Reddit mods to anonymously defend Section 230 (arstechnica.com)', 'rank': '17'}
{'URL': 'https://neurosciencenews.com/insula-empathy-pain-21818/', 'title': 'How do we experience the pain of other people? (neurosciencenews.com)', 'rank': '18'}
{'URL': 'https://lwn.net/SubscriberLink/920158/313ec4305df220bb/', 'title': 'Nolibc: A minimal C-library replacement shipped with the kernel (lwn.net)', 'rank': '19'}
{'URL': 'https://www.economist.com/1843/2017/05/04/the-body-in-the-buddha', 'title': 'The Body in the Buddha (2017) (economist.com)', 'rank': '20'}
{'URL': 'https://simonwillison.net/2023/Jan/13/semantic-search-answers/', 'title': 'How to implement Q&A against your docs with GPT3 embeddings and Datasette (simonwillison.net)', 'rank': '21'}
{'URL': 'https://destevez.net/2023/01/decoding-lunar-flashlight/', 'title': 'Decoding Lunar Flashlight (destevez.net)', 'rank': '22'}
{'URL': 'https://www.hampsteadheath.net/about', 'title': 'Hampstead Heath (hampsteadheath.net)', 'rank': '23'}
{'URL': 'https://www.otherlife.co/francisbacon/', 'title': 'The violent focus of Francis Bacon (otherlife.co)', 'rank': '24'}
{'URL': 'https://arstechnica.com/gaming/2019/10/explaining-how-fighting-games-use-delay-based-and-rollback-netcode/', 'title': 'How fighting games use delay-based and rollback netcode (2019) (arstechnica.com)', 'rank': '25'}
{'URL': 'https://essays.georgestrakhov.com/ai-is-not-a-horse/', 'title': 'AI Is Not a Horse (georgestrakhov.com)', 'rank': '26'}
{'URL': 'https://lawliberty.org/features/the-mystery-of-richard-posner/', 'title': 'The Mystery of Richard Posner (lawliberty.org)', 'rank': '27'}
{'URL': 'https://rodneybrooks.com/predictions-scorecard-2023-january-01/', 'title': 'Rodney Brooks Predictions Scorecard (rodneybrooks.com)', 'rank': '28'}
{'URL': 'https://www.notamonadtutorial.com/how-to-transform-code-into-arithmetic-circuits/', 'title': 'How to transform code into arithmetic circuits (notamonadtutorial.com)', 'rank': '29'}
{'URL': 'https://github.com/jhhoward/WolfensteinCGA', 'title': 'Wolfenstein 3D with a CGA Renderer (github.com/jhhoward)', 'rank': '30'}
Browser automation tools
Browser automation libraries and frameworks have an off-label use for web scraping. Their ability to emulate a real browser is essentialfor access*ing* data on websites that require JavaScript to load their content.**
Selenium

Selenium is primarily a browser automation framework and ecosystem with an off-label use for web scraping. It uses the WebDriver protocol to control a headless browser and perform actions like clicking buttons, filling out forms, and scrolling.
Because of its ability to render JavaScript, Selenium can be used to scrape dynamically loaded content.
⚒️ Main features
Multi-Browser Support (Firefox, Chrome, Safari, Opera...)
Multi-Language Compatibility
Automate manual user interactions, such as UI testing, form submissions, and keyboard inputs.
Dynamic web elements handling
⚙️ Installation
# Install Selenium
pip install selenium
# We will also need to install webdriver-manager to run the code sample below
pip install webdriver-manager
💡 Code Sample
To demonstrate some of Selenium's capabilities, let's go to Amazon, scrape The Hitchhiker's Guide to the Galaxy product page, and save a screenshot of the accessed page.
from selenium import webdriver
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
# Insert the website URL that we want to scrape
url = "https://www.amazon.com/Hitchhikers-Guide-Galaxy-Douglas-Adams-ebook/dp/B000XUBC2C"
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get(url)
# Create a dictionary with the scraped data
book = {
"book_title": driver.find_element(By.ID, 'productTitle').text,
"author": driver.find_element(By.CSS_SELECTOR, '.a-link-normal.contributorNameID').text,
"edition": driver.find_element(By.ID, 'productSubtitle').text,
"price": driver.find_element(By.CSS_SELECTOR, '.a-size-base.a-color-price.a-color-price').text,
}
# Save a screenshot from the accessed page and print the dictionary contents to the console
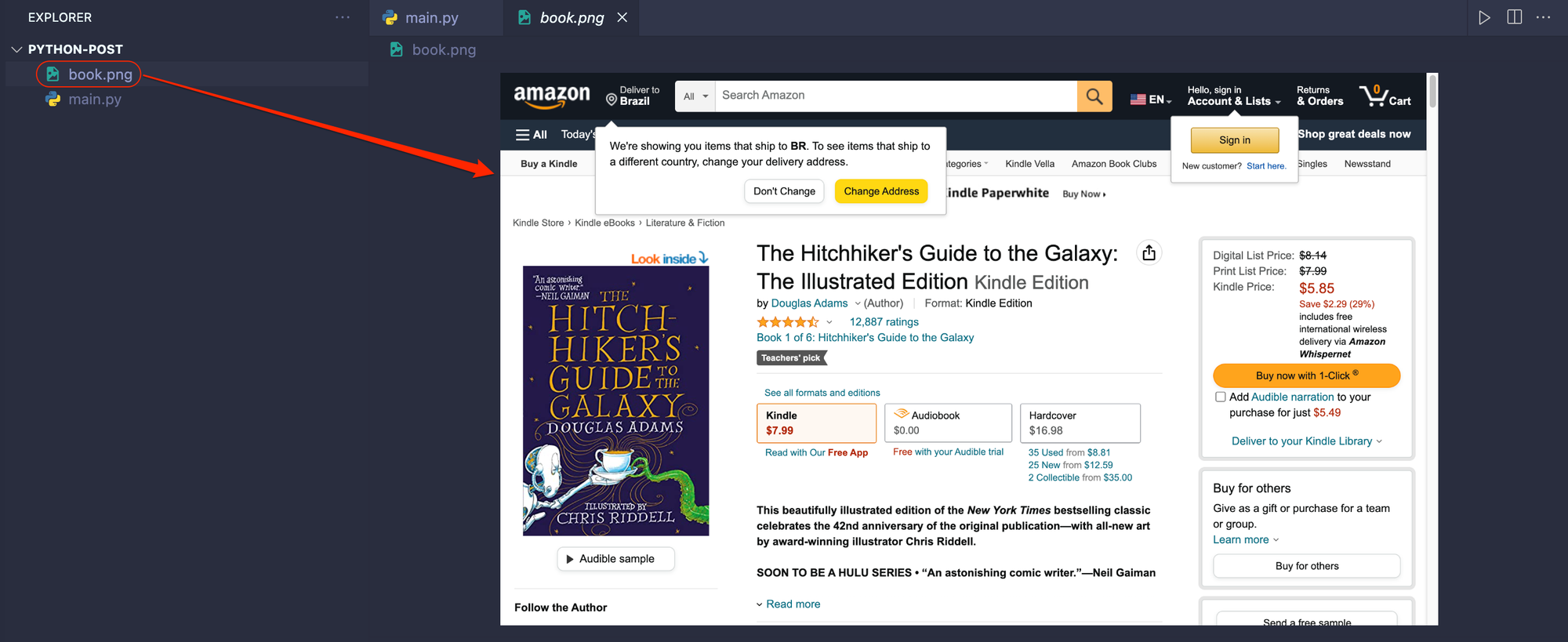
driver.save_screenshot('book.png')
print(book)
After the script finishes its run, we will see an object containing the book's title, author, edition, and prices logged to the console, and a screenshot of the page saved as book.png .
Output example:
{
"book_title": "The Hitchhiker's Guide to the Galaxy: The Illustrated Edition",
"author": "Douglas Adams",
"edition": "Kindle Edition",
"price": "$7.99"
}
Saved image:
Playwright
![]()
By definition, Playwright is an open-source framework for web testing and automation developed and maintained by Microsoft.
Despite having many features in common with Selenium, Playwright is considered a more modern and capable choice for automation, testing, and web scraping in Python.
⚒️ Main features
Auto-wait. Playwright, by default, waits for elements to be actionable before performing actions, eliminating the need for artificial timeouts.
Cross-browser support, being able to drive Chromium, WebKit, Firefox, and Microsoft Edge.
Cross-platform support. Available on Windows, Linux, and macOS, locally or on CI, headless, or headed.
⚙️ Installation
# Using pip
pip install pytest-playwright
# For Python 3 macOS users
pip3 install pytest-playwright
# Install the required browsers
playwright install
💡 Code Sample
To highlight Playwright's features as well as its similarities with Selenium, let's go back to Amazon's website and extract some data from The Hitchhiker's Guide to the Galaxy.
Playwright version:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.firefox.launch(
headless=False
)
page = browser.new_page()
page.goto("https://www.amazon.com/Hitchhikers-Guide-Galaxy-Douglas-Adams-ebook/dp/B000XUBC2C")
# Create a dictionary with the scraped data
book = {
"book_title": page.query_selector('#productTitle').inner_text().strip(),
"author": page.query_selector('.author .a-link-normal.contributorNameID').inner_text().strip(),
"edition": page.query_selector('#productSubtitle').inner_text().strip(),
"price": page.query_selector('.a-size-base.a-color-price.a-color-price').inner_text().strip(),
}
print(book)
page.screenshot(path="book.png")
browser.close()
After the scraper finishes its run, the Firefox browser controlled by Playwright will close, and the extracted data will be logged into the console.
Scrapy: a full-fledged Python web crawling framework
Scrapy

Scrapy is a fast high-level web crawling and web scraping framework written with Twisted, a popular event-driven networking framework, which gives it asynchronous capabilities.
Unlike the tools mentioned earlier, Scrapy is a full-fledged web crawling framework designed specifically for data extraction, with built-in support for handling requests, processing responses, and exporting data.
Additionally, Scrapy provides handy out-of-the-box features, such as support for following links, handling multiple request types, and error handling, making it a powerful tool for web scraping projects of any size and complexity.
⚒️ Main features
Feed exports in multiple formats, such as JSON, CSV, and XML.
Built-in support for selecting and extracting data from HTML/XML sources using extended CSS selectors and XPath expressions
An interactive shell console for trying out the CSS and XPath expressions to scrape data and debug your spiders.
Built-in extensions and middlewares for handling, cookies, HTTP authentication and caching user-agent spoofing, and more
⚙️ Installation
pip install scrapy
📁 Project setup
To demonstrate some Scrapy's features, we will once again extract data from articles displayed on Hacker News.
We will start by scraping the top 30 articles and then use Scrapy's CrawlSpider to follow the available page links and extract data from all the articles on the website.
To begin, let's create a new directory and install Scrapy to initialize the project and create a new spider:
# Create new directory and move into it
mkdir scrapy-project
cd scrapy-project
# Install Scrapy
pip install scrapy
# Initialize project
scrapy startproject scrapydemo
# Generate spider
scrapy genspider demospider https://news.ycombinator.com/
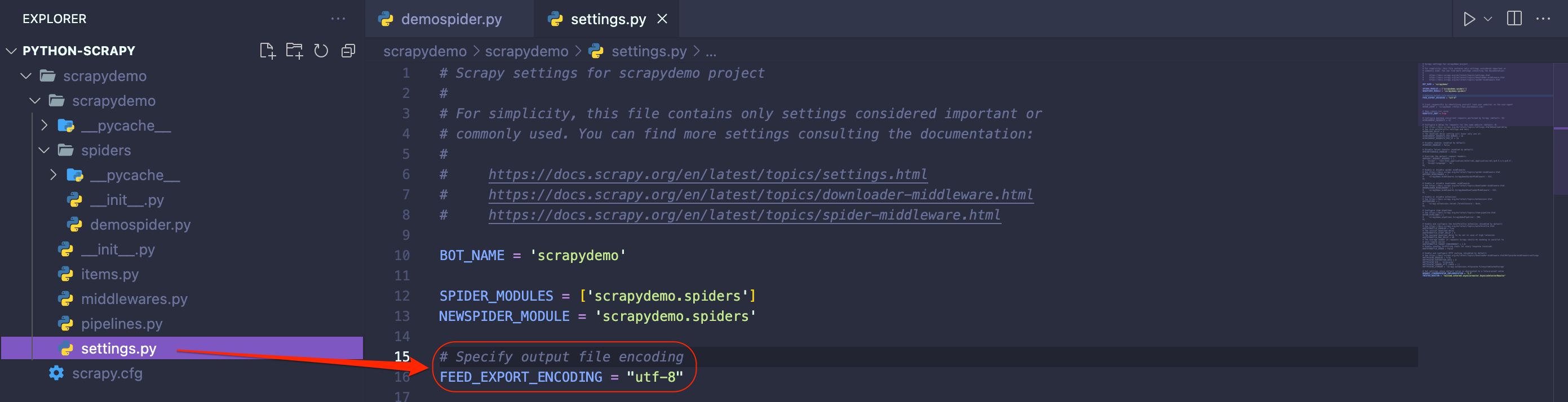
After our spider is generated, let's specify the encoding for the output file, which will contain the data scraped from the target website by adding FEED_EXPORT_ENCODING = "utf-8" to our settings.py file.
💡 Code Sample
Finally, go to the demospider.py file and write some code:
import scrapy
class DemospiderSpider(scrapy.Spider):
name = 'demospider'
def start_requests(self):
yield scrapy.Request(url='https://news.ycombinator.com/')
def parse(self, response):
for article in response.css('tr.athing'):
yield {
"URL": article.css(".titleline a::attr(href)").get(),
"title": article.css(".titleline a::text").get(),
"rank": article.css(".rank::text").get().replace(".", "")
}
Then, let's use the following command to run the spider and store the scraped data in a results.json file:
scrapy crawl demospider -o results.json
🕷️ Using Scrapy's CrawlSpider
Now that we know how to extract data from the articles on the first page of Hacker News let's use Scrapy's CrawlSpider to follow the next page links and collect the data from all the articles on the website.
To do that, we will make some adjustments to our demospider.py file:
# Add imports CrawlSpider, Rule and LinkExtractor 👇
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
# Change the spider from "scrapy.Spider" to "CrawlSpider"
class DemospiderSpider(CrawlSpider):
name = 'demospider'
allowed_domains = ['news.ycombinator.com']
start_urls = ['https://news.ycombinator.com/news?p=1']
# Define a rule that should be followed by the link extractor.
# In this case, Scrapy will follow all the links with the "morelink" class
# And call the "parse_article" function on every crawled page
rules = (
(Rule(LinkExtractor(restrict_css='.morelink'), callback='parse_article', follow=True),)
)
# When using the CrawlSpider we cannot use a parse function called "parse".
# Otherwise, it will override the default function.
# So, just rename it to something else, for example, "parse_article"
def parse_article(self, response):
for article in response.css('tr.athing'):
yield {
"URL": article.css(".titleline a::attr(href)").get(),
"title": article.css(".titleline a::text").get(),
"rank": article.css(".rank::text").get().replace(".", "")
}
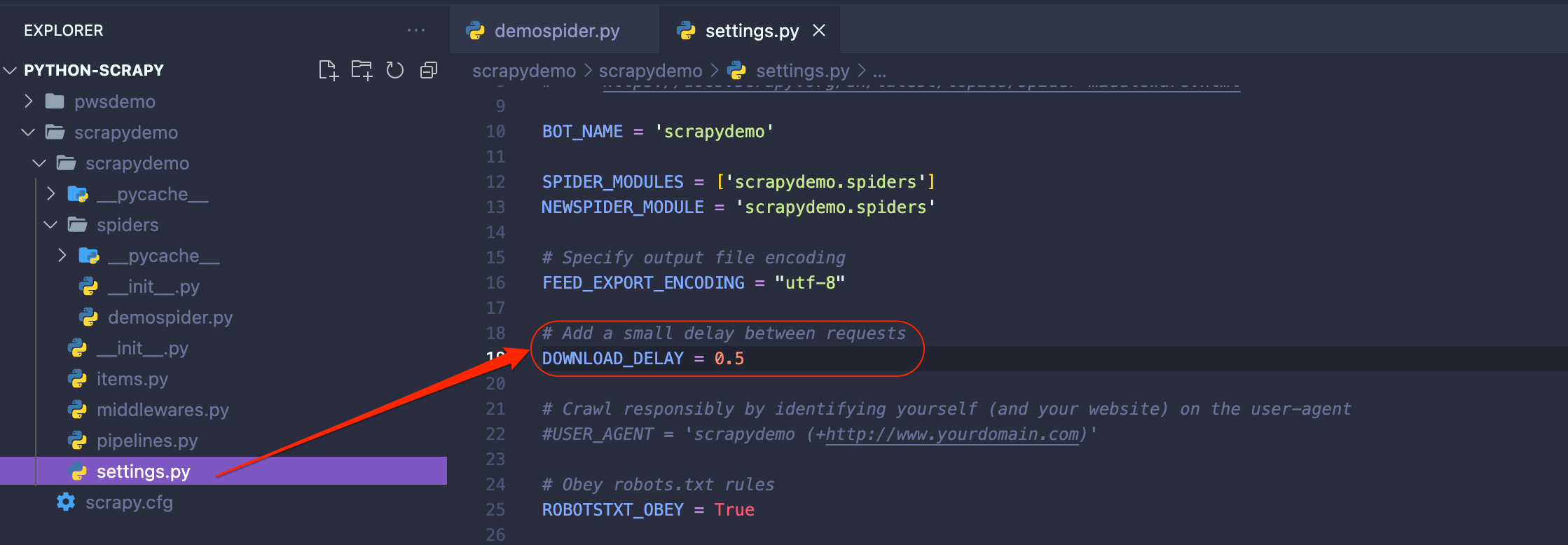
Finally, let's add a small delay between each of Scrapy's requests to avoid overloading the server. We can do that by adding DOWNLOAD_DELAY = 0.5 to our settings.py file.
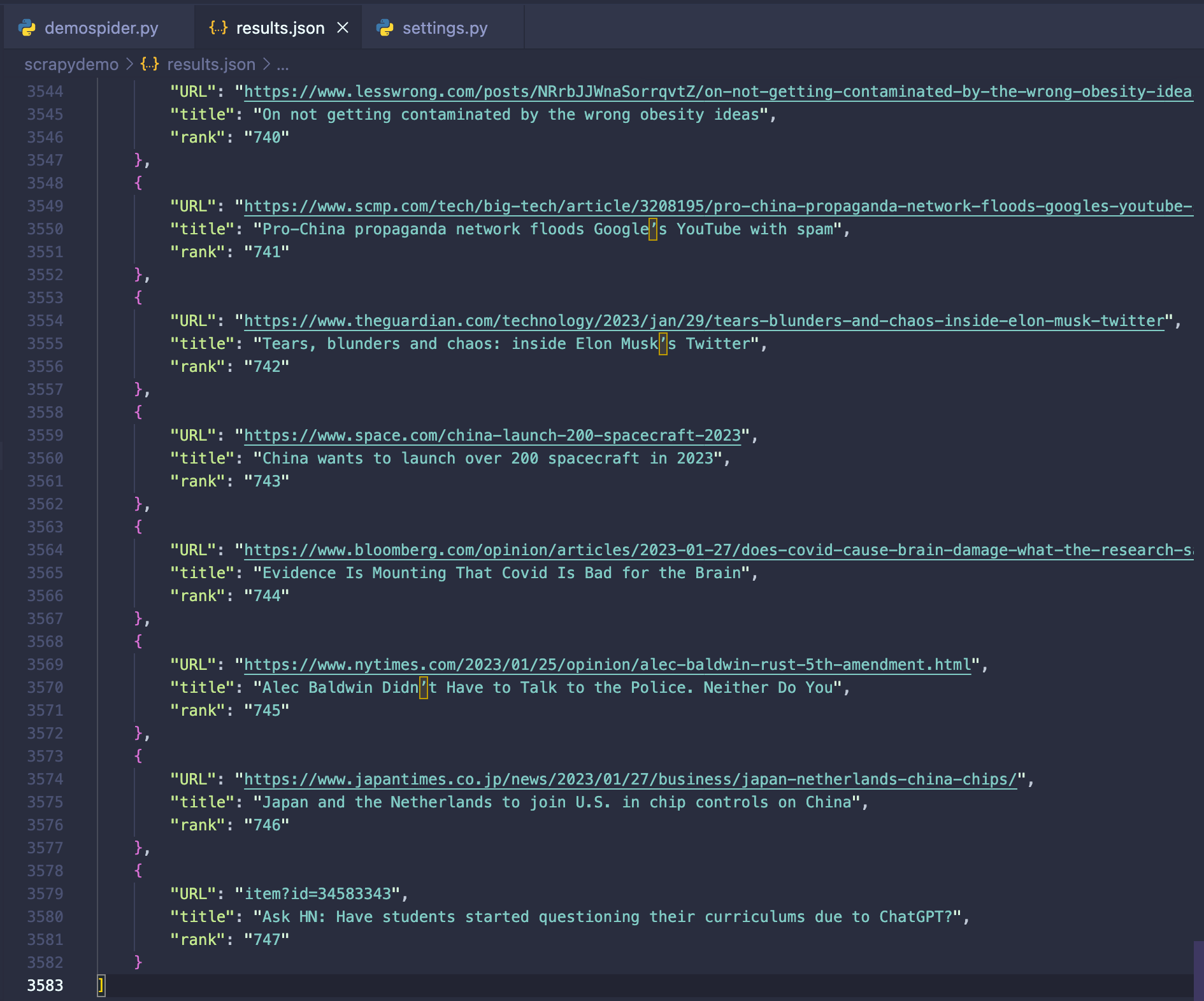
Great! Now we are ready to run our scraper and get the data from all the articles displayed on Hacker News. Just run the command scrapy crawl demospider -o results.json and wait for the run to finish.
Expected output:
🎭 Using Playwright with Scrapy
Scrapy and Playwright are one of the most efficient combos for modern web scraping in Python.
This combo allows us to benefit from Playwright's ability to access dynamically loaded content on websites, and retrieve code from the page, so we can use Scrapy to extract data from it.
To integrate Playwright with Scrapy, we will use the scrapy-playwright library. Then, we will scrape https://www.mintmobile.com/product/google-pixel-7-pro-bundle/ to demonstrate how to extract data from a website using Playwright and Scrapy.
Mint Mobile requires JavaScript to load most of the content displayed on its product page, which makes it an ideal scenario for using Playwright in the context of web scraping.
Mint Mobile product page with JavaScript disabled:
![]()
Mint Mobile product page with JavaScript enabled:
![]()
⚙️ Project setup
Start by creating a directory to house our project and installing the necessary dependencies:
# Create new directory and move into it
mkdir scrapy-playwright
cd scrapy-playwright
Installation:
# Install Scrapy and scrapy-playwright
pip install scrapy scrapy-playwright
# Install the required browsers if you are running Playwright for the first time
playwright install
# Or install a subset of the available browsers you plan on using
playwright install firefox chromium
Next, start the Scrapy project and generate a spider:
scrapy startproject pwsdemo
scrapy genspider demospider https://www.mintmobile.com/
Now, let's activate scrapy-playwright by adding DOWNLOAD_HANDLERS and TWISTED_REACTOR to the scraper configuration in settings.py
# scrapy-playwright configuration
DOWNLOAD_HANDLERS = {
"http": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
"https": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
}
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
Great! We are now ready to write some code to scrape our target website.
💡 Code Sample
So, without further ado, let's use Playwright + Scrapy to extract data from Mint Mobile.
import scrapy
from scrapy_playwright.page import PageMethod
class DemospiderSpider(scrapy.Spider):
name = 'demospider'
def start_requests(self):
yield scrapy.Request('https://www.mintmobile.com/product/google-pixel-7-pro-bundle/',
meta= dict(
# Use Playwright
playwright = True,
# Keep the page object so we can work with it later on
playwright_include_page = True,
# Use PageMethods to wait for the content we want to scrape to be properly loaded before extracting the data
playwright_page_methods = [
PageMethod('wait_for_selector', 'div.m-productCard--device')
]
))
def parse(self, response):
yield {
"name": response.css("div.m-productCard__heading h1::text").get().strip(),
"memory": response.css("div.composited_product_details_wrapper > div > div > div:nth-child(2) > div.label > span::text").get().replace(':', '').strip(),
"pay_monthly_price": response.css("div.composite_price_monthly > span::text").get(),
"pay_today_price": response.css("div.composite_price p.price span.amount::attr(aria-label)").get().split()[0],
};
Expected output:
Finally, run the spider using the command scrapy crawl demospider -o results.json to scrape the target data and store it in a results.json file:
[
{
"name": "Google Pixel 7 Pro",
"memory": "128GB",
"pay_monthly_price": "50",
"pay_today_price": "589"
}
]
Learning resources 📚
If you want to dive deeper into some of the libraries and frameworks we presented during this post, here is a curated list of great videos and articles about the topic:
General web scraping
Beautiful Soup Tutorials
Browser automation tools
Scrapy
Discord
Finally, don't forget to join the Apify & Crawlee community on Discord to connect with other web scraping and automation enthusiasts. 🚀
 discord.com
discord.com





Top comments (3)
Extremely detailled ! Thanks
nice detailed tutorial!
Cool, thanks for information