This post analyzes ops & maintenance solutions with experiences taken from real production scenarios for data sharding and other functions provided by ShardingSphere-Proxy Version 5.1.0.
Unless otherwise specified, in the following examples, when we say “database” we refer to MySQL.
What does ShardingSphere-Proxy do?
ShardingSphere-Proxy allows users to use Apache ShardingSphere just as if it were a native database.
To gain a better understanding of what’s ShardingSphere-proxy, let’s take a look at its definition provided, by Apache ShardingSphere’s official website:
ShardingSphere-Proxy is a transparent database proxy that provide a database server containing database binary protocols designed to support heterogeneous languages.
Currently, it supports MySQL and PostgreSQL (and PostgreSQL-based databases, such as openGauss) and any related terminals (such as MySQL Command Client, https://blog.devart.com/mysql-command-line-client.html Workbench, etc.) that are compatible with MySQL or PostgreSQL protocols to operate data. It’s a DBA-friendly tool.

It’s worth noting that ShardingSphere-Proxy is a service process. In terms of client-side program connections, it is similar to a MySQL database.
Why you need ShardingSphere-Proxy
ShardingSphere-Proxy is a good choice when:
- sharding rules or other rules are used; because data will be distributed across multiple database instances, inevitably making management inconvenient.
- non-Java developers need to leverage ShardingSphere capabilities.
1. Application scenarios
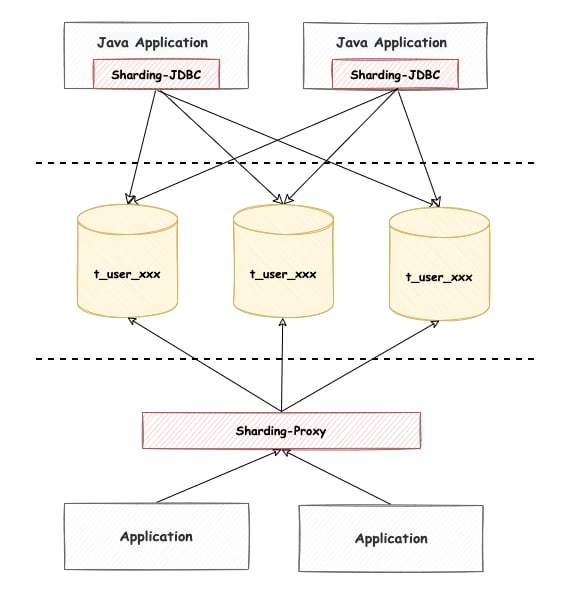
There are many scenarios where ShardingSphere-JDBC is used for data sharding. If you have a user table and need to perform horizontal scaling with Hash for the User ID property, the way the client connects to the database is like this:

Below are three real production scenarios:
- A testing engineer wants to see the information of user ID 123456 in databases & tables, and you need to tell the engineer which subtable the user is in.
- You need to find out the total user growth in 2022 and overall user information for drafting a yearly report.
- Your company is going to hold its 8th-anniversary event and you are required to provide a list of active users who have been registered for over 8 years. Since the data is distributed across database shards and table shards, it is not easy to complete the above-mentioned tasks. If you develop code every time to satisfy these temporary requirements, it’ll be inefficient to say the least. ShardingSphere-Proxy is perfect for these scenarios.
ShardingSphere-Proxy hides the actual backend databases, so the user operates the client side the same way as a database.
For example, t_user is split into several real tables at the database level, that is from t_user_0 to t_user_9 . While operating ShardingSphere-Proxy on the client side, the user only needs to know one logical table t_user,and routing to the real tables is executed inside ShardingSphere-Proxy.
1. Logical table: The logical name of the horizontally-scaled databases/tables with the same structure. A logical table is the logical identifier of tables in SQL. For example, user data is sharded into 10 tables according to the significant digits of the primary key, that is, t_user_0 to t_user_9 , and their common logical table is named t_user.
2. Actual table: The physical table actually exists in databases after scale-out, that is, the above-mentioned t_user_0 to t_user_9 .

2. The differences between ShardingSphere-JDBC and ShardingSphere-Proxy
After reading the above description, you probably feel that ShardingSphere-Proxy and ShardingSphere-JDBC are so similar. So what are the differences between the two?

Check out more on the differences between the two below:
ShardingSphere-JDBC is a
.jarpackage. Its bottom layer completes SQL parsing, routing, rewriting, execution, and other processes by rewriting JDBC components. You should add the configuration files to implement the corresponding functions in the project, making it intrusive to applications.ShardingSphere-Proxy is a process service. In most cases, it is positioned as a productivity tool to assist operations. It disguises itself as a database, making itself non-intrusive to applications. The SQL execution logic in ShardingSphere-Proxy is the same as in ShardingSphere-JDBC because they share the same kernel.
Since ShardingSphere-Proxy is non-intrusive to applications, and it shares the same kernel with ShardingSphere-JDBC — so why do we still need ShardingSphere-JDBC?
When an application directly operates databases through ShardingSphere-JDBC, there is only one network I/O. However, when the application connects to ShardingSphere-Proxy, one network I/O, and then ShardingSphere-Proxy operates databases, and another network I/O occurs, in total two network I/O requests.
There is one more layer of application called link, which is more likely to cause a data traffic bottleneck and potential risks to the application. In general, it’s suggested that an application should be used together with ShardingSphere-JDBC.
Of course, ShardingSphere-JDBC and ShardingSphere-Proxy can be deployed simultaneously with a hybrid architecture. ShardingSphere-JDBC is suitable for high-performance lightweight Online Transaction Processing (OLTP) applications developed in Java, while ShardingSphere-Proxy is perfect for Online Analytical Processing (OLAP) applications and scenarios for managing and operating sharding databases.
Quick Start Guide
There are three setup methods to install ShardingSphere-Proxy: binary package, Docker, and Helm. Stand-alone deployment and clustered deployment are also provided. Here, we take the standalone binary package as an example:
Get the ShardingSphere-Proxy binary installation package at this link;
Decompress it and then modify
conf/server.yamland files starting with theconfig-prefix to configure sharding, read/write splitting and other functions;If you use Linux as operating system, please run
bin/start.sh.For Windows operating systems, please runbin/start.batto bootup ShardingSphere-Proxy.
The file directory looks like this:
├── LICENSE
├── NOTICE
├── README.txt
0009 ─ ─ bin #Start/stop script
0009 ─ ─ conf #service configuration, data sharding, read/write splitting, data encryption, and other function configuration files
├── lib # Jar package
└── licenses
1. Copy MySQL Java connector to the ext-lib package
Download the driver mysql-connector-java-5.1.47.jar (Click the link to download) or mysql-connector-java-8.0.11.jar (https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.11/mysql-connector-java-8.0.11.jar) into the ext-lib package. Note:there is no ext-lib package in the initial directory, so you need to create one yourself.
2. Modify the conf/server.yaml configuration file
For server.yaml the default operation mode is Cluster Mode. Below is how to configure the standalone operation mode.
mode:
Type: Standalone #Standalone mode
repository:
type: File
props:
Path: /Users/xxx/software/apache-shardingsphere-5.1.0-shardingsphere-proxy/file #persistent file paths such as metadata configuration
Overwrite: false #Overwrite the existing metadata?
Rules: #Verification Info
- !AUTHORITY
Users: #Init user
- root@%:root
- sharding@:sharding
provider:
type: ALL_PRIVILEGES_PERMITTED
- !TRANSACTION
defaultType: XA
provider Type: Atomikos
- !SQL_PARSER
sqlCommentParseEnabled: true
sqlStatementCache:
initialCapacity: 2000
maximum Size: 65535
concurrencyLevel: 4
parseTreeCache:
initialCapacity: 128
maximum Size: 1024
concurrencyLevel: 4
Props: #public configuration
max-connections-size-per-query: 1
kernel-executor-size: 16 # Infinite by default.
proxy-frontend-flush-threshold: 128 # The default value is 128.
proxy-opentracing-enabled: false
proxy-hint-enabled: false
sql-show: false
check-table-metadata-enabled: false
show-process-list-enabled: false
# Proxy backend query fetch size. A larger value may increase the memory usage of ShardingSphere Proxy.
# The default value is -1, which means set the minimum value for different JDBC drivers.
proxy-backend-query-fetch-size: -1
check-duplicate-table-enabled: false
proxy-frontend-executor-size: 0 # Proxy frontend executor size. The default value is 0, which means let Netty decide.
# Available options of proxy backend executor suitable: OLAP(default), OLTP. The OLTP option may reduce time cost of writing packets to client, but it may increase the latency of SQL execution
# and block other clients if client connections are more than `proxy-frontend-executor-size`, especially executing slow SQL.
proxy-backend-executor-suitable: OLAP
proxy-frontend-max-connections: 0 # Less than or equal to 0 means no limitation.
sql-federation-enabled: false
# Available proxy backend driver type: JDBC (default), ExperimentalVertx
proxy-backend-driver-type: JDBC
Note: if you start a standalone ShardingSphere-Proxy and later need to change Proxy configurations, you need to set
mode.overwritetotrue. By doing so, ShardingSphere-Proxy will reload the metadata after startup.
3. Start ShardingSphere-Proxy
Execute the bootup command: sh bin/start.sh. The default port is 3307, and the port can be replaced by adding parameters to the start script command: sh bin/start.sh 3308 .
To check whether ShardingSphere-Proxy started successfully, execute the check log command: tail -100f logs/stdout.log .
The following information placed on the last line means that the startup is successful:
[INFO ] xxx-xx-xx xx:xx:xx.xxx [main] o.a.s.p.frontend.ShardingSphereProxy - ShardingSphere-Proxy Standalone mode started successfully
Scenarios and applications
Based on actual prouction scenarios, we’d like to show you how you can utilize ShardingSphere-Proxy to meet your expectations.

1. Initialize the database & table
# CREATE DATABASE
CREATE DATABASE user_sharding_0;
CREATE DATABASE user_sharding_1;
# CREATE TABLE
use user_sharding_0;
CREATE TABLE `t_user_0` (
`id` bigint (20) NOT NULL,
`user_id` bigint (20) NOT NULL,
`create_date` datetime DEFAULT NULL,
PRIMARY KEY (`id`)) ENGINE = InnoDB DEFAULT CHARSET = latin1;
CREATE TABLE `t_user_1` (
`id` bigint (20) NOT NULL,
`user_id` bigint (20) NOT NULL,
`create_date` datetime DEFAULT NULL,
PRIMARY KEY (`id`)) ENGINE = InnoDB DEFAULT CHARSET = latin1;
use user_sharding_1;
CREATE TABLE `t_user_0` (
`id` bigint (20) NOT NULL,
`user_id` bigint (20) NOT NULL,
`create_date` datetime DEFAULT NULL,
PRIMARY KEY (`id`)) ENGINE = InnoDB DEFAULT CHARSET = latin1;
CREATE TABLE `t_user_1` (
`id` bigint (20) NOT NULL,
`user_id` bigint (20) NOT NULL,
`create_date` datetime DEFAULT NULL,
PRIMARY KEY (`id`)) ENGINE = InnoDB DEFAULT CHARSET = latin1;
2. Initialize sharding configuration in Proxy
schemaName: sharding_db
dataSources:
ds_0:
url: jdbc:mysql://127.0.0.1:3306/user_sharding_0?serverTimezone=UTC&useSSL=false
username: root
password: root
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
ds_1:
url: jdbc:mysql://127.0.0.1:3306/user_sharding_1?serverTimezone=UTC&useSSL=false
username: root
password: root
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
rules:
- !SHARDING
tables:
t_user:
actualDataNodes: ds_${0..1}.t_user_${0..1}
tableStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: t_user_inline
keyGenerateStrategy:
column: user_id
keyGeneratorName: snowflake
bindingTables:
- t_user
defaultDatabaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: database_inline
defaultTableStrategy:
none:
shardingAlgorithms:
database_inline:
type: INLINE
props:
algorithm-expression: ds_${user_id % 2}
t_user_inline:
type: INLINE
props:
algorithm-expression: t_user_${user_id % 2}
KeyGenerators:
snowflake:
type: SNOWFLAKE
3. Test sharding configuration
Use the MySQL terminal command to connect to the ShardingSphere-Proxy server.
If you deploy databases in Docker containers, you need to add -h native ip. Because accessing 127.0.0.1 in the container is blocked.
#replace {xx} with actual parameter
mysql -h {ip} -u {username} -p{password} -P 3307
#example command
mysql -h 127.0.0.1 -u root -proot -P 3307
ShardingSphere-Proxy supports Navicat MySQL, DataGrip, WorkBench, TablePlus, and other database management connectors.
After confirming the connection is successful, query the databases and make sure they are consistent with those in the configuration file.
mysql> show databases;
+-------------+
| schema_name |
+-------------+
| sharding_db |
+-------------+
1 row in set (0.02 sec)
Execute the new t_user statement, insert 6 pieces of user data (3 pieces for 2021, and 3 pieces for 2022).
mysql> use sharding_db;
mysql> INSERT INTO t_user (id, user_id, create_date) values(1, 1, '2021-01-01 00:00:00'), (2, 2, '2021-01-01 00:00:00'), (3, 3, '2021-01-01 00:00:00'), (4, 4, '2022-01-01 00:00:00'), (5, 5, '2022-02-01 00:00:00'), (6, 6, '2022-03-01 00:00:00');
Query OK, 6 rows affected (0.16 sec)
mysql> select * from t_user;
+----+---------+---------------------+
| id | user_id | create_date |
+----+---------+---------------------+
| 2 | 2 | 2021-01-01 00:00:00 |
| 4 | 4 | 2022-01-01 00:00:00 |
| 6 | 6 | 2022-03-01 00:00:00 |
| 1 | 1 | 2021-01-01 00:00:00 |
| 3 | 3 | 2021-01-01 00:00:00 |
| 5 | 5 | 2022-02-01 00:00:00 |
+----+---------+---------------------+
At this time, the data is in the user_sharding_0 and
user_sharding_1 databases respectively.
Scenario 1: How to locate data information?
Since ShardingSphere-Proxy has logically aggregated the tables, you can query them directly.
mysql> select * from t_user where user_id = 1;
+----+---------+---------------------+
| id | user_id | create_date |
+----+---------+---------------------+
| 1 | 1 | 2021-01-01 00:00:00 |
+----+---------+---------------------+
1 row in set (0.01 sec)
Scenario 2: How to check user growth in 2022 and user information?
mysql> select count(*) from t_user where create_date > '2022-00-00 00:00:00';
+----------+
| count(*) |
+----------+
| 3 |
+----------+
1 row in set (0.10 sec)
mysql> select * from t_user where create_date > '2022-00-00 00:00:00';
+----+---------+---------------------+
| id | user_id | create_date |
+----+---------+---------------------+
| 4 | 4 | 2022-01-01 00:00:00 |
| 6 | 6 | 2022-01-01 00:00:00 |
| 5 | 5 | 2022-01-01 00:00:00 |
+----+---------+---------------------+
3 rows in set (0.02 sec)
Scenario 3: How to get a list of active users who have been registered for over 8 years?
Refer to the above code and you will know how to cope with it.
Conclusion
This post summarizes the basic concepts of ShardingSphere-Proxy based on the actual data sharding production scenarios, and demonstrates how ShardingSphere-Proxy faces these scenarios.
After reading this article, you should be able to:
Understand why ShardingSphere-Proxy is an excellent product to assist developers in DevOps.
Know the differences between ShardingSphere-JDBC and ShardingSphere-Proxy, their advantages and disadvantages, and how they are implemented.
Since you now have a better understanding of ShardingSphere-Proxy, we believe, it will be easier for you to study its source code. To know more about ShardingSphere, please visit Apache ShardingSphere's official website or our community’s previous blogs such as Create a Distributed Database Solution Based on PostgreSQL/openGauss.
Apache ShardingSphere Project Links:
ShardingSphere Github
References
[1]Apache ShardingSphere Download Page:
https://shardingsphere.apache.org/document/current/en/downloads/
[2] mysql-connector-java-5.1.47.jar: https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.47/mysql-connector-java-5.1.47.jar
[3] mysql-connector-java-8.0.11.jar: https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.11/mysql-connector-java-8.0.11.jar
[4] Apache ShardingSphere official website: https://shardingsphere.apache.org/
[5] Build a Distributed Database Solution based on PostgreSQL/openGauss: https://shardingsphere.apache.org/blog/en/material/jan_28_blog_pg_create_a_distributed_database_solution_based_on_postgresql__opengauss/




Top comments (0)