F6 Automobile Technology is an Internet platform company focusing on the informatization of the automotive aftermarket. It helps automotive repair companies (clients) build their smart management systems to digitally transform the auto aftermarket.
The data of different auto repair companies will certainly be isolated from each other, so theoretically the data can be stored in different tables of different databases. However, fast-growing enterprises face increasing data volume challenges: sometimes total data volume in a single table may approach 10 million or even 100 million entries.
This issue definitely challenges business growth. Moreover, growing enterprises are now also planning to split their systems into many microservices based on domains or business types, and accordingly, different databases are vertically required for different business cases.
Why Did We Need Data Sharding?
Relational databases are bottlenecks when it comes to storage capacity, connection count, and processing capabilities.
First, we always prioritize database performance. When the data volume of a single table reaches tens of millions, and there are a relatively large number of query dimensions, system performance would still prove unsatisfactory even if we added more slave databases and optimize indexes. This meant it was time for us to consider data sharding.
The purpose of data sharding is to reduce database load stress and query time. Additionally, since a single database often has a limited number of connections, when Queries Per Second (QPS) indicator of the database is too high, database sharding is certainly needed to share connection stress.
Second, to ensure availability was another important reason. If unfortunately, an accident occurs in a single database, we’d likely lose all data and further affect all services. Database sharding can minimize risk and the negative impact on business services. Generally, when the data volume of a table is greater than 2GB or the number of data rows is greater than 10 million, not to mention that the data is also growing rapidly, we’d better use data sharding.
What’s Data Sharding?
There are four common types of data sharding in the industry:
Vertical table sharding: split big tables into small ones, field-based, which means less frequently used or relatively long fields are split into extended tables.
Vertical database sharding: business-based database sharding is used to solve performance bottlenecks of a single database.
Horizontal table sharding: distribute tables’ data rows into different tables according to some rules in order to decrease the data volume of single tables and optimize query performance. In terms of the database layer, it still faces bottlenecks.
Horizontal data sharding: based on horizontal table sharding, distribute data into different databases to effectively improve performance, lower stress of stand-alone machine and single databases, and break the shackles of I/O, connections, and hardware resources.
Excellent Data Sharding Solutions
Pros:
- Supported by an active open source community. Now, Apache ShardingSphere 5.0 version has been released and the development iteration speed is fast.
- Proven efficacy by many successful enterprise application cases: big companies such as JD Technology and Dangdang.com have applied ShardingSphere.
- Easy deployment: Sharding-JDBC can be quickly integrated into any project without extra services deployed.
- Excellent compatibility: it can route to a single data node and perfectly support SQL.
- Excellent performance and low loss: test results can be found on the Apache ShardingSphere website.
Cons:
Potential increase in operations and maintenance costs, and troublesome field changes and index creation after data sharding. To fix the issue, users need to deploy Sharding-Proxy that supports heterogeneous languages and is more friendly to DBAs.
So far, the project doesn’t support data shards dynamic migration yet. Therefore, feature implementation is required.
2. MyCat
Pros:
- MyCat is a middleware placed between applications and databases to handle data processing and interactions. It cannot be perceived during development, and integrating MyCat does not cost much.
- Use JDBC to connect databases such as Oracle, DB2, SQL Server, and MySQL.
- Support multiple languages plus easy deployment and implementation across different platforms.
- High availability and auto-switch triggered by a crash.
Cons:
- High operations and maintenance costs: to use MyCat, it’s required to configure a series of parameters plus HA load balancer.
- Users have to independently deploy the service, which may increase system risks.
Of course, there are similar solutions such as Cobar, Zebra, MTDDL, and TiDB but honestly, we didn’t spend much time researching other solutions, because we decided to use ShardingSphere as we felt it meets the company’s needs.
F6 Automobile Technology’s Overall Plan
Based on our company’s business model, we chose Client ID as Sharding Key to ensure that work order data of one client is stored in the same single table of the same client-specific database. Therefore, performance loss caused by multi-table correlated queries is avoided; plus later, even if multi-databases sharding is required, cross-database transactions and cross-database JOIN can be avoided.
Among client ID databases, the type BIGINT(20) applies UID (Unique Identification Number, or we call it “gene” ) to ensure potential database scaling in the future; the last two digits of a client ID are its UID, so according to the double scaling rule, the maximum reaches 64 databases. The values of left bits can be used for table sharding, which can be split into 32 sharding tables.
Take 10545055917999668983 as the client ID example and the rules are shown as follows:
105450559179996689 83
Table sharding uid value % 32 database sharding uid value % 1
The last two digits (i.e. 83) are used for database sharding, of which temporary data is only sharded into the library f6xxx, so the remainder is 0. Later, increasing data volume can be expanded to multiple libraries. The remaining value 105450559179996689 is used for table sharding. At first time, it is divided into 32 single tables so the modulo remainders correspond to the specific sharding table subscripts are 0~31.

Given that the business system is growing and we adopt rapid iteration method to develop features step by step, we plan to shard tables first and then do database sharding.
Data sharding has a great impact on the system, so we need greyscale release— if unfortunately, an issue occurs, the system can quickly start roll-back, to ensure a functioning business system. The implementation details are given below:
Table Sharding
- Switch from JDBC to Sharding-JDBC to connect data sources
- Decouple the write databases, and then migrate codes
- Synchronize historical data and incremental data
- Switch sharding tables
Database Sharding
- Migrate the read-only databases
- Data migration
- Switch read-only databases
- Switch write-only databases
Table Sharding Details
Number of Sharding Tables
In the industry, the data of a single table should usually be limited to 5 million rows, and the number of sharding tables should be a power of two to make them scalable. The exact number of sharding tables is calculated based on business development speed and future data increase as well as the future data archiving plan. After sharding table count and sharding algorithms are defined, it’s OK to assess the current data volume in each sharding table.
Preparation
- Replace the database & auto table ID generator
After table sharding, we could no longer use the auto database ID generator anymore, so we had to find a feasible solution. We had two plans:
Plan 1: Use other keys such as snowflake
Plan 2: Implement an incremental component (database or Redis) all by ourselves
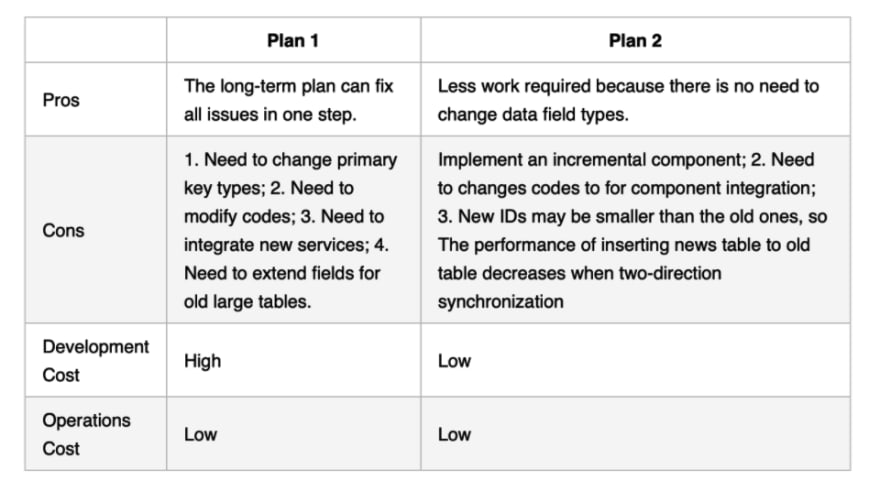
After comparing the two solutions and the business condition, we decided to choose Plan 2 and concurrently, provided a new comprehensive table-level ID generator solution.
- Check whether all requests are carried with shard keys
Now, the microservice traffic entrances include:
- HTTP
- Dubbo
- XXLJOB scheduled job
- Message Queue (MQ)
After table sharding, to quickly locate data shards, all requests must carry their shard keys.
- Decoupling
Decouple business systems of each domain and use interfaces to interact with read and write data.
Remove Direct Table JOIN and use interfaces instead.
The biggest problem brought by the decoupling is the distributed transaction problem: how to ensure data consistency. Usually, developers introduce distributed transaction components to ensure transaction consistency or they use compensation or other mechanisms to ensure final data consistency.
Grayscale Release Plan
In order to ensure quick roll-back when problems caused by new feature releases occur, all online modifications are released step by step based on clients. Our grayscale release plan is shown as follows:
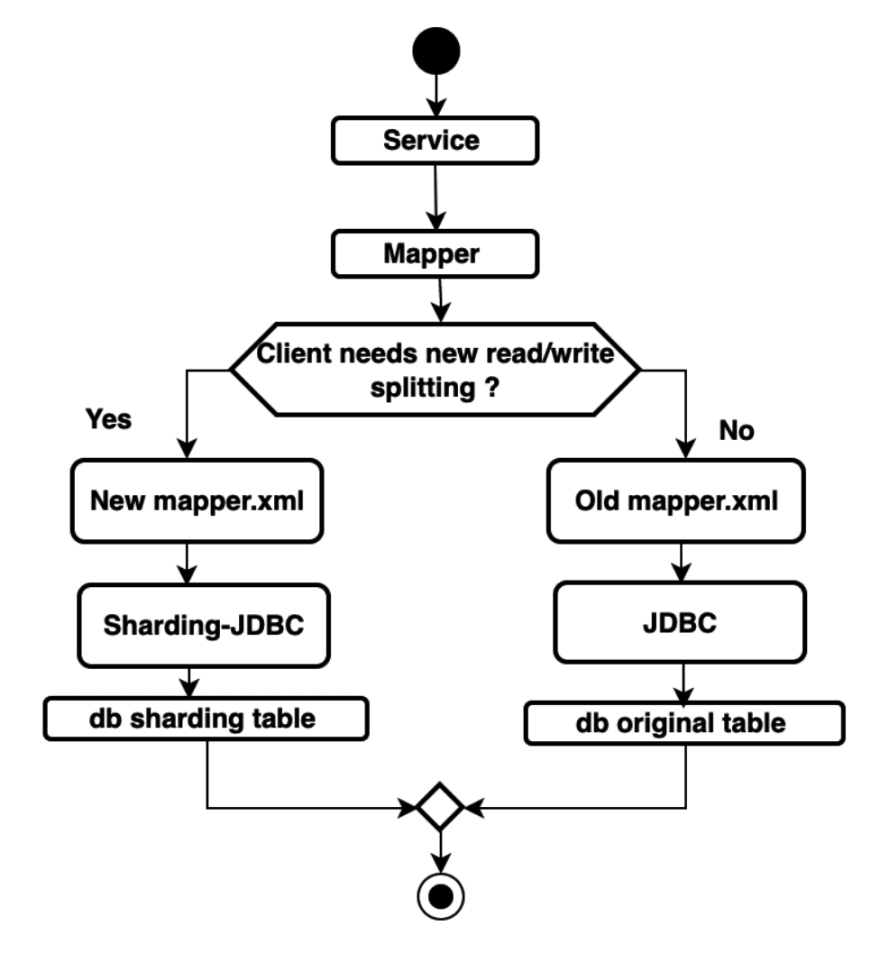
Plan 1: Maintain two sets of Mapper interfaces: one uses Sharding-JDBC data sources to connect to databases while the other uses JDBC data sources to connect to databases. At the service layer, it’s necessary to select one of the two interfaces based on the decision workflow diagram below:
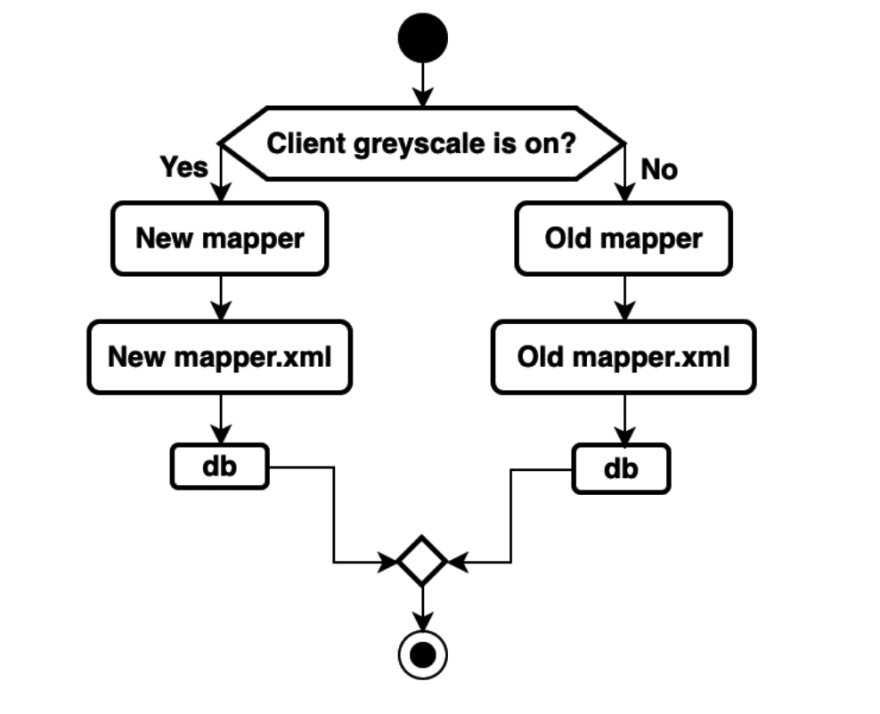
However, the solution causes another problem: all codes visiting the Mapper layer have an if else branch, resulting in major business code changes, potential code intrusion, and harder code maintenance. Therefore, we found another solution and we call it Plan 2.
Plan 2 — Adaptive Mapper Selection Plan: one set of Mapper interface is with two data sources and two sets of implementations. Based on the grayscale configuration, different client requests will go through different Mapper implementations, and one service corresponds to two data sources and two sets of transaction managers, and based on the grayscale configuration, different clients’ requests go to different transaction managers. Accordingly, we leverage multiple Mapper scanners of MyBatis to generate multiple mapperInterfaces, and concurrently generate a mapperInterface for wrapping. The wrapper class supports hintManagerto automatically select mappers; the transaction manager is similar to wrapper class generation. The wrapper class supports hintManager to automatically select various transaction managers to manage transactions. This solution actually avoids intrusion because for codes of the service layer, there is only one Mapper interface.
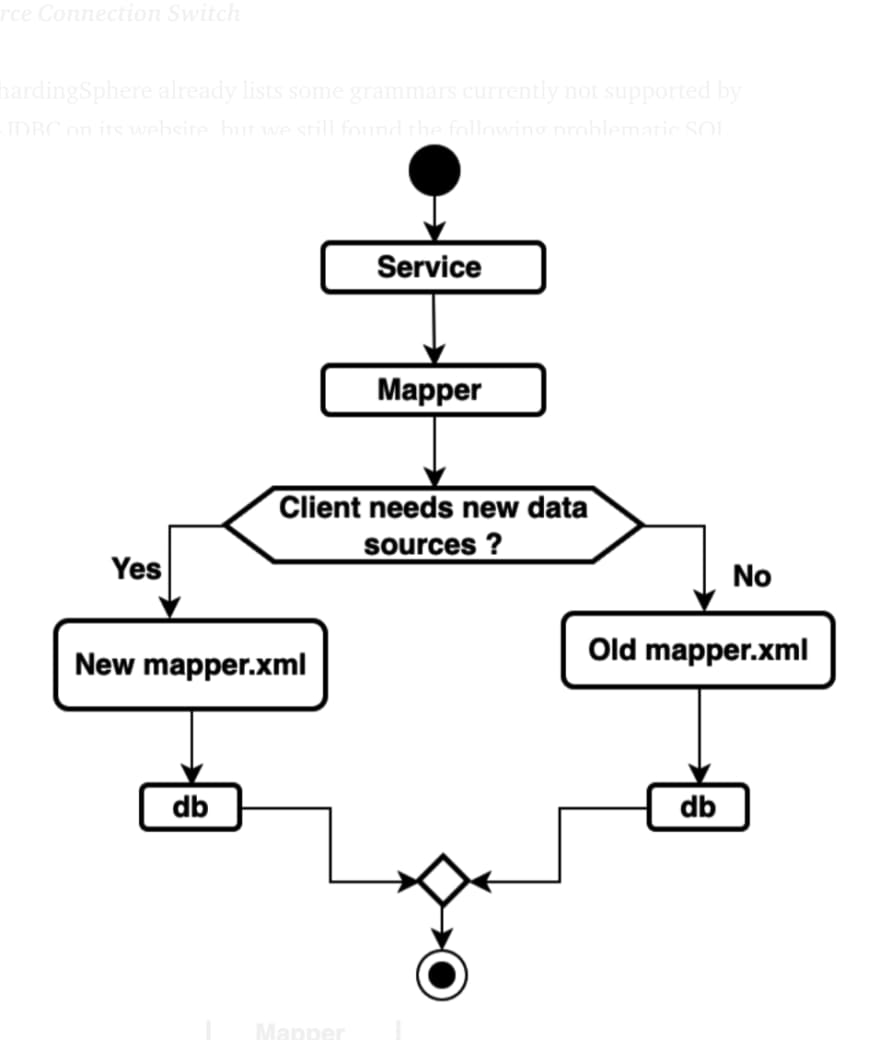
Data Source Connection Switch
Apache ShardingSphere already lists some grammars currently not supported by Sharding-JDBC on its website, but we still found the following problematic SQL statements that Sharding-JDBC parser cannot handle:
- A subquery without a shard key.
- Not support
Insertstatements whose values include cast ifnull now and other functions. - Not support
ON DUPLICATE KEY UPDATE. - By default, select for update goes to the slave database (the issue has fixed since 4.0.0.RC3).
- Sharding-JDBC does not support the statement ResultSet.first () of MySqlMapper with Optimistic Concurrency Control used to query vision.
- No such statement for batch updates.
- Even if
UNION ALLdoes not support the grayscale release plan, we only need to copy a set of mapper.xml, and modify it based on the syntax of Sharding-JDBC before release.
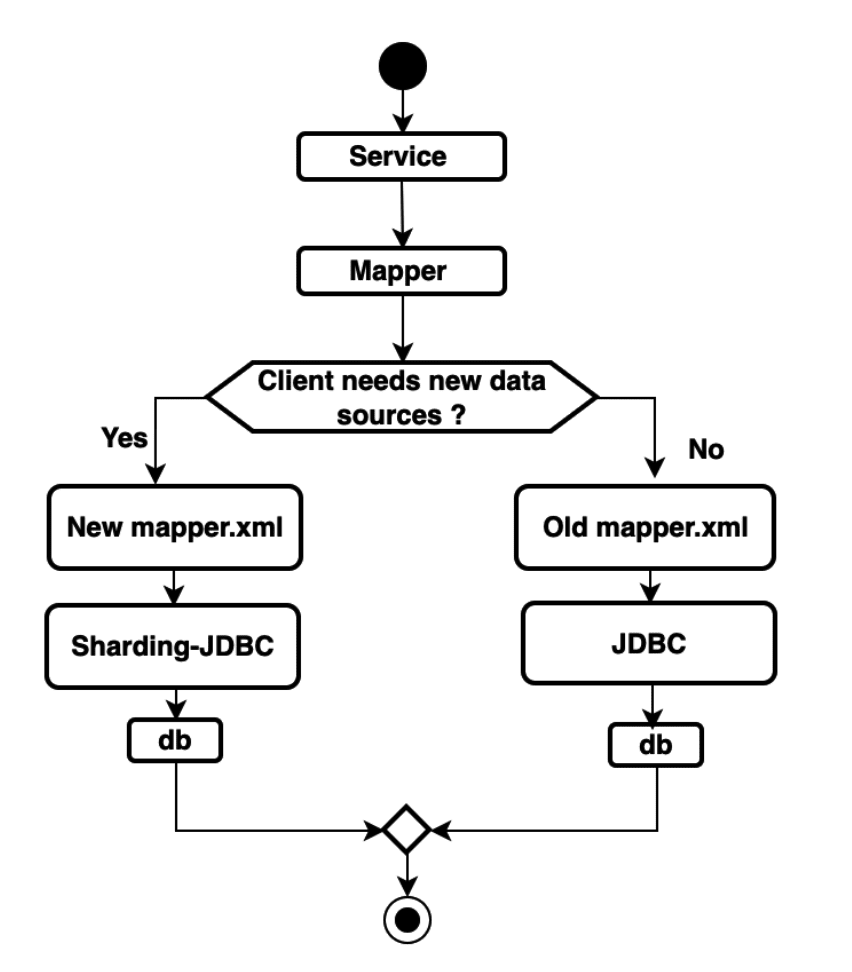
Historical Data Sync
DataX is Alibaba Group’s offline data synchronization tool that can effectively sync heterogeneous data sources such as MySQL, Oracle, SqlServer, Postgre SQL, HDFS, Hive, ADS, HBase, TableStore(OTS), MaxCompute(ODPS) and DRDS.
The data synchronization framework DataX can abstract the synchronization of different data sources as a Reader Plugin that reads data from the data source, and then as a Writer Plugin that writes data to the target. In theory, the DataX framework can support data synchronization of all data source types. Additionally, the DataX plugin ecosystem can allow every newly-added data source to immediately interact with the old data sources.

Verify Data Synchronization
- Use timed tasks to compare the number of data of the original table and of the sharding table.
- Use timed tasks to compare the values of key fields.
Read/write Splitting and Table Sharding
Before read/write splitting, we needed to configure incremental data synchronization first.
-Incremental Data Synchronization
We used another open source distributed database sync project named Otter to synchronize incremental data. Based on database incremental log parsing, otter can synchronize data of MySQL/Oracle databases of the local computer room or the remote computer room. To use Otter, we needed to pay extra attention to the following tips:
- For MySQL databases, users must have binlog enabled, and set its mode as ROW.
- The user must have the query permission of binlog so they need to apply for that as an otter user.
- Now, the binlog of DMS database is stored for only 3 days. In Otter, users can define the starting position of binlog synchronization and the starting point of incremental synchronization by themselves: first, select slave-testDb on the SQL platform, and use the SQL statement “show master status” to query.
Note: the execution results of show master statusof master and slave may be different, so if you set it, you need to get the execution result of the master database. We think this function is really useful because when Otter’s data synchronization fails, we can reset points and synchronize again from the beginning.
- When Otter is disabled, it will automatically record the last point of synchronization, and continue to synchronize data from this point next time.
- Otter allows developers to define their own processing process. For example, we can configure data routing rules and control the direction of client data synchronization data from subtable to parent table or vice versa.
Disabling Otter will not invalidate the cache defined in the user-defined Otter processing process. To fix it, the solution is to modify the code comment and save it.
Read/write Splitting Plan
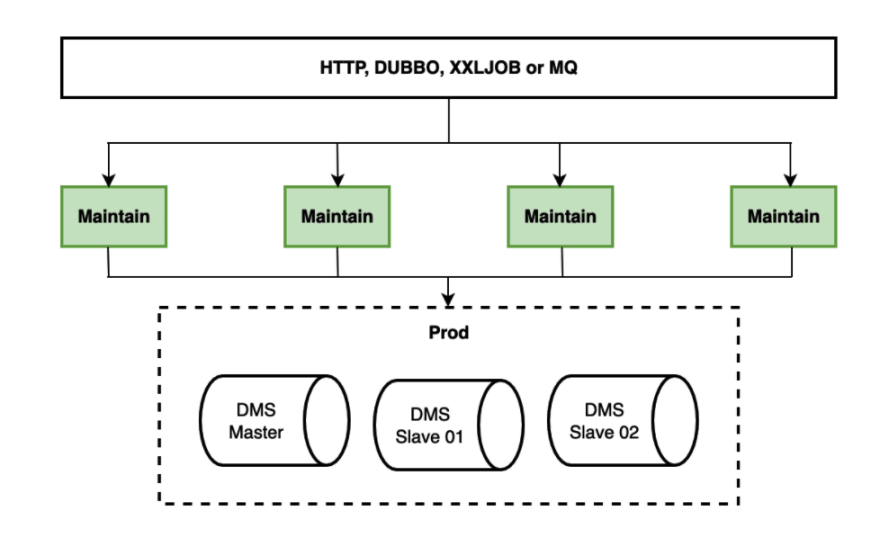
Our greyscale switch plan is shown below:
We chose the grayscale release solution, which means it was necessary to ensure real-time data updates in both subtables and parent tables. Therefore, all data was synchronized in two directions: for clients with grayscale release being on, reads and writes went to subtables and the data was synchronized to parent tables in real time via Otter, while for clients with grayscale release being off, reads and writes went to parent tables and the data is synchronized to subtables in real time via Otter.

Database Sharding Details
Preparations
- Primary Key
Primary key should be auto increment type (sharding tables should be global auto increment) or access the only primary key numbering service (server_id independent of DB). Table auto increment primary key generation or uuid_short generated key require switching.
- Storage Procedure, Functions, Trigger and EVENT
Try to remove them first if present; if they cannot be removed, create them in advance in new databases.
- Data Synchronization
Data synchronization uses DTS or sqldump (historical data) + otter (incremental data) for synchronization.
- Database Change Procedure
To avoid potential performance and compatibility problems, database change plan must follow two criterion:
- Greyscale switching: traffic is gradually switching to RDS (Alibaba Cloud Relational Database Service, a.k.a. RDS), allowing obervance of database performance at any time.
- Quick Rollback: achieving quick reversion when problems occur with little impact on user experience.
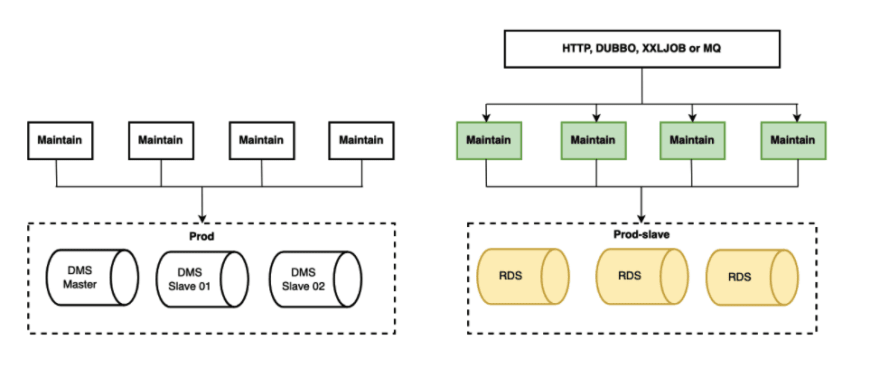
Status Quo: four application instances +one master db and two slave db
Step 1: add a new application instance and switch it to RDS, write into or pass dms master database, and the data in dms master database will be synced to rds in real time

Step 2:add three more application instances, and cut 50% of the data to write into rds database

Step 3: remove the four original instance traffic, and read them into rds instances while writing still goes into dms master database

Step 4: switch the master database into rds, and rds data will be reversely synced to dms master database to make it easier for the quick rollback of the data
Step 5: Completion
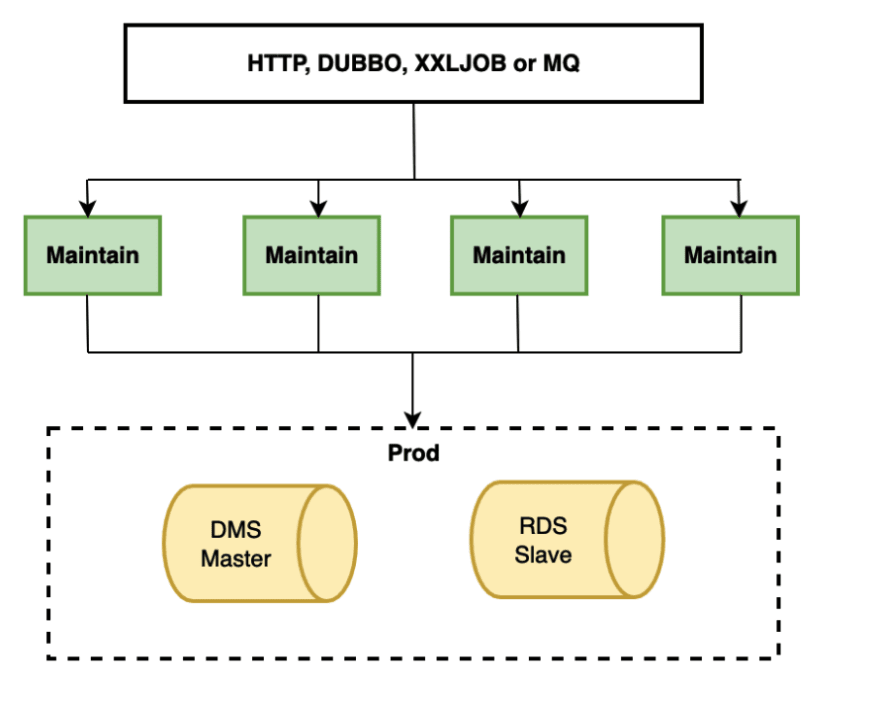
Each step mentioned above can be quickly rolled back through traffic switching so as to ensure the availability and stability of system.
Sharding & Scaling
When the performance of a single database reaches a plateau, we can scale out the database by modifying sharding database routing algorithms and migrating data.
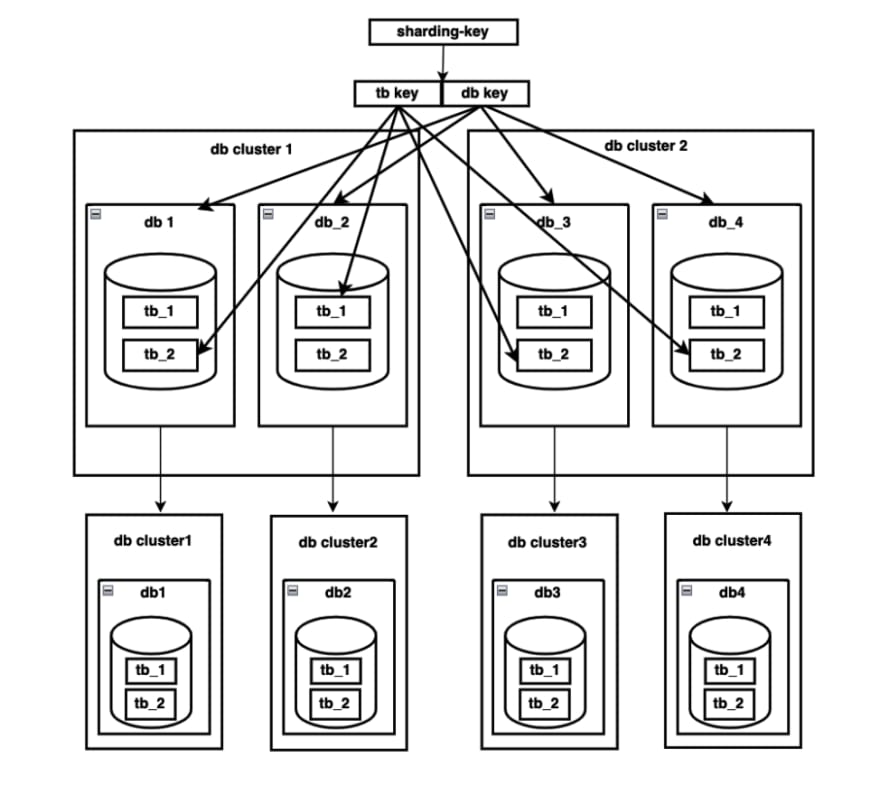
When the capacity of a single table reaches its maximum size, we can scale out the table by modifying sharding table routing algorithms and migrating data.

FAQ
Q: Sometimes, Otter receives binlog data but the data cannot be found in the database?
A:To make our MySQL compatible with replicas of other non-transactional engines, we added binlog at the server layer. Binlog can record all engine modification operations, so it can support replication function for all engines. The problem is a potential inconsistency between redo log and binlog but MySQL uses its internal XA mechanism to fix the issue.
Step 1:Not perform operations on InnoDB prepare, write/sync redo log and binlog.
Step 2: First, write/sync Binlog and then InnoDB commit (commit in memory).
Of course, group commit has been added since version 5.6. The development improves I/O performance to some degree, but it doesn’t change the execution order.
After write/sync Binlog is done, the binlog has been written, so MySQL considers that the transaction has been committed and persisted (now, the binlog is ready to be sent to subscribers). Even if a database crashes, the transaction can still be recovered correctly after MySQL reboot. However, before this step, any operation failure may cause transaction rollback.
InnoDB commit is centered on memory commit such as killing locks, read views related to multiversion concurrency control release. MySQL believes that no errors occur in this step — once an error really occurs, the database will crash — MySQL itself cannot handle the crash. This step does not have any logic that causes transaction rollback. In terms of program operations, only after this step is completed, the changes caused by the transaction can be shown through the API or queries at the client-side.
The reason why the problem may occur is that the binlog is sent first, and then db commit is done. We use query retries to fix this issue.
Q: When it comes to multi-table queries, sometimes, why some tables cannot get data?
A:The master/slave routing strategy of Sharding-JDBC is shown below:
Master databases are chosen in the following scenarios:
- SQL statements that include lock such as select for update ( of Version 4.0.0.RC3);
- Not SELECT statements;
- Threads that have already gone to master databases;
- Codes specify the requests for master databases.
Algorithms used to choose from multiple slave databases:
- Polling Strategy
- Load Balancer Strategy
The default is the polling strategy. However, one query may go to different slave databases, or it may go to the master library and slave databases, which occurs when there is time inconsistency between master-slave database latency or multi-slave latency.
Q: How can we remove network traffic?
A:
- http: use nginx to remove upstream;
- dubbo: leverage its qos module to execute offline/online command;
- xxljob: manually enter execution IP of the executor to specify instances;
- MQ: use the API provided by Alibaba Cloud to enable or disable consumer bean.
Apache ShardingSphere Open Source Project Links:
ShardingSphere Github
ShardingSphere Twitter
ShardingSphere Slack Channel




Top comments (0)