
Following the release of Apache ShardingSphere 5.1.1, our community integrated 1,028 PRs from contributors all over the world to bring you the latest 5.1.2 version. The new version includes a lot of improvements in terms of functions, performance, tests, documentation, examples, etc.
Standout new features include:
- ShardingSphere-Proxy Helm Chart.
- SQL dialect translation.
- Using ShardingSphere-JDBC as a Driver.
These new capabilities boosted ShardingSphere’s data gateway capability, enabling ShardingSphere to be deployed on the cloud while optimizing user experience.
In addition to the above-mentioned new features, this update also improves SQL parsing support, kernel, runtime mode, and elastic scaling support for PostgreSQL / openGauss schema, auto-scaling, transactions, and DistSQL in terms of user experience.
This post will give you an overview of the ShardingSphere 5.1.2 updates.
New Features
ShardingSphere-Proxy configuration using Helm
ShardingSphere-Proxy provides Docker images for deployment in containers. However, for those who need to deploy ShardingSphere-Proxy on Kubernetes, you have to go through some procedures such as database driver mounting, configuration mounting, custom algorithm mounting, etc., which make the deployment process relatively tedious and causes high operation & maintenance costs.
This update brings the new ShardingSphere-Proxy Helm Chart, a new feature donated to the Apache ShardingSphere community by SphereEx, a provider of enterprise-grade, cloud-native data-enhanced computing products, and solutions. This development allows Apache ShardingSphere to embrace ahead cloud-native computing.
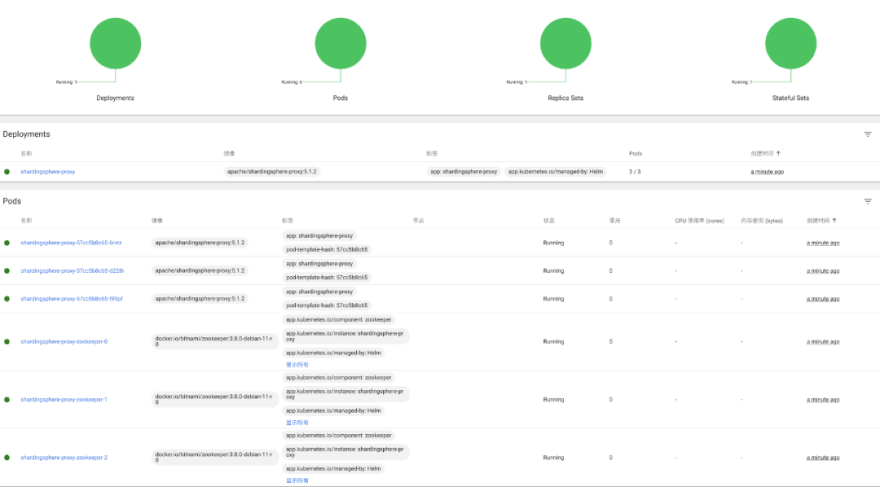
ShardingSphere relies on a registry to store metadata in cluster mode, and ShardingSphere-Proxy’s Helm Chart can automatically deploy ZooKeeper clusters allowing you to quickly build ShardingSphere-Proxy clusters.
Due to the limits imposed by open source protocol, ShardingSphere-Proxy’s binary distribution package and Docker image are not packaged with MySQL JDBC driver, so users need to manually add the MySQL JDBC driver to the classpath to use MySQL as ShardingSphere’s storage node.
For such cases, ShardingSphere-Proxy Helm Chart can automatically obtain the MySQL JDBC driver in the Pod’s Init container, reducing your deployment operation costs.
SQL dialect translation
With increased database diversification, the coexistence of multiple types of databases is now the norm. The scenarios in which heterogeneous databases are accessed using one SQL dialect are becoming a trend.
The existence of multiple diversified databases makes it difficult to standardize SQL dialects for accessing databases, meaning that engineers need to use different dialects for different types of databases - lacking a unified query platform.
Automatically translating different types of database dialects into one dialect that can be used by back-end databases allows engineers to access all back-end heterogeneous databases using any one database dialect, significantly reducing development and maintenance costs.
Apache ShardingSphere 5.1.2 is an important step to building a highly productive data gateway. This update enables a new SQL dialect translation capability that supports dialect conversion between major open source databases.
For example, you can use a MySQL client to connect to ShardingSphere-Proxy and send SQL based on MySQL dialect, and ShardingSphere can automatically recognize the user protocol and storage node type to complete SQL dialect translation, accessing heterogeneous storage nodes such as PostgreSQL and vice versa.

Using ShardingSphere-JDBC as Driver
In past versions, ShardingSphere-JDBC was available for users in the form of Datasource. Projects or tools that do not use Datasource, previously would need to first be modified in order to be able to introduce ShardingSphere-JDBC, which increases development costs.
In Apache ShardingSphere 5.1.2, ShardingSphere-JDBC implements the standardized JDBC Driver interface, which allows you to introduce ShardingSphere-JDBC as a Driver.
Users can obtain Connection directly through DriverManager:
Class.forName("org.apache.shardingsphere.driver.ShardingSphereDriver");
Connection conn = DriverManager.getConnection("jdbc:shardingsphere:classpath:config.yaml");
Or use Datasource to obtain Connection:
// Take HikariCP as an example
HikariDataSource dataSource = new HikariDataSource();
dataSource.setDriverClassName("org.apache.shardingsphere.driver.ShardingSphereDriver");
dataSource.setJdbcUrl("jdbc:shardingsphere:classpath:config.yaml");
Connection conn = dataSource.getConnection();
Optimizations of the existing capabilities
Kernel
In this update, ShardingSphere merged lots of PRs to improve SQL parsing support. SQL parsing optimizations take up a large proportion of the update log.
ShardingSphere provided preliminary support for PostgreSQL / openGauss schema in 5.1.1.
In this 5.1.2 update, the kernel, cluster mode, and auto-scaling support for PostgreSQL / openGauss schema has been improved. For example, support for schema structure has been added to metadata pairs, and schema customization is also supported in kernel and auto-scaling.
ShardingSphere-Proxy
As the market for servers using ARM CPUs becomes more popular, ShardingSphere-Proxy also provides images for arm64 architecture on Docker as well.
When it comes to MySQL, ShardingSphere-Proxy fixed the issue where packets longer than 8 MB could not be received, and further supports receiving data larger than 16 MB in total.
Auto-scaling
In addition to supporting PostgreSQL schema customization, auto-scaling also implements automatic table creation when migrating PostgreSQL, and fixes the problem where PostgreSQL incremental migration would report errors when encountering null fields values. In addition to these features, auto-scaling also reduces resource consumption during migration and provides support for incremental migration in openGauss 3.0.
Release notes
The full release note for ShardingSphere 5.1.2 can be found in the following sections. Note that this update adjusts a small number of APIs, so please refer to the API Adjustments section for more details.
New Features
Kernel: alpha version of SQL dialect conversion for MySQL and PostgreSQL.
Kernel: Support for PostgreSQL and openGauss custom schema.
Kernel: Support for PostgreSQL and openGauss create/alter/drop view statements.
Kernel: support for openGauss cursor statements.
Kernel: support for using system libraries customization.
Kernel: support acquisition of openGauss and MySQL create table statements.
Kernel: support acquisition of PostgreSQL create table statements.
Access terminal: officially support rapid deployment of a ShardingSphere-Proxy cluster that includes a ZooKeeper cluster in Kubernetes using Helm.
Access terminal: support for ShardingSphere JDBC Driver.
Auto Scaling: support for PostgreSQL automatic table building.
Auto Scaling: support for PostgreSQL and openGauss custom schema table migration.
Auto Scaling: support migration of string primary key table.
Operation mode: Governance Center supports PG/openGauss three-level structure.
Operation mode: Governance Center supports Database level distributed locking.
Optimization
Kernel: support for PostgreSQL and openGauss copy statements.
Kernel: support for PostgreSQL alter/ drop index statements.
Kernel: support for MySQL update force index statements.
Kernel: support for openGauss create/alter/drop schema statements.
Kernel: optimize RoundRobinReplicaLoadBalanceAlgorithm and RoundRobinTrafficLoadBalanceAlgorithm algorithm logic.
Kernel: optimize metadata loading logic when front-end driver database type and back-end do not match.
Kernel: refactor metadata loading logic.
Kernel: optimization of show processlist statement function.
Kernel: improved loading performance in scenarios involving a large number of tables.
Kernel: support for comment statement execution
Kernel: support for view statement execution in PostgreSQL and openGauss sharding scenarios.
Kernel: support for Oracle CREATE ROLLBACK SEGMENT statement.
Kernel: support for parsing openGauss DROP TYPE
Kernel: support for parsing openGauss ALTER TYPE
Kernel: support for parsing Oracle DROP DISKGROUP
Kernel: support for parsing Oracle CREATE DISKGROUP
Kernel: support for parsing Oracle DROP FLASHBACK ARCHIVE
Kernel: support parsing openGauss CHECKPOINT
Kernel: support parsing Oracle CREATE FLASHBACK ARCHIVE
Kernel: support parsing PostgreSQL Close
Kernel: support parsing openGauss DROP CAST
Kernel: support parsing openGauss CREATE CAST
Kernel: support parsing Oracle CREATE CONTROL FILE
Kernel: support parsing openGauss DROP DIRECTORY
Kernel: support parsing openGauss ALTER DIRECTORY
Kernel: support parsing openGauss CREATE DIRECTORY
Kernel: support parsing PostgreSQL Checkpoint
Kernel: support parsing openGauss DROP SYNONYM
Kernel: support parsing openGauss CREATE SYNONYM
Kernel: support parsing openGauss ALTER SYNONYM
Kernel: support parsing PostgreSQL CALL statement
Kernel: support parsing Oracle CREATE PFILE
Kernel: support parsing Oracle CREATE SPFILE
Kernel: support parsing Oracle ALTER SEQUENCE
Kernel: support parsing Oracle CREATE CONTEXT
Kernel: support for parsing Oracle ALTER PACKAGE
Kernel: support for parsing Oracle CREATE SEQUENCE
Kernel: support for parsing Oracle ALTER ATTRIBUTE DIMENSION
Kernel: support for parsing Oracle ALTER ANALYTIC VIEW
Kernel: loading SQLVisitorFacade with ShardingSphere Spi
Kernel: loading DatabaseTypedSQLParserFacade with ShardingSphere Spi
Kernel: support parsing Oracle ALTER OUTLINE
Kernel: support parsing Oracle DROP OUTLINE
Kernel: support parsing Oracle drop edition
Kernel: support parsing SQLServer WITH Common Table Expression
Kernel: optimize SubquerySegment’s start and end indexes in with statements
Kernel: reconstructing JoinTableSegment
Kernel: support parsing Oracle DROP SYNONYM
Kernel: support parsing Oracle CREATE DIRECTORY
Kernel: support parsing Oracle CREATE SYNONYM
Kernel: support parsing SQLServer XmlNamespaces clause
Kernel: support parsing Oracle Alter Database Dictionary
Kernel: support parsing SQLServer clause of SELECT statement
Kernel: support parsing Oracle ALTER DATABASE LINK
Kernel: support for parsing Oracle CREATE EDITION
Kernel: support parsing Oracle ALTER TRIGGER
Kernel: support parsing SQLServer REVERT statement
Kernel: support parsing PostgreSQL DROP TEXT SEARCH
Kernel: support parsing PostgreSQL drop server
Kernel: support parsing Oracle ALTER VIEW
Kernel: support parsing PostgreSQL drop access method
Kernel: support parsing PostgreSQL DROP ROUTINE
Kernel: support parsing SQLServer DROP USER
Kernel: support parsing Oracle DROP TRIGGER
Kernel: support parsing PostgreSQL drop subscription
Kernel: support parsing PostgreSQL drop operator class
Kernel: support parsing PostgreSQL DROP PUBLICATION
Kernel: support parsing Oracle DROP VIEW
Kernel: support parsing PostgreSQL DROP TRIGGER
Kernel: support parsing Oracle DROP DIRECTORY
Kernel: support parsing PostgreSQL DROP STATISTICS
Kernel: support parsing PostgreSQL drop type
Kernel: support parsing PostgreSQL DROP RULE
Kernel: support parsing SQLServer ALTER LOGIN
Kernel: support parsing PostgreSQL DROP FOREIGN DATA WRAPPER
Kernel: support parsing PostgreSQL DROP EVENT TRIGGER statement.
Access Terminal: ShardingSphere-Proxy MySQL supports receiving request packets over 16 MB in size.
Access Terminal: ShardingSphere-Proxy adds SO_BACKLOG configuration item.
Access Terminal: ShardingSphere-Proxy SO_REUSEADDR is enabled by default.
Access Terminal: ShardingSphere-Proxy Docker image with aarch64 support.
Access Terminal: ShardingSphere-Proxy MySQL support default MySQL version number.
Access Terminal: ShardingSphere-Proxy PostgreSQL /openGauss supports more character sets.
Access Terminal: ShardingSphere-Proxy adds default port configuration items.
Auto Scaling: scaling is compatible with the HA port for data synchronization when thread_pool is enabled in openGauss 3.0.
Auto Scaling: optimize the logic of Zookeeper event handling in PipelineJobExecutor to avoid zk blocking events.
Auto Scaling: scaling data synchronization is case-insensitive for table names.
Auto Scaling: improved PostgreSQL/openGauss replication slot cleanup.
Auto Scaling: improved lock protection in preparation phase
Auto Scaling: improve data synchronization in PostgreSQL rebuild scenarios after the same record is deleted.
Auto Scaling: data sources created by scaling are not cached at the bottom.
Resilient Scaling: reuse data sources as much as possible to reduce database connection occupancy.
DistSQL: REFRESH TABLE METADATA supports specified PostgreSQL’s schema.
DistSQL: add check for binding tables under ALTER SHARDING TABLE RULE
Operational mode: ShardingSphere-JDBC support for configuring database connection names.
Distributed transactions: prohibit DistSQL execution in transactions.
Distributed transaction: autocommit = 0, DML will automatically open transaction in DDL part.
Bug fixes
Kernel: fix PostgreSQL and openGauss show statement parsing exceptions.
Kernel: fix PostgreSQL and openGauss time extract function parsing exceptions.
Kernel: fix PostgreSQL and openGauss select mod function parsing exceptions.
Kernel: fix the execution exception of multiple schema join statements in read/write separation scenario.
Kernel: fix exception in execution executing create schema statement in encryption scenario.
Kernel: fix drop schema if exist statement exception.
Kernel: fix routing error with LAST_INSERT_ID()
Kernel: fix use database execution exception in no data source state.
Kernel: fix function creation statement with set var.
Access: fix null pointer caused by field case mismatch in ShardingSphere-Proxy PostgreSQL /openGauss Describe PreparedStatement
Access: fix ShardingSphere-Proxy PostgreSQL /openGauss not returning to correct tag after schema DDL execution.
Auto Scaling: fix MySQL unsigned type error in the scaling process.
Auto Scaling: fix a connection leak problem when the consistency check fails to create a data source.
Auto Scaling: fixes an issue where ShardingSphereDataSource initialization process ignores rules other than sharding.
Auto-scaling: support for jobs being closed in the preparation phase.
Auto-scaling: fixes data source url and jdbcurl compatibility issues.
Auto-scaling: fixes creation timing issues of openGauss data replication to avoid possible incremental data loss.
Auto-scaling: improve job state persistence to ensure that special cases are not overwritten with the old state.
Auto-scaling: fix PostgreSQL’s inability to correctly resolve null when using TestDecoder for incremental migration.
DistSQL: fix SET VARIABLE changes not taking effect in standalone and in-memory modes.
DistSQL: fix the problem where SHOW INSTANCE LIST is not consistent with actual data.
DistSQL: fix the case-sensitive problem in sharding rules.
Run mode: fix the problem of metadata missing in the new version after the scaling feature changes the table splitting rules.
Distributed transaction: fix the problem that indexinfo obtained according to catalog is empty.
Refactoring
Auto-scaling: refactoring jobConfig to facilitate reuse and extension of new types of jobs.
Run mode: optimize the storage structure of compute nodes in the registry center.
Run mode: use uuid to substitute ip@port as a unique instance identifier.
API Adjustments
DistSQL: EXPORT SCHEMA CONFIG is adjusted to EXPORT DATABASE CONFIG
DistSQL: IMPORT SCHEMA CONFIG is adjusted to IMPORT DATABASE CONFIG
Run mode: Adjust db-discovery algorithm configuration.
DistSQL: SHOW SCHEMA RESOURCES is adjusted to SHOW DATABASE RESOURCES
DistSQL: COUNT SCHEMA RULES is adjusted to COUNT DATABASE RULES
Permissions: permission provider ALL_PRIVILEGES_PERMITTED updated to ALL_PERMITTED
Permissions: Permissions provider SCHEMA_PRIVILEGES_PERMITTED updated to DATABASE_PERMITTED
Community shoutout
Thanks to the efforts made by the 54 ShardingSphere contributors, who submitted a total of 1028 PRs, to make the ShardingSphere 5.1.2 release possible.

Relevant links:
ShardingSphere Github
Author
Weijie Wu
SphereEx Infrastructure R&D Engineer, Apache ShardingSphere PMC
Weijie focuses on the R&D of Apache ShardingSphere’s Access Terminal and ShardingSphere’s subproject ElasticJob.





Top comments (0)