An often overlooked bedrock of Site Reliability Engineering (SRE)
When your production systems are hit with a critical issue, you can trust your DevOps team, your Sysadmins or your SREs to get the system back on track. This is a no brainer.
And in turn, these folks need to be able to trust the rest of the team to let them do their jobs, be it engineering, customer support or product management. But where does this trust come from? It comes from understanding - the more you understand, the more you can trust. But when there is obscurity, it severely impedes understanding.
This is why transparency matters.
In most organizations, the pursuit of reliability is often blended with obscurity. There is strict access control and sometimes this means relevant people not having access to even basic observability metrics. This leads to increased stress when systems go down, with people pointing fingers & assigning blame to things they may not fully understand.
As a general rule of thumb, higher transparency not only results in a better incident management and response process but more importantly also increases trust between team members and gives them a way to calmly figure out what went wrong before fixing it for good.
In this article, we are going to outline how you can cultivate transparency in your team and benefit from it.
Evolution of transparency in Tech teams
Transparency, although not a traditional goal of tech teams while handling incidents has evolved over the years to become an auxiliary objective. The most recent developments in terms of enabling transparency are widespread adoption of incident management and alert notification tools that help you plan, track, and work faster and more efficiently in an ever-changing environment. By offering increased visibility into tasks and who owns these tasks, these tools facilitate better collaboration. But on the other hand, if transparency is regarded as one of the primary objectives of teams doing incident response, the productivity gains increase manifold.
Transparency as a primary objective
In order to make transparency as a primary objective, it is important to think about what would be the milestones in your journey. You can choose these milestones based on the four progressive levels of transparency we've seen many tech teams use as a reference. These levels are:
Level 1 - Engineering Transparency
The first level of transparency is purely internal to the engineering team. Once you have selected the metrics that are the most crucial and their target range of values i.e. your Service Level Indicators (SLIs) and Service Level Objectives (SLOs) - you can then share these across the entire engineering team (instead of restricting only to specific folks) through (i) status pages private to your team, (ii) centralized incident timelines that are accessible to every developer, and (iii) opening up the incident response documentation like post-mortems, runbooks and other best practices. This level of transparency is gated and serves to help the engineering team collaborate better.Level 2 - Organizational Transparency
Taking it a notch higher, you can expose this same information to the entire organization including product, support and business teams. You can start to do this by first setting your SLOs in collaboration with customer facing teams. The outcome at this level of transparency is increased trust in the engineering team and better communication with external stakeholders like customers, partners, resellers, etc.Level 3 - Stakeholder Transparency
The third level of transparency is where you expose your incident management practices and your SLOs to all external stakeholders such as your customers, partners, resellers, vendors or anybody else that you're working with. This can be achieved with a public SLO dashboard, public status pages, and open post-mortems. The benefits at this level of transparency is higher customer loyalty, and improved brand perception.Level 4 - Universal Transparency
The final level of transparency is the holy grail where you really bare all. It's where you are public about your metrics not only to existing stakeholders but also future potential stakeholders. This is the level at which many teams tend to live stream their response to outages. Businesses at this level can be very confident about their metrics constantly improving because they are being fully transparent about them.
For various metrics and events, you can choose the level of transparency you want to go with for those specific metrics/events.
Often we need to iterate on our SLOs before we settle on what works best for particular situations. So, it's crucial that this information is made transparent at least within the engineering team, making it easier to reflect and understand if these SLOs are indeed the right ones. When you are transparent about your SLOs, you also have a better understanding of the dependencies between these SLOs. This further allows you to have better policies around your error budgets, and have a good understanding of how these SLOs interact with each other.
That being said, just because you're transparent about your SLOs doesn't mean that everyone gets to have a say in what your SLOs should be. It just means that you're communicating what is important to people across the organization. Also, there is certainly an assumption that things get more complicated if you have to be transparent about SLOs. But that's far from the truth because if you want to be transparent, the idea is to make your SLOs really simple so that even non-engineering teams can understand them. Another myth about being transparent is that it slows down processes because everybody needs to understand the SLOs. On the contrary, processes are much more streamlined and actually more effective because being transparent removes any blind spots in terms of the metrics that you're tracking.
Effective Incident response is a team effort with the right tool
Once important metrics have been identified and their target levels are defined, it is imperative that the collection of these metrics is carefully handled. Different metrics may be monitored with the help of tools like Prometheus and Datadog to collect and visualize the data. When a metric goes outside its target range of values, these tools generate an alert. Any organization with well defined SLOs will feel the need for multiple monitoring tools to track the underlying metrics or SLIs. A proper incident management tool centralizes all these alerts from the different monitoring tools and does a lot more than just alerting. It allows your team to have a robust incident response plan in place, and helps teams perform retrospectives so that repeated incidents can be resolved faster. A well-designed, dynamic incident management tool can potentially save the day, with the ability to automate a number of different incident response activities.
Each incident will have unique requirements like the data to be verified, recorded and tracked, the runbooks and processes to be followed, the stakeholders to be notified, and the reports to be filed etc.
A holistic incident response tool can address all of these. While this level of flexibility allows for individualized workflows based on the type of incident, a well-designed technology solution for incident management can also aid in providing greater transparency for all incident types.
SLOs can be much more effective if the cycle that starts with creating the objectives, ends with evaluating them based on the SLO breaches that have happened. Reevaluation of service level objectives is a must to take corrective action either by refining the indicators and their target ranges or by making the services more robust. It is crucial to design service level objectives while keeping in mind that services will fail because they inevitably will.
Implementation of Transparency
Squadcast is an incident management tool that's purpose-built for SRE. Its innovative design enables true transparency and minimizes friction in the incident response process. With transparency comes the ability to resolve incidents faster, create and iterate on SLOs and calculate error budgets to implement policies around them. This prevents re-occurrences of similar incidents and allows for faster innovation and enhanced customer satisfaction.
Squadcast helps with achieving transparency through the below inbuilt aspects of the platform.
One of the cornerstones of SRE is Transparency and status pages help you communicate the status of your services internally to other teams or externally to your customers at all times.
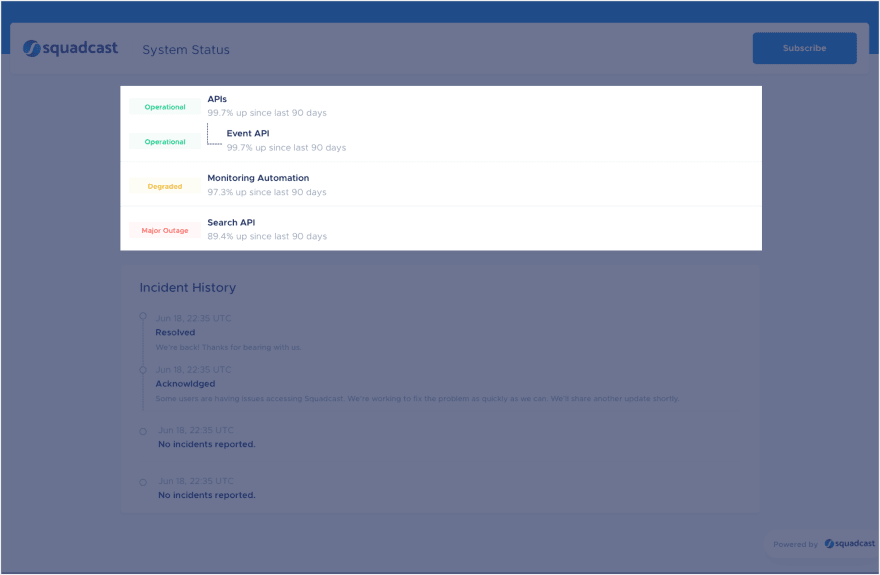
❖ Public Status Page: You can configure your public-facing services and their dependent components and show their status in real-time directly within Squadcast itself. Customers can subscribe to real-time email updates by entering their contact information in the status page.
❖ Private Status Page: You can expose the status of your internal services privately to other internal teams. You can check who is working on an incident if the service is facing issues. You can also page teams responsible for specific services.
- Centralized SLO dashboard and SLI management for services.
See all your configured SLOs on a single dashboard. Analyze breaches instantly with a quick snapshot of SLIs rolled up for all your services. Squadcast allows you to track Service Level Indicators (SLIs) like uptime, latency, throughput volume, availability, etc.. Set custom thresholds to get notified when breached. The SLO dashboard is accessible to all users of Squadcast.

- Collaboration with transparency
Communicate and collaborate to resolve incidents quickly irrespective of your location with the help of
❖ Virtual War Rooms: Incident-specific war rooms within the Squadcast platform enable real-time collaboration between all responders.

❖ Incident Timeline: All incident response activities are recorded in real time in chronological order. The incident timeline can be downloaded in CSV and PDF formats and can be shared with the rest of your team.
❖ ChatOps integration: Bidirectional integration with collaboration tools like Slack allows teams to track incident specific conversations on the war room. All responses from a Slack channel will be reflected on the Incident war room and vice versa.
Conclusion:
Doing incident management the SRE way helps you develop operational transparency across your organization. And you can choose different levels of transparency for different metrics and events that you may have. With a single source of truth for metrics, logs, events, traces, incident information and response, your team can be empowered to quickly access the information they need with sufficient context and collaborate to quickly resolve incidents.
With better collaboration and transparency, the overall reliability of your service improves significantly.
This article was originally a talk at SREcon'19 titled "Transparency---How Much Is Too Much". Slides available here.
We love your comments. What do you struggle with as a DevOps/SRE? Do you have ideas on how incident response could be done better in your organization?
We would be thrilled to hear from you! Leave us a comment or reach out over a DM via Twitter and let us know your thoughts.






Top comments (0)