
There was a significant buzz about reactive programming in Java for the last few years. Now it seems that after the wave mass adoption has passed, we could better qualify the area of its applicability and where it shines.
The whole concept of reactive programming isn’t something new. It was a new API that had been introduced to public to make use of the paradigm. Initially created in 2010 as “reactive extensions” in .NET, then ported to Java as RxJava in 2013. In 2015 it became a specification called Reactive Streams (RS). Now RS standard is implemented by a few frameworks like Akka, RxJava and Reactor (Spring).
Kotlin has Flows that is a conceptually similar framework having the same goals for featuring imperative async programming, but it’s not implementing RS directly. Rather it has conversion methods to map Flow entities to the RS API specification.
In a nutshell, a reactive system looks much like good old message-driven architecture. Publishers produce values and Subscribers are notified of next available data.
A reactive system has some additions to the well-known message-driven patterns:
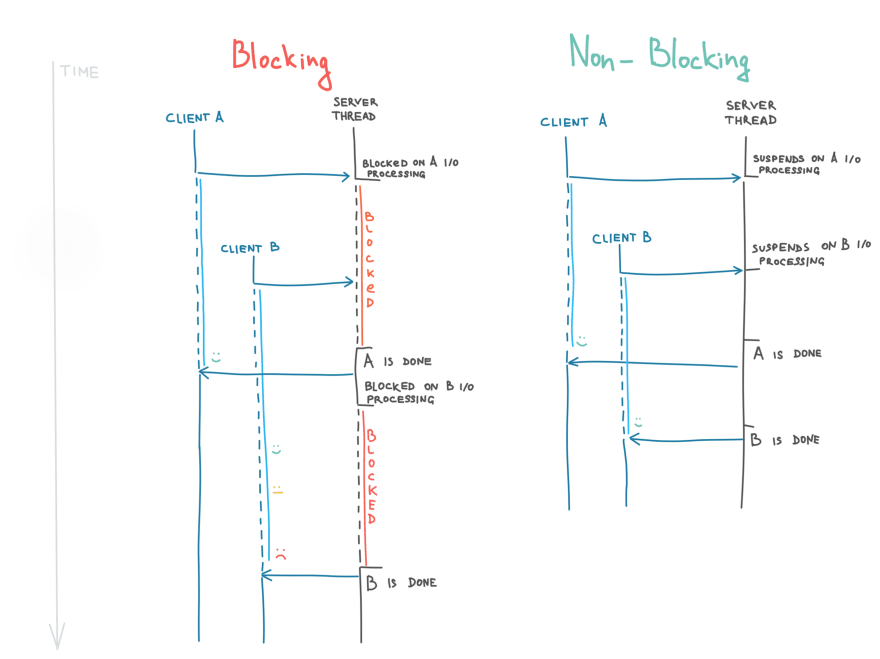
- It’s non-blocking
Blocking applications utilize threads inefficiently. When an expensive I/O operation is being executed, a blocking thread remains in a waiting (blocked) state. And if at some point all available threads are blocked, an application is temporarily paralyzed and can’t serve any more requests.
As opposed to such behavior, non-blocking threads suspend their execution on I/O operations. They’re immediately available to serve new incoming requests while the result of the I/O operation is pending. It allows serving more parallel requests than with blocking threads by orders of magnitude.
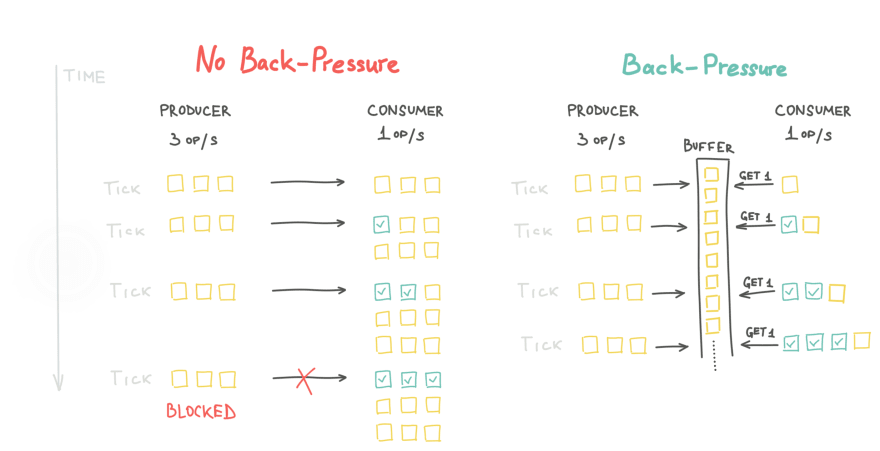
- It has back-pressure
By design, it gives a way for subscribers to control throughput by requesting events in batches of specified size. A chain of data processors with throttling won’t block in cascade due to a slow consumer. It would emit data in chunks, which can be accepted not clogging downstream and not waiting in a blocked state.
In Reactive Streams API implementation, a producer that is faster than its subscriber has two strategies: buffering items or dropping them.
- It gracefully handles failures
Reactive systems are more tolerant to failures and pass them the same way as messages. A service should recover and retry when something fails in the middle of data stream. It wouldn’t loudly crash but rather notify about failure using the same publish-subscribe channels.
So what exactly is “Reactive Programming” in such terms? It’s a development paradigm in which you use declarative code, which make it similar to functional programming, to define asynchronous behavior of message handlers. It enables us to build asynchronous message-driven data flows, where data is streamed from producers to subscribers.
Having unified Reactive Streams API is important here for different libraries and drivers can operate in chains.
Lastly, how does it help us creating better client-server applications? In particular cases it gives lower memory footprint and more efficient CPU utilization than in a plain web application. Which means it’s rather purposeful when your app needs to serve great amount of concurrent users.
One definitely shouldn’t implement it unless an application is close to its performance capacity. It’s delusional to think that since it’s a new concept, everything should be built reactive now. For many projects it won’t be a best fit. Keep in mind that a trade-off of reactive code is that debugging of async calls is highly difficult, which results in additional efforts to ensure required observability.
As Reactive Streams is still a relatively new API, it has already been widely adopted and community built expertise about use cases. Looking through them will significantly help to form a view. Just treat the new paradigm with a due pragmatism: most of day-to-day apps are still fine not being reactive.
Read more fundamentals on this topic:
The Essence of Reactive Programming in Java
And more reading on use cases:
Java Reactive Programming - Effective Usage in a Real World Application





Top comments (2)
great work. I picked up Kotlin and it was the best decision I have made in a long time. I think programmatic languages are cleaner, faster and more fun to work with. Sub'd
Thanks Al! Stay tuned, I’m preparing more articles on Kotlin features including sample backend project step-by-step creation guide