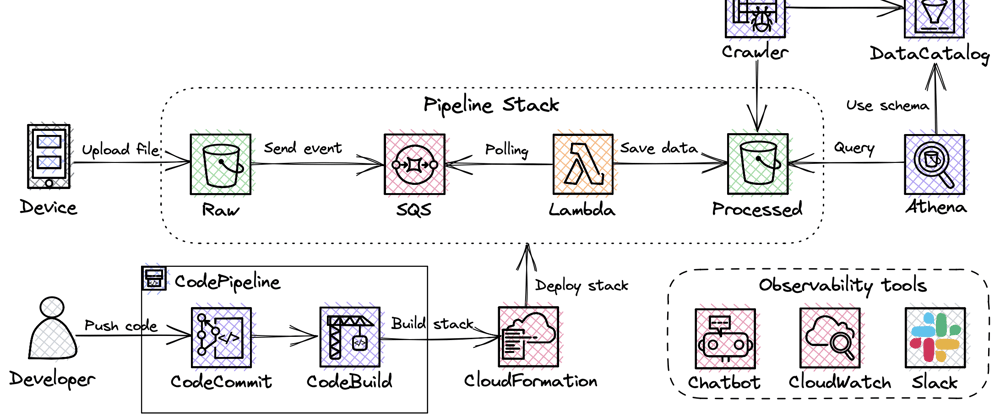

Context
Data science team are about to start a research study and they requested a solution on AWS cloud. Here is what I got to offer them:
Main process (Data Processing):
- Device uploads .mat file with ECG data to S3 bucket (Raw)
- Upload triggers event creation which is sent to SQS queue.
- Lambda polls SQS queue (event mapping invocation) and starts processing event. Lamba’s runtime is Python Docker container because libraries’ size exceed layers’ size limit of 250 MB. If any error occurs in the process, you’ll get notification in Slack.
- Once completed, processed data in parquet format is saved to S3 Bucket (Processed).
- To enable data scientists to query the data, Glue Crawler job creates a schema in the Data Catalog. Then, Athena is used to query Processed bucket.
Secondary process (CI/CD):
When a developer wants to change processing job logic, he should just prepare the changes and commit them to the CodeCommit repository. Everything else is automated and handled by CI/CD process.
CodeBuild service converts CDK code into CloudFormation template and deploys it to your account. In other words, it creates all infrastructure components automatically. Once completed, deployed resources’ group (stack) is available in CloudFormation service on web UI. To simplify these two steps and provide self-updates for CI/CD process as well, CodePipeline abstraction is used. You’ll also get Slack notifications about the progress.
Preparation
To prepare your local environment for this project, you should follow the steps described below:
- Install AWS CLI and set up credentials.
- Install NodeJS to be able to use CDK.
- Install CDK using command
sudo npm install -g aws-cdk. - Create new directory for your project and change your current working directory to it.
- Run
cdk init --language pythonto initiate CDK project. - Run
cdk bootstrapto bootstrap AWS account with CDK resources. - Install Docker to run Docker container inside Lambda.
Project Structure
This is the final look of the project. I will provide a step-by-step guide so that you’ll eventually understand each component in it.
DataPipeline
├── assets
│├── lambda
││├── dockerfile
││└── processing.py
├──cdk.out
│└── ...
├── stacks
│├── __init__.py
│├── data_pipeline_stack.py
│├── cicd_stack.py
│└──data_pipeline_stage.py
├── app.py
├── cdk.json
└── requirements.txt
Our starting point is stacks directory. It contains mandatory empty file __init__.py to define a Python package. Three other files are located here:
data_pipeline_stack.pycicd_stack.pydata_pipeline_stage.py
At first, we open data_pipeline_stack.py and import all libraries and constructs needed for further development. Also, we need to define class with parent class cdk.Stack.
import aws_cdk as cdk
import aws_cdk.aws_s3 as _s3
import aws_cdk.aws_sqs as _sqs
import aws_cdk.aws_iam as _iam
import aws_cdk.aws_ecs as _ecs
import aws_cdk.aws_ecr as _ecr
import aws_cdk.aws_lambda as _lambda
import aws_cdk.aws_s3_notifications as _s3n
from aws_cdk.aws_ecr_assets import DockerImageAsset
from aws_cdk.aws_lambda_event_sources import SqsEventSource
class DataPipelineStack(cdk.Stack):
def __init__(self, scope, construct_id, **kwargs):
super().__init__(scope, construct_id, **kwargs)
After that, we use SQS Queue construct to connect S3 bucket and Lambda. Arguments are pretty simple: stack element id (‘raw_data_queue’) , queue name (‘data_pipeline_queue’) and time that message in the queue will not be visible after Lambda takes it for processing (cdk.Duration.seconds(200)). Note that visibility timeout value depends on your processing time — if processing takes 30 seconds, it is better to set it to 60 seconds. In this case, I set it to 200 seconds because processing takes ~100 sec.
data_queue = _sqs.Queue(self, 'raw_data_queue',
queue_name='data_pipeline_queue',
visibility_timeout=cdk.Duration.seconds(200))
Next, we will create S3 buckets for raw and processed data using Bucket construct. Having in mind that raw data usually is accessed within several first days after upload, we can add lifecycle_rules to transfer data from S3 Standard to S3 Glacier after 7 days to reduce storage cost.
raw_bucket = _s3.Bucket(self, 'raw_bucket',
bucket_name='raw-ecg-data',
auto_delete_objects=True,
removal_policy=cdk.RemovalPolicy.DESTROY,
lifecycle_rules=[_s3.LifecycleRule(
transitions=[_s3.Transition(
storage_class=_s3.StorageClass.GLACIER,
transition_after=cdk.Duration.days(7))])])
raw_bucket.add_event_notification(_s3.EventType.OBJECT_CREATED,
_s3n.SqsDestination(data_queue))
_s3.Bucket(self, 'processed_bucket',
bucket_name='processed-ecg-data',
auto_delete_objects=True,
removal_policy=cdk.RemovalPolicy.DESTROY)
Also, we need to connect raw bucket and SQS queue to define destination for events which are generated from the bucket. For that, we use add_event_notification method with two arguments: event we want queue to be notified on (_s3.EventType.OBJECT_CREATED) and destination queue to notify (_s3n.SqsDestination(data_queue)).
⚠️ After stack is destroyed, bucket and all the data inside it will be deleted. This behaviour can be changed by deleting (setting to default) removal_policy and auto_delete_objects arguments.
Next step is to create Lambda using DockerImageFunction construct. Please refer to the code below to see what arguments I define. I think they are pretty self-explanatory and you are already familiar with previous examples so I believe it won’t be a hard time. In case of troubles please refer to documentation.
⚠️ The only thing I should highlight is the value of
timeoutparameter in Lambda — it should always be less thanvisibility_timeoutparameter in Queue (180vs200).
processing_lambda = _lambda.DockerImageFunction(self,
'processing_lambda',
function_name='data_processing',
description='Starts Docker Container in Lambda to process data',
code=_lambda.DockerImageCode
.from_image_asset('assets/lambda/',
file='dockerfile'),
architecture=_lambda.Architecture.X86_64,
events=[SqsEventSource(data_queue)],
timeout=cdk.Duration.seconds(180),
retry_attempts=0,
environment={'QueueUrl':
data_queue.queue_url})
processing_lambda.role.attach_inline_policy(_iam.Policy(self,
'access_fer_lambda',
statements=[_iam.PolicyStatement(
effect=_iam.Effect.ALLOW,
actions=['s3:*'],
resources=['*'])]))
Then, we attach policy to automatically created Lambda role, so it can process files from S3 using attach_inline_policy method. You can tune actions/resources parameter to grant Lambda more granular access to S3.
Now we move to assets directory.
There we need to create dockerfile and processing.py with data transformation logic, which is pretty simple. At first, we parse event from SQS to get information about file and bucket, then parse .mat file with ECG data, clean it and save it in .parquet format to Processed bucket. Also, it includes logging and Slack error messages. In the end, we should delete message from queue, so file is not processed again.
For your pipeline, you can change processing logic and replace _url with your own Slack hook.
import io
import json
import os
import boto3
import urllib3
import logging
import scipy.io
import pandas as pd
import pathlib as pl
import awswrangler as wr
from urllib.parse import unquote_plus
s3 = boto3.client('s3')
sqs = boto3.client('sqs')
def handler(event, context):
# Parse event and get file name
message_rh = event['Records'][0]['receiptHandle']
key = json.loads(event['Records'][0]['body'])['Records'][0]['s3']['object']['key']
key = unquote_plus(key)
raw_bucket = json.loads(event['Records'][0]['body'])['Records'][0]['s3']['bucket']['name']
processed_bucket = 'processed-ecg-data'
try:
# Read mat file
_obj = s3.get_object(Bucket=raw_bucket, Key=key)['Body'].read()
raw_data = scipy.io.loadmat(io.BytesIO(_obj))
# Clean data
_df = pd.DataFrame(raw_data['val'][0], columns=['ECG_data'])
_df.fillna(method='pad', inplace=True)
_df['ECG_data'] = (_df['ECG_data'] - _df['ECG_data'].min()) / (_df['ECG_data'].max() - _df['ECG_data'].min())
# Save parquet file to verified bucket
file_name = pl.Path(key).stem
wr.s3.to_parquet(df=_df, path=f's3://{processed_bucket}/{file_name}.parquet')
logging.info(f'File {file_name} was successfully processed.')
except Exception:
# Send notification about failure to Slack channel
_url = 'https://hooks.slack.com/YOUR_HOOK'
_msg = {'text': f'Processing of {key} was unsuccessful.'}
http = urllib3.PoolManager()
resp = http.request(method='POST', url=_url, body=json.dumps(_msg).encode('utf-8'))
# Write message to logs
logging.error(f'Processing of {key} was unsuccessful.', exc_info=True)
# Delete processed message from SQS
sqs.delete_message(
QueueUrl=os.environ.get('QueueUrl'),
ReceiptHandle=message_rh)
Let’s go quickly through the logic of Docker file: at first, we pool special image for Lambda from AWS ECR repository, then install all Python libraries, copy our processing.py script to container and run command to launch handler function from the script.
FROM public.ecr.aws/lambda/python:3.8
RUN pip3 install pandas && \
pip3 install numpy && \
pip3 install boto3 && \
pip3 install scipy && \
pip3 install awswrangler
WORKDIR /
COPY processing.py ${LAMBDA_TASK_ROOT}
CMD [ "processing.handler" ]
⚠️ Do not forget add libraries you used in
processing.pytodockerfile.
At this stage we finished creating Data pipeline stack and can go further and start developing CI/CD stack.
CI/CD stack
For CI/CD process we will use CodePipeline service, which helps us to make deployment process easier. Each time we change Data pipeline or CI/CD stack via CodeCommit push, CodePipeline will automatically re-deploy both stacks. In short, stack for application should be added to CodePipeline stage, after that stage is added to CodePipeline. After that app is synthesised for CI/CD stack, not application stack. You can find more detailed description of connection between files and logic behind CodePipeline construct below.
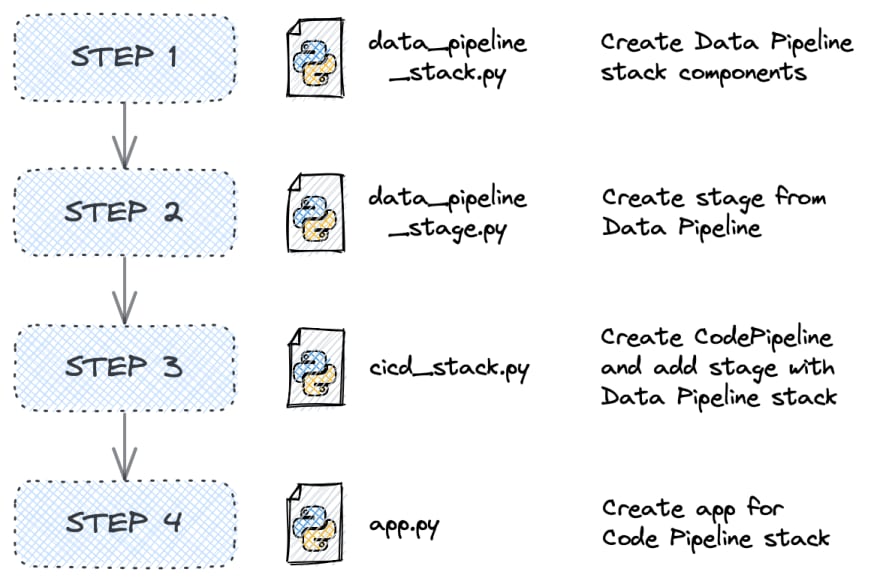
At first, we need to open cicd_stack.py and start with import of all libraries and constructs we will use. Later, we will create CodeCommit repository manually, but for now we need only reference to it, so we can add it as source for CodePipeline.
import aws_cdk as cdk
import aws_cdk.aws_iam as _iam
import aws_cdk.aws_chatbot as _chatbot
import aws_cdk.aws_codecommit as _ccommit
from stacks.data_pipeline_stage import *
import aws_cdk.aws_codestarnotifications as _notifications
from aws_cdk.pipelines import CodePipeline, CodePipelineSource, ShellStep
class CICDStack(cdk.Stack):
def __init__(self, scope, construct_id, **kwargs):
super().__init__(scope, construct_id, **kwargs)
pipeline_repo = _ccommit.Repository.from_repository_arn(
self, 'data_pipeline_repository',
repository_name='data_pipeline_repository')
We use CodePipeline construct to create CI/CD process. We use parameter self_mutation set to True to allow pipeline to update itself, it has True value by default. Parameter docker_enables_for_synth should be set to True if we use Docker in our application stack. After that, we add stage with application deployment and initiate pipeline build to construct our pipeline. Latter is necessary step to set up Slack notifications in the future.
pipeline = CodePipeline(self, 'cicd_pipeline',
pipeline_name='cicd_pipeline',
docker_enabled_for_synth=True,
self_mutation=True,
synth=ShellStep('Synth',
input=CodePipelineSource.code_commit(
pipeline_repo, 'master'),
commands=['npm install -g aws-cdk',
'python -m pip install -r
requirements.txt',
'cdk synth']))
pipeline.add_stage(DataPipelineStage(self, 'DataPipelineDeploy'))
cicd_pipeline.build_pipeline()
Next step is to configure Slack notifications for CodePipeline, so developers can monitor deployment. For that we use SlackChannelConfiguration construct. We can get value for slack_channel_id by right-clicking channel name and copying last 9 characters of URL. To get slack_workspace_id parameter value, use AWS Chatbot Guide. To define types of notifications we want to get, we use NotificationRule constract. If you want to define events for notification more granularly, use Events for notification rules.
slack = _chatbot.SlackChannelConfiguration(self, 'MySlackChannel',
slack_channel_configuration_name='#cicd_events',
slack_workspace_id='YOUR_ID',
slack_channel_id='YOUR_ID')
slack.role.attach_inline_policy(_iam.Policy(self, 'slack_policy',
statements=[_iam.PolicyStatement(effect=_iam.Effect.ALLOW,
actions=['chatbot:*'],
resources=['*'])]))
rule = _notifications.NotificationRule(self, 'NotificationRule',
source=cicd_pipeline.pipeline,
detail_type=_notifications.DetailType.BASIC,
events=['codepipeline-pipeline-pipeline-execution-started',
'codepipeline-pipeline-pipeline-execution-succeeded',
'codepipeline-pipeline-pipeline-execution-failed'],
targets=[slack])
ℹ️ With .pipeline property we refer to the CodePipeline pipeline that deploys the CDK app. It is available only after the pipeline has been constructed with build_pipeline() method. For
sourceargument we should pass not construct, but pipeline object.
After defining pipeline we add stage for Data pipeline deploy. To make our project cleaner, we define stage for Data Pipeline deployment in separate file. For that we use cdk.Stage parent class.
import aws_cdk as cdk
from constructs import Construct
from stacks.data_pipeline_stack import *
class DataPipelineStage(cdk.Stage):
def __init__(self, scope, construct_id, **kwargs):
super().__init__(scope, construct_id, **kwargs)
DataPipelineStack(self, 'DataPipelineStack')
For those of you, who use CDKv1, additional step is to modify cdk.json configuration file, you should add the following expression to context.
"context": {"@aws-cdk/core:newStyleStackSynthesis": true}
At this point, we created all constructs and files for Data pipeline stack. The only thing left is to create app.py with all final steps. We import all constructs we created from cicd_stack.py and create tags for all stack resources.
from stacks.cicd_stack import *
app = cdk.App()
CICDStack(app, 'CodePipelineStack,
env=cdk.Environment(account='REPLACE WITH_YOUR_ACCOUNT',
region='YOUR_REGION'))
cdk.Tags.of(app).add('env', 'prod')
cdk.Tags.of(app).add('creator', 'anna-pastushko')
cdk.Tags.of(app).add('owner', 'ml-team')
app.synth()
Congratulations, we finished creating our stacks. Now, we can finally create CodeCommit repository called data_pipeline_repository and push files to it.

We can manually add the same tags as we created in the Stack, so we can see all our resources created for this task bound together in cost reports.
⚠️ Check limitations for CodeBuild in Service Quotas before deployment.
Congratulations, now we can finally deploy our stack to AWS using command cdk deploy and enjoy how all resources are set up automatically.
Athena queries
Let’s start with Glue Crawler creation, for that you need to go to Data Catalog section in Glue console and click on Crawlers. Then you should click on add crawler button and go over all steps. I added the same tags as for other Data pipeline resources, so I can track them together.

Don’t change crawler source type, add S3 data store and specify path to your bucket in Include path. After that create new or add already existing role and specify how often you want to run it. Then you should create database , in my case I created ecg_data database. After all steps are completed and crawler is created, run it.
That is all we need to query processed_ecg_data table with Athena. Example of simple query can be found below.

Account cleanup
In case you want to delete all resources created in your account during development, you should perform the following steps:
- Run the following command to delete all stacks resources:
cdk destroy CodePipelineStack/DataPipelineDeploy/DataPipelineStack CodePipelineStack - Delete CodeCommit repository
- Clean ECR repository and S3 buckets created for Athens and CDK because it can incur costs.
- Delete Glue Crawler and Database with tables.
ℹ️ Command
cdk destroywill only destroy CodePipeline (CI/CD) stack and stacks that depend on it. Since the application stacks don't depend on the CodePipeline stack, they won't be destroyed. We need to destroy Data pipeline stack separately, there is a discussion on how to delete them both.
It is not very convenient to delete some resources manually and there are several discussions with AWS developers to fix it.
Conclusion
CDK provides you with toolkit for development of applications based on AWS services. It can be challenging at first, but your efforts will pay off at the end. You will be able to manage and transfer your application with one command.
CDK resources and full code can be found in GitHub repository.
Thank you for reading till the end. I do hope it was helpful, please let me know if you spot any mistakes in the comments.





Top comments (4)
Nice article, both for the data processing and the CI/CD!
Very well written, May I ask which tool you have used for the architecture diagrams?
Thanks, I used Excalidraw tool for that. You can add AWS icons from the Libraries page.
AWS icons library: https://libraries.excalidraw.com/?target=_excalidraw&referrer=https%3A%2F%2Fexcalidraw.com%2F&useHash=true&token=oxTuxENRiCuYHQGjVWveO&theme=light&version=2&sort=default#anna-pastushko-aws-architecture-icons
Thank you