
Apache Kafka Fundamentals
Apache Kafka is a distributed messaging system that provides fast, durable highly scalable and fault-tolerant messaging through a publish-subscribe (pub-sub) model. Kafka has higher throughput, reliability and replication characteristics. It is built for Big Data applications, real-time data pipelines, and streaming apps.
Apache Kafka was originally developed by LinkedIn, and was subsequently open sourced in early 2011. In November 2014, several engineers who worked on Kafka at LinkedIn created a new company named Confluent with a focus on Kafka.
Kafka as a distributed system runs in a cluster (a group of similar things or people positioned or occurring closely together). Each node in the cluster is called a Kafka broker.
The basic architecture of Kafka is organized around a few key terms: topics, producers, Consumers, and brokers.
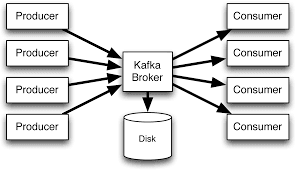
Kafka Terminology
Kafka Broker
Kafka runs as a distributed system in a cluster. There are one or more servers available in the cluster. each node in the cluster is called a Kafka Broker.
Brokers are responsible for receiving and storing the data when it arrives. The broker also provides the data when requested.
Kafka broker is more precisely described as a Message Broker which is responsible for mediating the conversation between different computer systems, guaranteeing delivery of the message to the correct parties.
Kafka Topic
Topics represent the logical collection of messages that belong to a group/category. The data sent by the producers is stored in topics. Consumers subscribe to a specific topic that they are interested in. A topic can have zero or more consumers.
In a nutshell, A topic is a category or feed name to which records are published.
Kafka Message
In Kafka, messages represent the fundamental unit of data. Each message is represented as a record, which comprises two parts: key and value. Irrespective of the data type, Kafka always converts messages into byte arrays.
Many other messaging systems also have a way of carrying other information along with the messages. Kafka 0.11 introduced record headers for this purpose.
Partitions
Topics are divided into one (default is one) or more partitions. A partition lives on a physical node and persists the messages it receives. A partition can be replicated onto other nodes in a master/slave relationship. There is only one “leader” node for a given partition which accepts all reads and writes — in case of failure a new leader is chosen. The other nodes just replicate messages from the “leader” to ensure fault-tolerance.
Kafka ensures strict ordering within a partition i.e. consumers will receive it in the order which a producer published the data, to begin with.
Kafka Producer
A Producer is an entity that publishes streams of messages to Kafka topics. A producer can publish to one or more topics and can optionally choose the partition that stores the data.
Kafka comes with its own producer written in Java, but there are many other Kafka client libraries that support C/C++, Go, Python, REST, and more.
Kafka Consumers
Consumers are the subscribers or readers that receive the data. Kafka consumers are stateful, which means they are responsible for remembering the cursor position, which is called as an offset.
Kafka Consumer Groups
A consumer group is a group of related consumers that perform a task.
Each consumer group must have a unique id. Each consumer group is a subscriber to one or more Kafka topics. Each consumer group maintains its offset per topic partition.
Kafka Producers
A Producer is an entity that consumes/reads messages from Kafka topics and processes the feed of messages. A consumer can consume from one or more topics or partitions.
Kafka Offset
The offset is a position within a partition for the next message to be sent to a consumer. Offset is used to uniquely identifies each record within the partition.
Kafka Consumer Lags
Kafka Consumer Lag is the indicator of how much lag there is between Kafka producers and consumers.
Inside the Kafka, data is stored in one or more topics. Each topic consists of one or more partitions. When writing data a Broker actually writes it into a specific Partition. As it writes data, it keeps track of the last “write position” in each Partition. This is called Latest Offset. Each Partition has its own independent Latest Offset.
Just like Brokers keep track of their write position in each Partition, each Consumer keeps track of “read position” in each Partition whose data it is consuming. This is known as Consumer Offset. This Consumer Offset is periodically persisted (to ZooKeeper or a special Topic in Kafka itself) so it can survive Consumer crashes or unclean shutdowns and avoid re-consuming too much old data.
The difference between the consumer offset and the latest offset is known as ** LAG**

Originally published at http://techmonks.org on July 13, 2019.

Top comments (1)
This was very helpful. Thank you for sharing