
1. Dice loss 是什麼 ?
Dice loss是Fausto Milletari等人在V-net中提出的Loss function,其源於Sørensen–Dice coefficient,是Thorvald Sørensen和Lee Raymond Dice於1945年發展出的統計學指標。這種coefficient有很多別名,最響亮的就是F test的F1 score。在了解Dice loss之前我們先談談Sørensen–Dice coefficient是什麼。
回顧一下比較常聽到的F1 score,統計學中有所謂的Sensitivity和Specificity,而機器學習(模式識別)則有Precision和Recall,它們的關係如下:
| Truth\Classified | Positive | Negative |
|---|---|---|
| Positive | True Positive | False Negative |
| Negative | False Positive | True Negative |

可看到Precision和Recall的主角都是被正確挑選的那一群,分別用挑選總數(TP+FP)和正確總數(TP+FN)來評估正確的比例。F1 score便是想以相同權重(β=1)的Harmonic mean(調和平均)去整合這兩個指標:
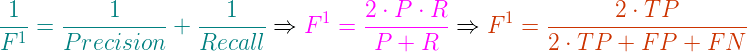
現在回到Sørensen–Dice coefficient的常見表現方式:
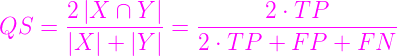
QS是Quotient of Similarity(相似商),就是coefficient的值,只會介於0~1。Image segmentation中,模型分割出的mask就是影像的挑選總數,專家標記的mask就是正確總數。對應到公式便可知挑選總數(TP+FP)和正確總數(TP+FN)分別就是X和Y,交集便是TP,可見Dice coefficient等同F1 score,直觀上是計算X與Y的相似性,本質上則同時隱含Precision和Recall兩指標。
談完了coefficient,Dice loss其實就是它的顛倒。當coefficient越高,代表分割結果與標準答案相似度越高,而模型則是希望用求極小值的思維去訓練比較可行,因此常用的Loss function有 "1-coefficient" 或 "-coefficient"。
2. Dice loss 實作
實作環境:
- Windows 10
- Python 3.6.4
- MXNet 1.0.1
因為是小測試就不用GPU了。公式中的交集在image segmentation中很好實現,因為通常標準答案的mask都是由0和1組成的,所以只要將兩張mask作逐點乘積(Hadamard product),也就是對應點相乘起來而不作向量內積,再加總起來就好了。因為False Positive跟Negative的情況就是其中一張mask值是0,所以在後續加總時會被排除。
另一個有趣的點是我在公式中加入了Laplace smoothing,也就是分子分母同時加1,這是啟發自一個pytorch的issue comment。據他所說,Laplace smoothing可以減少Overfitting,我想是因為讓整個coefficient值變大,讓loss變小,就可以更快達到收斂,而避免過多的訓練迭代。
from mxnet import nd
smooth = 1.
def dice_loss(y_pred, y_true):
product = nd.multiply(y_pred, y_true)
intersection = nd.sum(product)
coefficient = (2.*intersection +smooth) / (nd.sum(y_pred)+nd.sum(y_true) +smooth)
loss = 1. - coefficient
# or "-coefficient"
return(loss)
接著隨機生成兩個矩陣測試:
y_pred = nd.random.uniform(0, 1, (3,3))
y_true = nd.random.uniform(0, 2, (3,3)).astype('int8').astype('float32')
dice_loss(y_pred, y_true)
---------------------------------------------------------
y_pred = [[0.38574776 0.08795848 0.83927506]
[0.21592768 0.44453627 0.10463644]
[0.8793516 0.65118235 0.5184219 ]]
<NDArray 3x3 @cpu(0)>
y_true = [[1. 0. 0.]
[0. 0. 0.]
[1. 1. 1.]]
<NDArray 3x3 @cpu(0)>
product = [[0.38574776 0. 0. ]
[0. 0. 0. ]
[0.8793516 0.65118235 0.5184219 ]]
<NDArray 3x3 @cpu(0)>
intersection = [2.4347036] <NDArray 1 @cpu(0)>
coefficient = [0.64307916] <NDArray 1 @cpu(0)>
# no smooth : [0.59916145] <NDArray 1 @cpu(0)>
loss = [0.35692084] <NDArray 1 @cpu(0)>
# no smooth : [0.40083855] <NDArray 1 @cpu(0)>
以上結果用計算機敲一敲就可以驗證了,可以看到在有smooth的情況下,coefficient增大了而loss減少了,因此可以讓神經網絡更快收斂。
3. 後記
在2016年V-net開始使用後,Dice loss在2017年得到了一些進化,其中有篇文獻實驗比較了Dice loss和影像深度學習常用的Cross-entropy的性能,發現Dice loss在image segmentation真的表現比較好,所以我們之後來談一下Dice loss的最新進展吧!





Top comments (3)
Thank you for this excellent introduction on dice coefficient. Looking forward to your more sharing.
您好,您可以分享一下后续的关于 Dice loss 和 BCE loss 的文章的标题吗? 看到了这篇文章The Importance of Skip Connections in Biomedical Image Segmentation. 他也使用了Dice Coef 但是使用了不一样的实现,您怎么看
那篇的L(Dice) = 2 * (E(x * y)) / E(x) + E(y)
就是兩倍交集除聯集的意思
計算機按按看結果一樣