This article was originally posted on my personal blog.
A Bloom Filter is a space-efficient probabilistic data structure, created by Burton Howard Bloom in 1970. It is used to test whether an element is a member of a set with no false negatives.
In Bloom Filter, we hash an element with k-hashing algorithms, generate indices from these hashes and then set the value at these indices to 1 in the filter-list. To check if an element is in the set, we run the same k-hashing algorithms on that element and check if all the values at the indices produced by the hashes are 1. If all the values are 1 then the element is probably in the set and if any one of the value is 0, then the element is definitely not in the set.
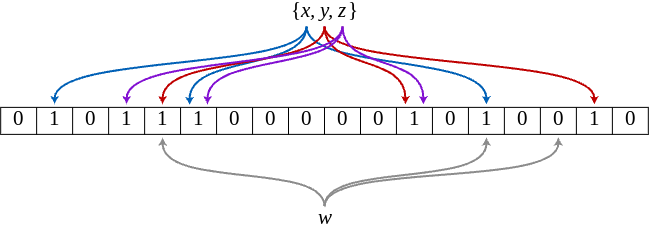
In the figure above, w is definitely not in the set since one of the value in the filter-list is 0.
Where is Bloom Filter Used?
Bloom Filter is most frequently used in cache layers to prevent caching of "One Hit Wonders". It avoids the caching of data requested only once. The data is cached only after multiple requests to the same data. Similarly, it is also used to avoid recommending articles a user has previously read. There are many other applications of Bloom Filter which can be found here.
Implementing a Simple Bloom Filter
We're going to learn about Bloom Filter by writing a simple implementation using Python as the programming language. In this program, we want to check if a query is definitely new or probably old using Bloom Filter.
Filter-List
A bloom filter can be implemented by using a list of a certain length. Initially all the members of the list are initialized to zero.
bloom_len = 10
bloom = [0] * bloom_len
Getting User Input
First, we get the input from the user inside a while loop so that we can take multiple inputs. We also need to encode the input text in 'utf-8' for hashing which will be described next.
while True:
query = str(input("Enter a query: ")).encode('utf-8')
Hashing
Here we use three hashing algorithms - md5, sha1 and sha224 since they are readily available in the hashlib package. These three hashing algorithms produce three output for the same query the user inputs. The outputs of the hash functions are stored in a list for further processing.
# query = str(input("Enter a query: ")).encode('utf-8')
m1 = hashlib.md5()
m2 = hashlib.sha1()
m3 = hashlib.sha224()
m1.update(query)
m2.update(query)
m3.update(query)
hash_values = [m1.digest(), m2.digest(), m3.digest()]
Find the Filter-Indices
After the hash values are calculated which are of bytes data type, we convert them into integers and store them in a list. The integers are then modulo divided by the length of the Bloom Filter to find the indices that need to be set inside the Bloom Filter.
# bloom = [0] * bloom_len
def bytes_to_int(hash_value):
return int.from_bytes(hash_value, byteorder='big')
def bloom_index(hashint):
return hashint % bloom_len
# while True:
# hash_values = [m1.digest(), m2.digest(), m3.digest()]
hashints = list(map(bytes_to_int, hash_values))
indices = list(map(bloom_index, hashints))
Filtering the Query
Now, we check if the query is new or not. As we already mentioned, Bloom Filter finds if the query is definitely new or probably old. To do this, we check the values present in the filter-list on the indices that we got by hashing the query. If any of the value in the filter at those indices is zero, we can be sure that the query is a new one. If all the values are one then the query is probably old.
If we're sure that the query is a new one, then we set the values at the indices to one for filtering future queries.
# return hashint % bloom_len
def new_query(indices):
new = False
for i in indices:
if bloom[i] == 0:
new = True
break
return new
def set_bloom(indices):
for i in indices:
bloom[i] = 1
# indices = list(map(bloom_index, hashints))
if new_query(indices):
print("Definitely new query")
set_bloom(indices)
else:
print("Probably old query")
Resetting the Filter
As more and more queries are processed, the values in the filter-list are updated This means that the rate of false positive increase steadily until every the element in the list becomes 1. To prevent this from happening, in our simple implementation, we'll reset the list if the number of 1s in the list is greater than 80% of the total elements in the list.
# while True:
if fill_percentage() > 80.0:
print("Resetting Bloom Filter-List")
bloom = [0] * bloom_len
# word = str(input("enter a word: ")).encode('utf-8')
Conclusion
You can try the program to check for the output generated after each query by giving in inputs. You can also change the value of bloom_len to play around with the program. This small implementation's design is not meant to be used for real systems but it is helpful to learn how Bloom Filter generally works.
Here's the complete code for the program:
import hashlib
bloom_len = 10
bloom = [0] * bloom_len
def bytes_to_int(hash_value):
return int.from_bytes(hash_value, byteorder='big')
def bloom_index(hashint):
return hashint % bloom_len
def fill_percentage():
return bloom.count(1) / bloom_len * 100;
def new_query(indices):
new = False
for i in indices:
if bloom[i] == 0:
new = True
break
return new
def set_bloom(indices):
for i in indices:
bloom[i] = 1
while True:
if fill_percentage() > 80.0:
print("Resetting Bloom Filter-List")
bloom = [0] * bloom_len
word = str(input("enter a word: ")).encode('utf-8')
m1 = hashlib.md5()
m2 = hashlib.sha1()
m3 = hashlib.sha224()
m1.update(word)
m2.update(word)
m3.update(word)
hash_values = [m1.digest(), m2.digest(), m3.digest()]
hashints = list(map(bytes_to_int, hash_values))
indices = list(map(bloom_index, hashints))
if new_query(indices):
print("Definitely new query")
set_bloom(indices)
else:
print("Probably old query")
External Resources
You can play with the interactive Bloom Filter demonstration by Jason Davies to help visualize the concepts. Wikipedia also has a comprehensive page on Bloom Filter.

Top comments (2)
Nice and clear explanation. Thanks!
Thank you very much for this.