Copying over data from MongoDB to S3
Very recently we were tasked with copying over data from our MongoDB DB to an S3 bucket.
Since the timelines were tight our immediate solution to this was deploy a lambda that will run once a day, query data from MongoDB and copy it to s3.
We sized up the data to be around 600k records. It did not seem like a lot and we were confident of achieving the same.
Long story short this turned out to be a bigger task than we thought and we ran into multiple problems.
I would like to talk about the problems we faced at each stage and how we improvised and finally arrived at a working solution.
At the end of the process I learnt a lot but I learnt that I have lots more to learn.
Ok getting down to details.
Tech Stack
AWS Lambda on Node.js 12.x
First Attempt
Our first attempt was a brute force attempt in hindsight.
The approach was:
- Query the collection asynchronously in batches of 100k
- Do a Promise.all on all the batches of queries
- Concatenate the results array
- Write the data to a s3 file
Outcome:
Since we tried to load all the 600k records into a string to put an object into s3 we ran out of memory even after allocating the maximum permissible memory 3008MB
Code:
Second Attempt
Based on our first attempt it was clear we had to handle our arrays carefully.
In the first attempt we first flattened the results array into a single array.
We then iterated over the flatenned array and transformed each db record into a string and then push it into another array and hence the memory was insufficient
The approach was:
- Do the array flatenning and transforming it to strings in a single array
- Write the data to a s3 file
Outcome:
Success !! we finally were able to write all the records to a s3 file
The issue was we used up all the 3008MB. So although it works for the current scenario, it is not future proof and we might run into memory issues again
![]()
Code:
Third Attempt
So although from the previous attempt we tasted success we need a more efficient way to handle these huge arrays of data.
Streams
A little google search and stackoverflow questions led me to streams in node.js
I will not delve deep into streams but rather quote resources that I referred to.
The main concept of streams is that when you have large amounts of data to work with, rather than loading it all in memory, just load smaller chunks of it and work with it.
On digging deeper we found that mongodb find and aggregate operations by default return streams.
We also found that s3 upload api accepted a readable stream and had the ability to do a multipart upload. This seemed like a perfect way to work.
Mongodb query results would be the data source and s3 file would be the sink.
The approach was:
- Stream the mongodb results
- Mongodb aggregate default cursor size streams 16MB worth of data
- Use s3 multipart upload api
Outcome:
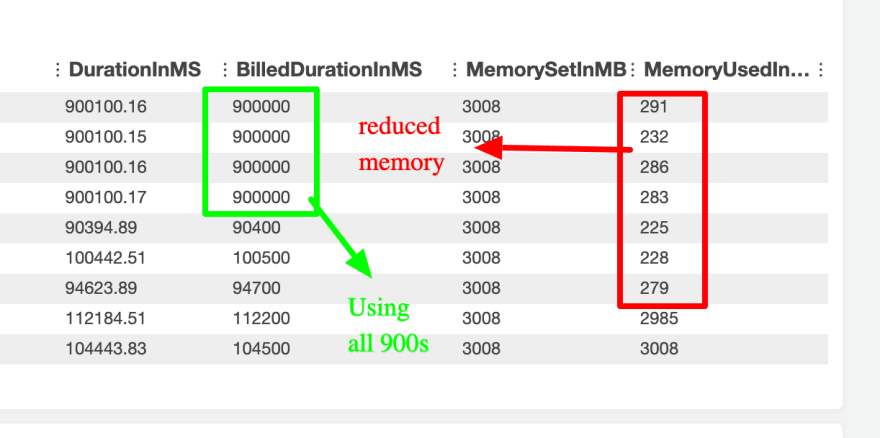
- Even more success !!. We managed to reduce the memory consumption from 3008MB to 200 - 300MB. That was a huge win for us.
- The issue was that there was some code issue because of which the node script would not exit and the lambda would timeout after the max time of 900 seconds even though the actual execution was completed way before Due to the timeout issue the lambda retries 3 times and so the file is written 3 times, wasted executions
Code:
Fourth Attempt
We had nailed down most of the approach and the question was how to exit the node.js function. We realized we did not call the callback function of the lambda handler once the upload was done. Once that was done we were able to complete the execution under 490 seconds and exit the function.


Top comments (0)