Jupyter Notebook is a fantastic tool for data exploration. It combines markdown text, executable code, and output all inside a single document served in a browser. While Jupyter is great for data science, I’m going to demonstrate the use of Notebook for a completely different use case: DevOps Runbook or simply put, a way to respond quickly to system outages.
Problem
Imagine you are spending an evening with your loved one and suddenly see a flurry of slack/pager alerts about your API latency climbing up. It’s all downhill from there. You get online and check all usual suspects: recent deployments, dependent services, load balancer, incoming traffic, database and so on. You jump from terminal to AWS console to NewRelic to conference call and what not. Let’s just say the whole experience is stressful until you find and fix the issue.
More matured organisations maintain runbooks for incident response. Runbook outlines the steps to be followed and takes the guess work out of debugging. First, let’s see some challenges with current form of runbooks:
- You need to manually execute each step, no automation
- Unless very well written, there can be ambiguity/confusion in following instructions
- It’s quite an effort to get everybody onboard to keep the runbooks up to date
Solution
To tackle some of these problems I am proposing use of Jupyter Notebooks for writing runbooks. Here’s how your API latency debugging session might look like inside a Notebook environment (please watch this video in full screen mode, original youtube link if needed).
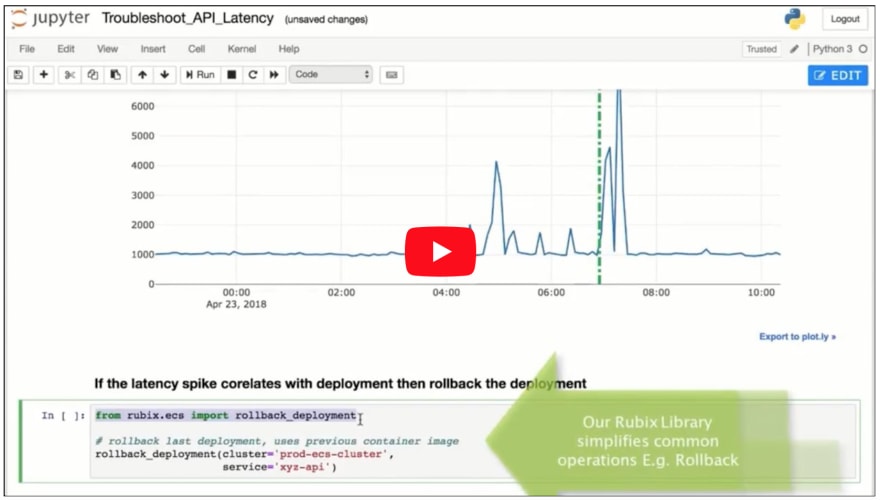
As you can see in the video, one can pull in graphs, check deployment times, rollback changes, run SQL queries, shell scripts, SSH all from within Notebook.
Benefits
Here are some benefits of maintaining your runbooks in executable Notebook format.
- Less confusion. Code is much more deterministic than instructions written in English.
- Reduces the incident time & impact. On-call responds faster with code required to investigate/fix an issue at her fingertip.
- Automate at your own pace. Since Notebook supports markdown, it’s possible to just import existing runbooks as is & automate a few steps every sprint.
- Better collaboration. It provides a first class platform for sharing all the tribal knowledge and local scripts that developers keep to combat an issue.
- There’s real power when we combine individual steps to build more complex logic. Following is possible today. It’s a step towards self healing system.
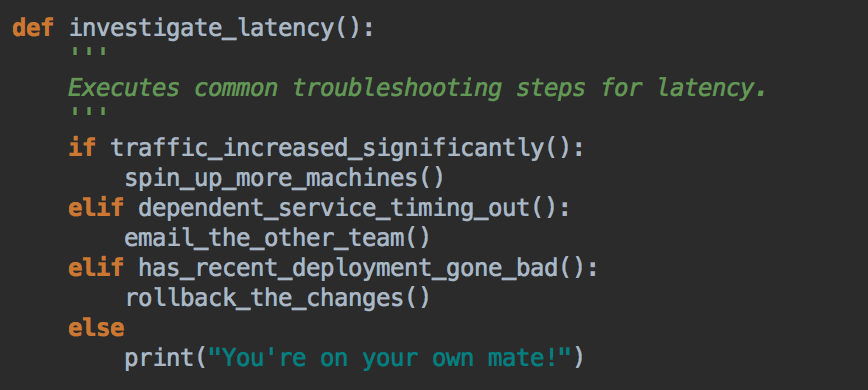
Challenges
Executable Notebook format is promising but here are some challenges with current Jupyter implementation.
- Typical Jupyter installation is single user local setup requiring the Jupyter server to be running locally. There’s no easy way to share Notebooks.
- Google Colaboratory could have been a good choice but it’s hosted on Google servers. The Notebook server needs to be self hosted for the code to have access to all the infrastructure within our VPC.
- Any infrastructure code will require credentials, ssh keys etc. We need a way to share them safely & not just stick it everywhere in the Notebook code snippets.
I’m building Nurtch, a platform that tackles these challenges & provides an easy way to write and share executable runbooks within team. Docs provide a complete overview of Nurtch capabilities and how-to’s. Let me know what you think of this approach to incident response.

Top comments (7)
I like this concept! Definitely going to keep this in the back of my mind.
Regarding sharing notebooks & the problem of having them run locally, would Azure Notebooks be something that could help in this case? notebooks.azure.com
Azure Notebooks are in the same bus as Google Collaboratory. They are both hosted Jupyter Notebook service, great for sharing/collaboration in the team. The problem with DevOps use case it is requires,
So if we are using Azure/Google Notebooks, we need to somehow allow their servers access to our infrastructure. This is almost impossible unless you allow your infra to be publicly accessible from the web (big security hazard). If there is some feature like your Azure/Google Notebooks can access your Azure/GCP infra then I'm not aware of it.
Storing your credentials on a third party hosted service is a bad idea. Even if their intentions are best they could be a victim of attack.
Because of these self hosted Notebook setup that allows sharing is the only way I see it being used in DevOps.
python.org/dev/peps/pep-0257/
Sure :)
Thanks for the link.
You could use AWS Sagemaker - these are basically AWS hosted Juypter notebooks that reduce the problems with single user problem and makes sharing easier.
Yes, but there are 2 limitations for our use case.
Sagemaker Jupyter is running on single EC2 instance and all notebooks are stored on the disk of that EC2 instance. If that instance dies for some reason, you can't access your Jupyter and all runbooks are gone.
Sagemaker is optimized for ML/Data science experiments. There is absolutely nothing that helps with DevOps use cases. Simple things like polling cloud watch graphs in Jupyter can be painful without some library help.
I am solving both these with nurtch.com
It's a cluster Jupyter setup with S3 as backend for storing Notebooks. I built a Rubix library that makes performing DevOps tasks easy in the notebook: docs.nurtch.com/en/latest/rubix-li...
Thanks David :)