
This article is about building a Reddit video downloader from scratch using python. Our downloader will be able to downloader video along with the audio.
Reddit makes it tough to download posted videos directly. This is because Reddit saves the audio and video separately on their servers. But this is not a big problem, as we will download both audio and video separately and join them using FFmpeg.
How to get the video URL?
Every Reddit post can be parsed as a JSON, simply by appending a .json to the URL. Thus,
https://www.reddit.com/r/PublicFreakout/comments/kwif5d/insurrectionist_gets_arrested_trying_to_break/
becomes
https://www.reddit.com/r/PublicFreakout/comments/kwif5d/insurrectionist_gets_arrested_trying_to_break.json
Go to the JSON URL, and you should see something like,

From there, it is easy. Press Ctrl + F and search for .mp4.
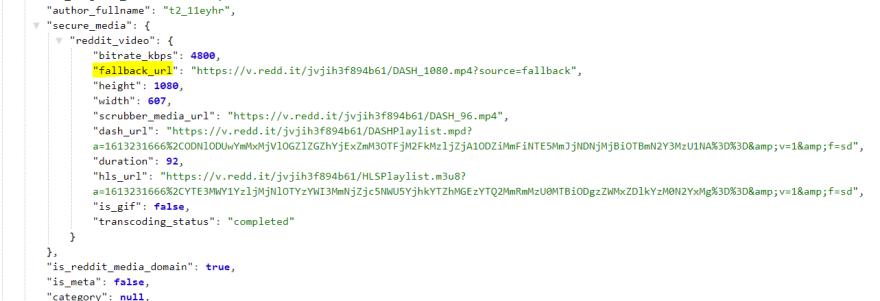
That's what we need, the fallback URL. Now have to figure out how to reach here starting from the top.
If you are trying to experiment with this on your own, make sure you either download the JSON or try using
jupyterorcolab. The Reddit rate-limiting feature won't allow you to fetch the JSON data frequently.
First, get the JSON data using requests.
data = requests.get(post_url).json()
where post_url is the JSON URL.
Obtain the URL using,
url = data[0]["data"]["children"][0]["data"]["secure_media"]["reddit_video"][
"fallback_url"
]
This is what a typical video URL looks like,
https://v.redd.it/jvjih3f894b61/DASH_1080.mp4?source=fallback
Not the best approach. Here we didn't even check if the keys existed. We'll assume this is the standard format for all posts.
What about the audio URL?
The audio URL is not available in the JSON data. But it can be obtained using a simple hack.
As mentioned above, this is the video URL. Go to the URL and check if it's video-only.
https://v.redd.it/jvjih3f894b61/DASH_1080.mp4?source=fallback
Here the DASH_1080.mp4 is the filename, where 1080 is the resolution. Replace the resolution with audio, and you get the audio URL.
Thus the audio URL corresponding to our URL is
https://v.redd.it/jvjih3f894b61/DASH_audio.mp4?source=fallback
Now that you have both audio and video, download them in a pythonic way.
import urllib.request
urllib.request.urlretrieve(
url,
filename=output_path,
)
If you are a big fan of progress bars, add one using the reporthook of urlretrieve.
from tqdm import tqdm
class DownloadProgressBar(tqdm):
def update_to(self, b: int = 1, bsize: int = 1024, tsize: int = None):
if tsize is not None:
self.total = tsize
self.update(b * bsize - self.n)
with DownloadProgressBar(unit="B", unit_scale=True, miniters=1) as d:
urllib.request.urlretrieve(
url,
filename=output_path,
reporthook=d.update_to,
)
Let's merge 'em
Once the files are downloaded to audio.mp4 and video.mp4, let's merge them using FFMpeg.
FYI, you can have any name for audio and video output files.
If you don't have FFmpeg installed, download it from here for windows.
For Linux,
sudo apt install ffmpeg
Now run the following to merge them both,
ffmpeg -i video.mp4 -i audio.mp4 -c:v copy -c:a aac output.mp4
It doesn't take more than a few seconds to merge. Once complete, enjoy the video.
Conclusion
In this post, we saw how to download a Reddit video along with its audio using python. There was nothing fancy in this approach; all we had to do was get the URL somehow.
If there's a better approach, please do tell.
I went ahead and created a python CLI named redl. Run,
redl https://www.reddit.com/r/PublicFreakout/comments/kwif5d/insurrectionist_gets_arrested_trying_to_break/
to download a video.
The whole code can be found at
redl - A Reddit video downloader(with audio)
⚠️ Requires ffmpeg installed
Redl scrapes the reddit post json and retrives both audio and video URLs. Once these files are downloaded, it uses ffmpeg to join them.
Installation
pip install redl --user
Usage
redl https://www.reddit.com/r/Damnthatsinteresting/comments/kwrbde/making_a_grapefruit_dessert/

Top comments (1)
Nice. I will try this. Very helpful 👍