In this article we see how to store and retrieve files on AWS S3 using Elixir and with the help of ExAws.
We start by setting up an AWS account and credentials, configure an Elixir application and see the basic upload and download operations with small files.
Then, we see how to deal with large files, making multipart uploads and using presigned urls to create a download stream, processing data on the fly.
Create an IAM user, configure permissions and credentials
If you don't have an Amazon Web Services account yet, you can create it on https://aws.amazon.com/ and use the free tier for the first 12 months where you have up to 5GB of free S3 storage.
Be sure you check all the limits of the free tier before you start using the service. Always take a look at the billing page to keep track of the usage.
To access to AWS S3 resources, first we need to create an AWS IAM (Identity and Access Management) user with limited permissions.
Once logged into the AWS console, go to the users section of the security credentials page and click on Add user.
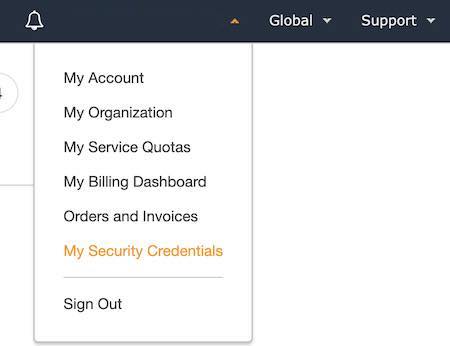
Menu on the top-right side of the AWS console
Create a new IAM user
When creating a user, we need to set a username and most importantly enable the Programmatic access: this means the user can programmatically access to the AWS resources via API.
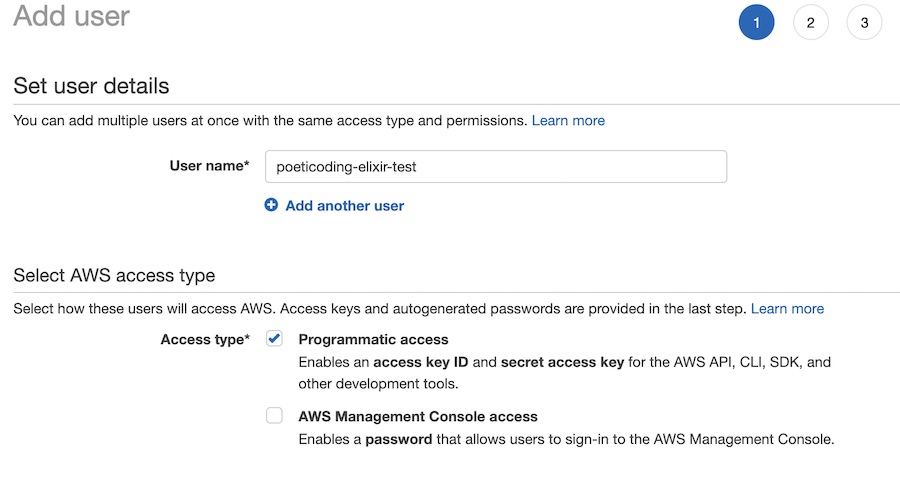
Username and Programmatic access
Then we set the permissions, attaching the AmazonS3FullAccess policy and limiting the user to just the S3 service.
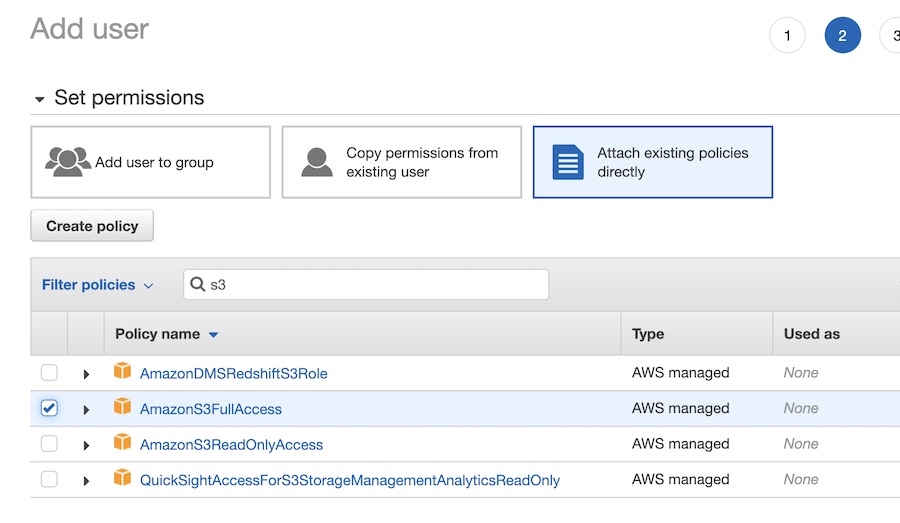
AmazonS3FullAccess policy
Now, this policy is fine for this demo, but it's still too broad: a user, or an app, can access to all the buckets, files and settings of S3.
By creating a custom policy, we can limit the user permissions to only the needed S3 actions and buckets. More on this at AWS User Policy Examples
Once the user is created, we can download the Access Key Id and the Secret Access Key. You must keep these keys secret because whoever has them can access to your AWS S3 resources.

IAM user Access key ID and Secret access key
To create an S3 bucket using the AWS console, go to the S3 section and click on Create bucket, set a bucket name (I've used poeticoding-aws-elixir) and be sure to block all the public access.
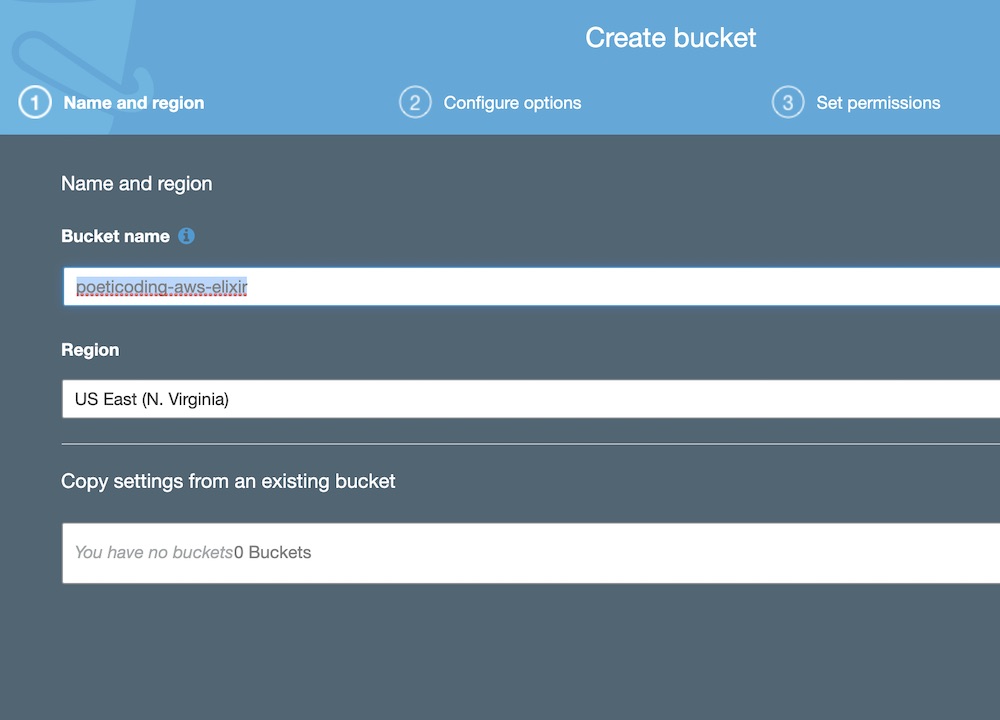
Bucket name and region

Block all public access
Configure ex_aws and environment variables
Let's create a new Elixir application and add the dependencies to make ex_aws and ex_aws_s3 work
# mix.exs
def deps do
[
{:ex_aws, "~> 2.1"},
{:ex_aws_s3, "~> 2.0"},
{:hackney, "~> 1.15"},
{:sweet_xml, "~> 0.6"},
{:jason, "~> 1.1"},
]
end
ExAws, by default, uses hackney HTTP Client to make requests to AWS.
We create the config/config.exs configuration file, where we set access id and secret access keys
# config/config.exs
import Config
config :ex_aws,
json_codec: Jason,
access_key_id: {:system, "AWS_ACCESS_KEY_ID"},
secret_access_key: {:system, "AWS_SECRET_ACCESS_KEY"}
The default ExAws JSON codec is Poison. If we want to use another library, like Jason, we need to explicitly set the jason_codec property.
We don't want to write our keys in the configuration file. First, because who has access to the code can see them, second because we want to make them easy to change.
We can use environment variables: by passing {:system, "AWS_ACCESS_KEY_ID"} and {:system, "AWS_SECRET_ACCESS_KEY"} tuples the application gets the keys from the AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY environment variables.
In case you are on a Unix/Unix-like system (like MacOs or Linux), you can set these environment variables in a script
# .env file
export AWS_ACCESS_KEY_ID="your access key"
export AWS_SECRET_ACCESS_KEY="your secret access key"
and load them with source
$ source .env
$ iex -S mix
Keep this script secret. If you are using git remember to put this script into .gitignore to avoid to commit this file.
If you don't want to keep these keys in a script, you can always pass them when launching the application or iex
$ AWS_ACCESS_KEY_ID="..." \
AWS_SECRET_ACCESS_KEY="..." \
iex -S mix
In case you're on a Windows machine, you can set the environment variables using the command prompt or the PowerShell
# Windows CMD
set AWS_ACCESS_KEY_ID="..."
# Windows PowerShell
$env:AWS_ACCESS_KEY_ID="..."
Listing the buckets
Now we have everything ready: credentials, application dependencies and ex_aws configured with environment variables. So let's try the first request.
# load the environment variables
$ source .env
# run iex
$ iex -S mix
iex> ExAws.S3.list_buckets()
%ExAws.Operation.S3{
http_method: :get,
parser: &ExAws.S3.Parsers.parse_all_my_buckets_result/1,
path: "/",
service: :s3,
...,
}
The ExAws.S3.list_buckets() function doesn't send the request itself, it returns an ExAws.Operation.S3 struct. To make a request we use ExAws.request or ExAws.request!
iex> ExAws.S3.list_buckets() |> ExAws.request!()
%{
body: %{
buckets: [
%{
creation_date: "2019-11-25T17:48:16.000Z",
name: "poeticoding-aws-elixir"
}
],
owner: %{ ... }
},
headers: [
...
{"Content-Type", "application/xml"},
{"Transfer-Encoding", "chunked"},
{"Server", "AmazonS3"},
...
],
status_code: 200
}
ExAws.request! returns a map with the HTTP response from S3. With get_in/2 we can get just the bucket list
ExAws.S3.list_buckets()
|> ExAws.request!()
|> get_in([:body, :buckets])
[%{creation_date: "2019-11-25T17:48:16.000Z", name: "poeticoding-aws-elixir"}]
put, list, get and delete
With ExAws, the easiest way to upload a file to S3 is with ExAws.S3.put_object/4
iex> local_image = File.read!("elixir_logo.png")
<<137, 80, 78, 71, 13, 10, 26, 10, 0, 0, ...>>
iex> ExAws.S3.put_object("poeticoding-aws-elixir", "images/elixir_logo.png", local_image) \
...> |> ExAws.request!()
%{
body: "",
headers: [...],
status_code: 200
}
The first argument is the bucket name, then we pass the object key (the path) and the third is the file's content, local_image. As a fourth argument we can pass a list of options like storage class, meta, encryption etc.
Using the AWS management console, on the S3 bucket's page, we can see the file we've just uploaded.
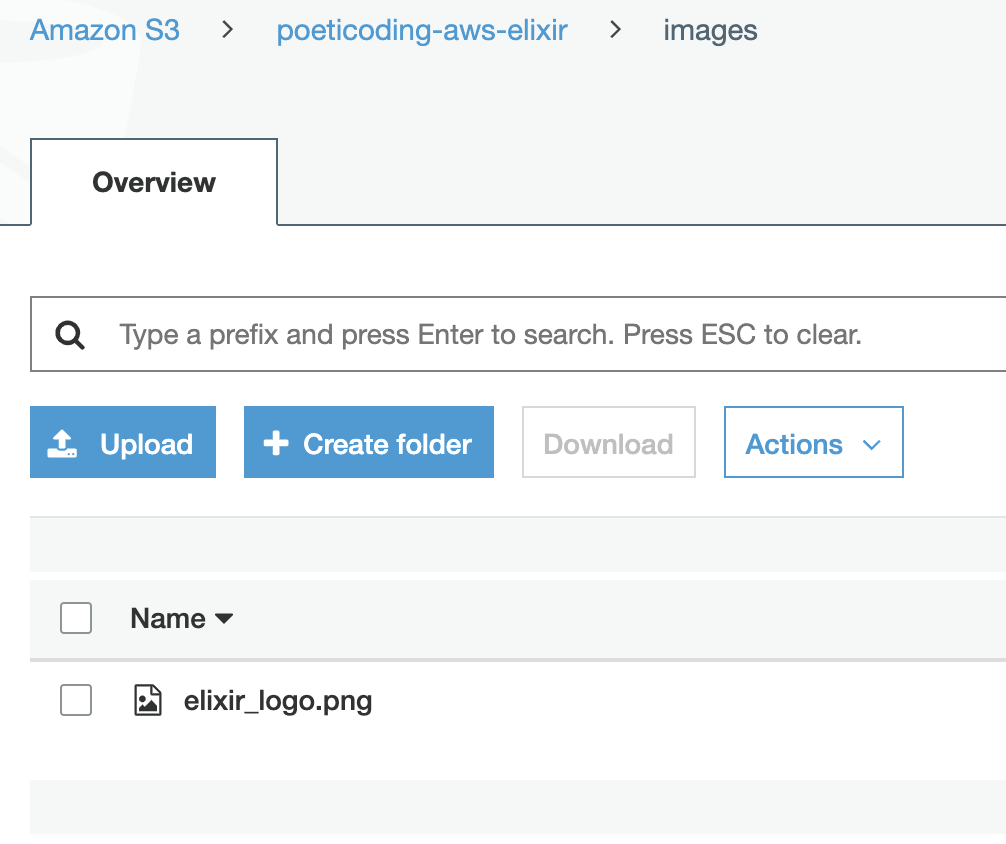
Uploaded file visible on AWS Management console
We list the bucket's objects with ExAws.S3.list_objects
iex> ExAws.S3.list_objects("poeticoding-aws-elixir") \
...> |> ExAws.request!() \
...> |> get_in([:body, :contents]) \
[
%{
e_tag: "\"...\"",
key: "images/elixir_logo.png",
last_modified: "2019-11-26T14:40:34.000Z",
owner: %{ ... }
size: "29169",
storage_class: "STANDARD"
}
]
Passing the bucket name and object key to ExAws.S3.get_object/2, we get the file's content.
iex> resp = ExAws.S3.get_object("poeticoding-aws-elixir", "images/elixir_logo.png") \
...> |> ExAws.request!()
%{
body: <<137, 80, 78, 71, 13, 10, 26, ...>>,
headers: [
{"Last-Modified", "Tue, 26 Nov 2019 14:40:34 GMT"},
{"Content-Type", "application/octet-stream"},
{"Content-Length", "29169"},
...
],
status_code: 200
}
The request returns a response map with the whole file's content in :body.
iex> File.read!("elixir_logo.png") == resp.body
true
We can delete the object with ExAws.S3.delete_object/2.
iex> ExAws.S3.delete_object("poeticoding-aws-elixir", "images/elixir_logo.png") \
...> |> ExAws.request!()
%{
body: "",
headers: [
{"Date", "Tue, 26 Nov 2019 15:04:35 GMT"},
...
],
status_code: 204
}
After listing again the objects we see, as expected, that the bucket is now empty.
iex> ExAws.S3.list_objects("poeticoding-aws-elixir")
...> |> ExAws.request!()
...> |> get_in([:body, :contents])
[]
Multipart upload and large files
The image in the example above is just ~30 KB and we can simply use put_object and get_object to upload and download it, but there are some limits:
- with these two functions the file is fully kept in memory, for both upload and download.
- put_object uploads the file in a single operation and we can upload only objects up to 5 GB in size.
S3 and ExAws client support multipart uploads. It means that a file is divided in parts (5 MB parts by default) which are sent separately and in parallel to S3! In case the part's upload fails, ExAws retries the upload of that 5 MB part only.
With multipart uploads we can upload objects from 5 MB to 5 TB - ExAws uses file streams, avoiding to keep the whole file in memory.
Let's consider numbers.txt, a relatively large txt file we've already seen in another article - Elixir Stream and large HTTP responses: processing text ( you can download from this url https://www.poeticoding.com/downloads/httpstream/numbers.txt).
numbers.txt size is 125 MB, much smaller than the 5GB limit imposed by the single PUT operation. But to me this file is large enough to benefit from a multipart upload!
iex> ExAws.S3.Upload.stream_file("numbers.txt") \
...> |> ExAws.S3.upload("poeticoding-aws-elixir", "numbers.txt") \
...> |> ExAws.request!()
# returned response
%{
body: "<?xml version=\"1.0\" encoding=\"UTF-8\"?>\n\n<CompleteMultipartUploadResult>...",
headers: [
{"Date", "Tue, 26 Nov 2019 16:34:08 GMT"},
{"Content-Type", "application/xml"},
{"Transfer-Encoding", "chunked"},
],
status_code: 200
}
- First we create a file stream with ExAws.S3.Upload.stream_file/2
- The stream is passed to ExAws.S3.upload/4, along with bucket name and object key
-
ExAws.request!initialize the multipart upload and uploads the parts
To have an idea of what ExAws is doing, we can enable the debug option in the ex_aws configuration
# config/config.exs
config :ex_aws,
debug_requests: true,
json_codec: Jason,
access_key_id: {:system, "AWS_ACCESS_KEY_ID"},
secret_access_key: {:system, "AWS_SECRET_ACCESS_KEY"}
We should see multiple parts being sent at the same time
17:11:24.586 [debug] ExAws: Request URL: "...?partNumber=2&uploadId=..." ATTEMPT: 1
17:11:24.589 [debug] ExAws: Request URL: "...?partNumber=1&uploadId=..." ATTEMPT: 1
Multipart upload timeout
When the file is large, the upload could take time. To upload the parts concurrently, ExAws uses Elixir Tasks - the default timeout for part's upload is set to 30 seconds, which could not be enough with a slow connection.
** (exit) exited in: Task.Supervised.stream(30000)
** (EXIT) time out
We can change the timeout by passing a new :timeout to ExAws.S3.upload/4, 120 seconds in this example.
ExAws.S3.Upload.stream_file("numbers.txt")
|> ExAws.S3.upload(
"poeticoding-aws-elixir", "numbers.txt",
[timeout: 120_000])
|> ExAws.request!()
Download a large file
To download a large file it's better to avoid get_object, which holds the whole file content in memory. With ExAws.S3.download_file/4 instead, we can download the data in chunks saving them directly into a file.
ExAws.S3.download_file(
"poeticoding-aws-elixir",
"numbers.txt", "local_file.txt"
)
|> ExAws.request!()
presigned urls and download streams - process a file on the fly
Unfortunately we can't use ExAws.S3.download_file/4 to get a download stream and process the file on the fly.
However, we can generate a presigned url to get a unique and temporary URL and then download the file with a library like mint or HTTPoison.
iex> ExAws.Config.new(:s3) \
...> |> ExAws.S3.presigned_url(:get, "poeticoding-aws-elixir", "numbers.txt")
{:ok, "https://...?X-Amz-Credential=...&X-Amz-Expires=3600"}
By default, the URL expires after one hour - with the :expires_in option we can set a different expiration time (in seconds).
iex> ExAws.Config.new(:s3) \
...> |> ExAws.S3.presigned_url(:get, "poeticoding-aws-elixir",
"numbers.txt", [expires_in: 300]) # 300 seconds
{:ok, "https://...?X-Amz-Credential=...&X-Amz-Expires=300"}
Now that we have the URL, we can use Elixir Streams to process the data on the fly and calculate the sum of all the lines numbers.txt. In this article you find the HTTPStream's code and how it works.
# generate the presigned URL
ExAws.Config.new(:s3)
|> ExAws.S3.presigned_url(:get, "poeticoding-aws-elixir", "numbers.txt")
# returning just the URL string to the next step
|> case do
{:ok, url} -> url
end
# using HTTPStream to download the file in chunks
# getting a Stream of lines
|> HTTPStream.get()
|> HTTPStream.lines()
## converting each line to an integer
|> Stream.map(fn line->
case Integer.parse(line) do
{num, _} -> num
:error -> 0
end
end)
## sum the numbers
|> Enum.sum()
|> IO.inspect(label: "result")
In the first two lines we generate a presigned url. Then, with HTTPStream.get we create a stream that lazily downloads the file chunk by chunk, transforming chunks into lines with HTTPStream.lines, mapping the lines into integers and summing all the numbers. The result should be 12468816.

Top comments (0)