
Our team recently implemented an internal corporate static website that allows employees to download technical reports.
Since we're heavy AWS users, we naturally decided to host it on AWS S3, which provides a dedicated feature to build static websites (S3 static website hosting).
However, we quickly ran into an issue: AWS S3 does not provide any native, out-of-the-box authentication/authorization process. Because it was an internal-only website, we needed some kind of authorization mechanism to prevent non-authorized users from accessing our website and reports.
We needed to find a solution to secure our internal static website on AWS S3.
Discovering the solution with CloudFront and Lambda@Edge
We use Okta for all Identity and User Management, so whatever solution we found had to plug-in with Okta.
Okta has several authentication/authorization flows, all of which require the application to perform a back-end check, such as verifying that the response/token returned by Okta is legit.
So we needed to find a way to carry these checks/actions on a static website which uses a back end that we don't control. That's when we learned about AWS Lambda@Edge, which lets you run Lambda Functions at different stages of a request and response to and from CloudFront:
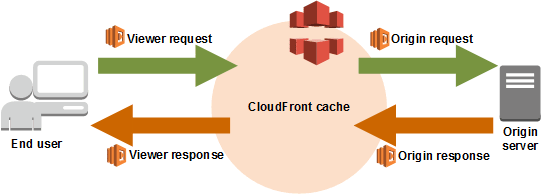
We can trigger a Lambda Function at four different stages:
- When the request enters CloudFront (
viewer-request) - When the request goes out to the origin (
origin-request) - When the response is returned from the origin (
origin-response) - When the response is returned from CloudFront (
viewer-response)
We saw a solution to our original issue: trigger a Lambda at the viewer-request stage that would check if the user is authorized. Two conditions:
- If the user is authorized, let the request continue and return the restricted content
- If the user is not authorized, send an HTTP response to redirect them to a login page

Implementing the Lambda@Edge function
We'll cover here the key elements and main issues we faced. The complete code is available here. Feel free to use it in your project!
Lambda@Edge restrictions and caveats
During the development of the solution, we ran into several restrictions and caveats of Lambda@Edge.
1 – Environment variables
Lambda@Edge Functions cannot use environment variables. That meant that we needed to find another way to pass data to our function. We opted for SSM parameters and templated parameter names in the Node.js code (we use Terraform to render the template when deploying the Lambda Function).
2 – Lambda package size limit
For viewer events (reminder: we use the viewer-request event), the Lambda package can be 1 MB at most. One MB is pretty small considering that it includes all dependencies (except of course the runtime/standard library) of your Lambda Function.
That's why we had to rewrite our Lambda in Node.js instead of the original Python, because the Python package with its dependencies exceeded the 1 MB limit.
3 – Lambda region
Lambda@Edge functions can only be created in the us-east-1 region. It's not a big issue but it means you'll need to:
- Provision your AWS resources in that region to make things easier
- In Terraform, you'll need to have a separate AWS
providerto access the bucket you want to protect if it's not inus-east-1
4 – Lambda role permission
The IAM execution role associated with the Lambda@Edge functions must allow the principal service edgelambda.amazonaws.com in addition to the usual lambda.amazonaws.com. See AWS - Setting IAM permissions and roles for Lambda@Edge.
Authorization mechanism with Okta
Once we managed the above restrictions and caveats, we focused on the authorization/authorization.
Okta offers several ways to authenticate and authorize users. We decided to go with OAuth2, the industry-standard protocol for authorization.
Note
Okta implements the OpenID Connect (OIDC) standard which adds a thin authentication layer on top of OAuth2 (that's the purpose of the ID token mentioned hereafter). Our solution would also work with pure OAuth2 with minimal modifications (removal of the ID token use in the code).
OAuth2 itself offers several authorization flows depending on the kind of application using it. In our case, we need the Authorization Code flow.
Here is the complete diagram of the Authorization Code flow taken from developer.okta.com that shows how it works:

- Our Lambda Function redirects the user to Okta where they will be prompted to login
- Okta redirects the user to our website/Lambda Function with a code
- Our Lambda Function checks if the code is legit and exchanges it for access and ID tokens by sending a request to Okta
- Depending on the result returned by Okta, we:
- Allow or deny access to the restricted content
- If access is allowed, save the access and ID tokens in a cookie to avoid having to re-authorize the user on every page
Using JSON Web Tokens to store authorization result
So far we have a working authorization process; however, we need to check the access/ID token on every request (a malicious user could forge an invalid cookie/tokens). Checking the tokens means sending a request to Okta and waiting for the response on every page the user visits, which slows down the loading times significantly and is clearly sub-optimal.
Note
While local verification of the Okta token is theoretically possible, as of this writing the SDK provided by Okta uses a LRU (in-memory) cache when fetching the keys used to check the tokens. Because we're using AWS Lambda, and memory/state of the program isn't kept between invocations, the SDK is useless to us: it would still send one HTTP request to Okta for every user request, to retrieve the JWKs (JSON Web Keys). Worse, there is a limitation of 10 JWK requests per minute, which would make our solution stop working if there is more than 10 requests per minute.
We decided to use JSON Web Tokens to work around this. The initial authorization process is the same except that, instead of saving the access/ID tokens into a cookie, we create a JWT containing these tokens, and then save the JWT into a cookie.
Since the JWT is cryptographically signed:
- A malicious actor cannot forge one (they would need the private key used to sign them)
- The checking step required on every request is fast: we traded a long and I/O expensive HTTP request for a quick cryptographic check.
Note on JWT expiration and renewal
The JWT has a pre-defined expiration time which should be reasonably short, to avoid having a valid JWT containing expired or revoked access/ID tokens. Another option would be to check the access/ID tokens regularly and revoke the associated JWT if needed, but then we would need a revocation mechanism, which would makes things more complex.
Finally, as suggested above, the tokens provided by Okta have an expiration time. It is possible to transparently renew them using a refresh token (so the user doesn't have to re-login when the tokens expire) but we didn't implement that.
Conclusion
While adding OAuth2 authentication to an S3 static bucket with Okta (or any other OAuth2 provider) is possible in an AWS-integrated and secure manner, it's certainly not straightforward.
It requires writing a middleware between AWS and the OAuth2 provider (Okta in our case) using Lambda@Edge. We had to do the following ourselves:
- Validate the user authentication
- Remember the user authentication
- Refresh the user authentication (not implemented in our solution)
- Revoke the user authentication (TTL is implemented, but revocation before the end of the TTL is not)
Finally, a bunch of AWS resources must be created to glue everything together and make it work.
But it's worth it, because it works and our website is now more secure.
You can find the code of the Lambda@Edge as well as the infrastructure (Terraform) here:
https://github.com/GuiTeK/aws-s3-oauth2-okta

Top comments (1)
This is really good post! break up spell with lemon