Welcome to another tutorial of Python. In this blog we learn about
- What is Pandas
- Installation of Pandas
- What is DataFrame?
- How to make DataFrames?
- Operations and Manipulations on DataFrame?
This topic lays the foundation of the Data Analysis with Python.
What is Pandas?
Pandas is the Python module builds on top of NumPy. It is one of the primary pillars of Data Analytics. It has high-level data structures.
DataFrames are the Data Structures provided by Pandas, accompanying with Panel and Series. Numpy arrays are homogeneous, to overcome the shortcoming, DataFrames are included in Pandas and are heterogeneous.
Installation of Pandas
The installation of Pandas is easy using pip command. Assuming you already have pip installed on your system.
pip install pandas install it on your local machine.
What is DataFrame?
DataFrame is:
- Two-Dimensional Data Structure with the different or same type of columns.
- DataFrame in Python consists of:
- Data
- Index
- Columns
- DataFrames may contain:
- DataFrame
- NumPy Arrays
- Pandas Series
- CSV file
- Dictionaries, lists.
How to Make DataFrame?
Besides various data to create a DataFrame, we will start with the NumPy Library and then discuss distinct inputs.
import numpy as np
import pandas as pd
array_1 = np.array([np.arange(10, 15), np.arange(15, 20)])
dataframe_1 = pd.DataFrame(array_1)
print("Value of Array_1: \n", array_1)
print("\nValue of DataFrame_1: \n", dataframe_1)
Execute the program.
You will see the following output on your screen.
Value of Array_1:
[[10 11 12 13 14]
[15 16 17 18 19]]
Value of DataFrame_1:
0 1 2 3 4
0 10 11 12 13 14
1 15 16 17 18 19
When we create a DataFrame using the NumPy arrays, Pandas automatically indexed the DataFrame rows and columns. Please refer to the below snapshot. The first row and the first column are indexed as 0 and then incremented by 1 till the end of the row or column.
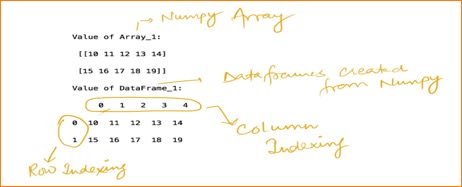
We also say that Pandas DataFrames are closely correlated with Microsoft excel like structure, Where we index rows and columns with values in it.
What we learned so far is DF is dynamically index by Pandas. In practical scenarios, it hardly happens. Instead of dynamic indexing, we want user-defined indexes on DataFrames.
Let’s do that.
import numpy as np
import pandas as pd
index = ['Row1', 'Row2', 'Row3']
columns = ['Col1', 'Col2', 'Col3', 'Col4']
array_1 = np.array([
(np.arange(11, 15)),
(np.arange(15, 19)),
(np.arange(19, 23))])
print("Value of Array_1: \n", array_1)
dataframe_1 = pd.DataFrame(data=array_1, index=index, columns=columns)
print("\nValue of DataFrame_1 is: \n", dataframe_1)
Here is the output, when you execute the above program.
Value of Array_1:
[[11 12 13 14]
[15 16 17 18]
[19 20 21 22]]
Value of DataFrame_1 is:
Col1 Col2 Col3 Col4
Row1 11 12 13 14
Row2 15 16 17 18
Row3 19 20 21 22
In the output, you can see the Row and Columns name in the DataFrame output.
Give attention to the line pd.DataFrame(data=array_1, index=index, columns=columns).
In the above line,
data -- contains the value of array_1
index -- has Row Names.
Columns -- has Column Names.
Index and column are optional parameters to DataFrame, if not provided then indexing starts from ‘0’.
You have created the DataFrame, if you have to find the number of rows and columns of the DataFrame.
In the above program, add print(dataframe_1.shape). And print(len(dataframe_1.index)), to get the number of elements of DataFrame.
In the previous example, we create DataFrames from the numpy arrays. However, in the real world, we rarely create DataFrame using numpy arrays directly. The CSV or Excel files serve as input to DataFrames.
Our next task is to create the DataFrames from the CSV file. We already have a sample CSV file uploaded to GitHub. You can download it from here.
Make sure you download the file, where your python script resides.
Customer.csv file contains the Customer information
- Customer Name
- Customer id
- Date of birth
- Gender
- City
from pandas.io.parsers import read_csv
customer_csv_file = 'Customer.csv'
customer_dataframe = read_csv(customer_csv_file, delimiter=';')
print(customer_dataframe)
We can also read the CSV from 'import csv' module, but we will use pandas read_csv because it magically converts CSV into the DataFrame. 1st-row imports read_csv from pandas.
This CSV file has around 5147 rows, hence we are not printing the output here. But make sure you executes the program before proceeding.
Right now, we are printing all the elements of DataFrame on Screen, But what if we need to print a single element or index of a DataFrame.
For e.g., if we want to print the 6th row of the DataFrame, write print(customer_dataframe.iloc[6]), to the previous example.
It displays the 6th row on the screen.
But, print(customer_dataframe.iloc[6][0]) will display 0th Column index of 6th row i.e. 'bikad' in our case.
Operations and Manipulations on DataFrame
In this section, we will extend the previous example and learn few more manipulations on DataFrames.
from pandas.io.parsers import read_csv
customer_csv_file = 'DA_Customer.csv'
customer_dataframe = read_csv(customer_csv_file, delimiter=';')
# Print 6th Row
print(customer_dataframe.iloc[6])
# Print 6th Row and 0th Index of Column
print(customer_dataframe.iloc[6][0])
# Print Top 5 rows
print("\n Top 5 Rows are")
print(customer_dataframe.head(5))
# Print Last 5 Rows
print("\n Last 5 rows are")
print(customer_dataframe.tail(5))
Take a look head() and tail() functions. Head() displays the top 'n' results from the DataFrame whereas tail() displays bottom 'n' results of the DataFrame.
If you are already aware of UNIX, in that case, you are reasonably familiar with head and tail commands. Head() and tail() functions in Pandas are their analogy.
At present, we have carried out very elementary operations on DataFrames. Let’s move towards a grouping of Data.
Our CSV file contains Customer Name, Customer ID, Date of Birth, Gender, City.
We want to identify the customer base in each of the cities. It is remarkably meaningful to understand our customer demographics.
By regrouping the data according to City, then we know:
Which city has the highest Customer base?
Which city possesses the least number of Customers?
These outcomes are essential to identify because it provides insights to us on the number of Customers distributed across cities. Eventually, it points where we want to expand our market share.
Let’s include the code to our python script.
# Group the data by City
city_group = customer_dataframe.groupby('City')
count = 0
for city_name, group in city_group:
count = count + 1
print("City", count, city_name)
print(group)
We create an object and customer DataFrame is grouped (see groupby) according to the "City".
NOTE:- The city is one of the Columns in the CSV file.

Execute the program, the results are too big, hence only a portion of the output is copied here.
City 1 Bangalore
Customer Name Customer_ID DOB Gender City
3 rowap 419472292 1987-06-14 M Bangalore
32 zewov 493686428 1986-05-10 F Bangalore
48 sehob 174535964 1964-02-14 F Bangalore
75 xohiv 751472877 1997-12-03 F Bangalore
….
…..
[379 rows x 5 columns]
We have already covered a lot about DataFrames on Pandas. However still there is lot to cover. That's enough for Part-1.
Stay tuned for the Part-2 of the Tutorial.
Test Your Knowledge
- Find the shape of the DataFrame
- Find the length of the DataFrame

Top comments (0)