Let's start this blog by discussing a few scenarios and analyzing the search algorithms.
Scenario 1

This is the classic case of the use of Bloom Filter. For instance, you are creating a new username for Instagram and suddenly it flashes 'this username is already being taken up'. This happens in a fraction of a second. But give it a thought, how it can read millions of record in the database to search for the name in such a short time. The first thought pops up is using search algorithms. But the linear search is not efficient enough to pull the results from the database that fast. On the other hand, Binary search comes with a restriction that all the user records are stored alphabetically and also not accurate when dealing with words. So, Instagram must be using Bloom Filter to achieve this.
Scenario 2

Social media sites generate so much content each second and one of it's most awesome feature is of it is that we generally don't see the same content (posts, stories, etc.) again and again. This means these sites maintain a record of the content that is already viewed by the user.
Now let's wonder the ways they can achieve this. One is to store the content accessed by the user in the database and continuously query it to check if the content is visited by the user before. This is not both time and space-efficient since the application needs to maintain a huge amount of data per user and also iterate through it. To make the process more efficient, Bloom Filter is maintained for each user. Both Medium and Quora use this to solve the above problem.
We discussed the scenarios where we can overcome space and time complexities with the help Bloom Filters. Now let's understand what is Bloom Filter.
Explaining Bloom Filter
Bloom Filter is a probabilistic data structure. By probabilistic it means this data structure can the likelihood of an element in a set.
Bloom Filter generates False Positive results which mean it tells if an element is not in a set but isn't sure about if it in the set. It tells either "possibly in the set" or "definitely not in set". Let's demystify it a little bit.
Bloom Filter is a bit array of fixed length. The value of a bit either can be 1 or 0. This bit array is initialized with all bits set to 0. When an element needs to be added, it is passed through a no. of hash functions and the result of each hash function becomes indices of bit array which are then set to 1.
Let's say we have a bit array of length 10.

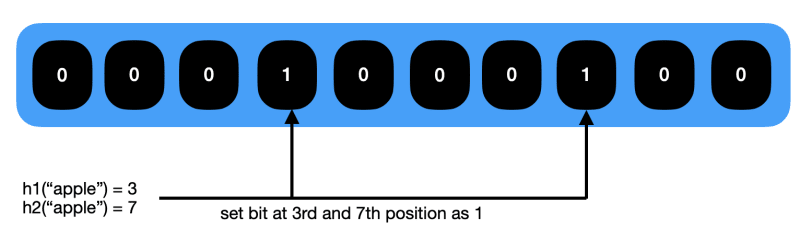
Let's say we are using 2 hash functions h1 and h2. We receive 2 strings "apple" and "orange".
Suppose,
h1("apple") % 10 = 3
h2("apple") % 10 = 7
So we will set 3rd and 7th index in array as 1.
For string "orange", suppose
h1("orange") % 10 = 2
h2("orange") % 10 = 9
Looking at the current array we can see 2nd and 9th are 0 means no orange string never received otherwise the bit at those index would be 1.

Let's take another example,
We receive "pear" string and suppose
h1("pear") % 10 = 2
h2("pear") % 10 = 5
So, hash function h1 for "orange" already set bit at index 2 as 1. But still since we also get index 5 which currently 0, it means we didn't ever receive or stored "pear" before.

Now if we get "apple" again,
h1("apple") % 10 = 2 and h2("apple") % 10 = 9, Since both of these index already set as 1, we do know it already exists in the set.
There might be a chance where we get a string even doesn't exist in the set or the storage have indexes received from hash functions as 1 in the bit array. We can certainly reduce the probability of the collisions by
- increasing no. of hash function
- increasing length of bit array
- both 1. and 2. This totally depends the frequency of data we receive for which we have to implement bloom filter. If we need to calculate the size of bit array or the size of bit array based on data we receive, we can do using following formulas
m = - (n lnP)/(ln2)^2
k = (m/n) * ln2
where m is size of bit array,
n is expected number of elements,
P is desired false positive probability,
k is no. of hash functions.





Top comments (2)
Bloom filters can also be used for specific equality checking indexes in databases or other hash-like storage (eg: caches). I had occasion to construct my own bloom filter once when I needed to ensure that a difficult and long-duration database replication had not missed any rows (~100M rows, replicated slowly over several months so as not to disrupt the source system - don't ask!), given the primary key values from both systems - perform a bloom filter operation between both sets and show that there are no 'definitely missing' keys :)
Thanks for sharing another scenario where Bloom filters can be used :)