In this blog, I’ll introduce you to the Databricks Lakehouse platform & discuss some of the problems that Lakehouse addresses. Databricks is a data and AI company. They provide the first Lakehouse which offers one simple platform to unify all your data analytics and AI workloads.

Challenges that most organizations have with data. Generally, start with the architecture. Note here as in below Fig2 have different isolated stocks for Data Warehousing, Data Engineering & streaming, and Data Science and Machine Learning. This needs to develop and maintain very different stocks of technologies can result in a lot of complications and confusion often times the underlying technologies don't work very well together and it's difficult to maintain this overall ecosystem.
Secondly, we have a lot of different tools that power each of these architectures and it ends up being just a huge slew of different open-source tools that you have to connect. In the Data Warehousing stack, you're often dealing with proprietary data formats and if you want to enable Advanced use cases, you have to move the data across the stacks. It ends up being expensive and resource-intensive to manage. All of this complexity ends up being felt by your data teams. Both people trying to query and analyze your data. As well as those responsible for maintaining these systems. Because the systems are siloed, the teams become siloed too, so communication slows down hindering Innovation and speed, and different teams often end up with different versions of the truth. So, we end up with many copies of data. No, consistent security or governance model closed systems and disconnected less productive teams.
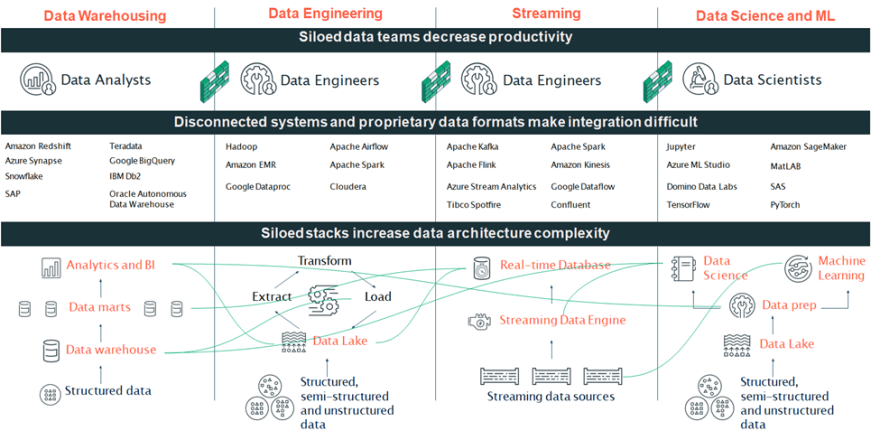
The core problem is the technologies in these stacks are built upon. The solution for this is a Data Lakehouse. Data Lake and Data Warehouses have complementary but different benefits that have acquired both to exist in most enterprise environments.

Data Lakes, do a great job supporting machine learning, they have open formats and a big ecosystem, but they have poor support for business intelligence and suffer from complex data Quality problems.
On the other hand, Data Warehouses are great for business intelligence applications, but they have limited support for machine learning workloads, and they are proprietary systems with only a SQL interface.
Unifying, these systems can be transformational and how we think about data. Therefore, Databrick’s culture of innovation and dedication to open source, bring Lakehouse to provide one platform to unify all of your data analytics and AI.
While it's an oversimplification, a good starting point to talking about the Lakehouse is to describe it as enabling design patterns and use cases associated with Data Warehouses to be stored in an open format and economical cloud object storage, as known as Data Lake
With proper planning and implementation, Lakehouse can provide organizations of any size with robust, secure & scalable systems that drastically lower total operating costs while increasing the simplicity of system maintenance and reducing the time to reach actionable insights.

At the heart of the Databricks Lakehouse is a Delta Lake format, Delta Lake provides the ability to build curated Data Lakes that add reliability and performance, and the governance you expect from Data Warehouses directly to your existing Data Lake. You gain reliability with acid transactions now; you can be sure that all operations in the data Lake either fully succeed or fail with the ability to easily time travel backward to understand every change made to your data. Additionally, the lake is underpinned by Apache spark and utilizes Advanced caching and indexing methods. This allows you to process and query data on your data Lake extremely quickly at scale. And finally, Databricks provide support for a fine-grained, access control list to give you much more control over who can access what data in your data Lake.
Now with this Foundation, let's look at the Lakehouse that's built on top of it. The Databricks Lakehouse. The platform is unique in three ways.

- It's simple data only needs to exist, once to support all of your data workloads on one common platform.
- It's based on open source and Open Standards to make it easy to work with existing tools and avoid proprietary formats and
- It's collaborative your Data Engineers, Analysts, and Data Scientists can work together much more easily.
Let's explore this a little more,

With a Lakehouse much more of your data can remain in your Data Lake rather than having to be copied into other systems. You no longer need separate data architectures, to support your workloads, across Analytics, Data Engineering & streaming, and Data Science, and Databricks provides the capabilities and workspaces to handle all of these workloads. This gives you one common way to get things done, across all of the major Cloud providers. The unification of the Lakehouse extends beyond the architecture and workloads as stated above.

Databricks invented some of the most successful open-source projects in the world. These Innovations underpin, everything we do, and they are born from our expertise in space. A commitment to open source is why we believe your data should always be in your control. Without the lake, there's no vendor lock-in on your data because it's built on open-source technology, the Databricks Lakehouse.
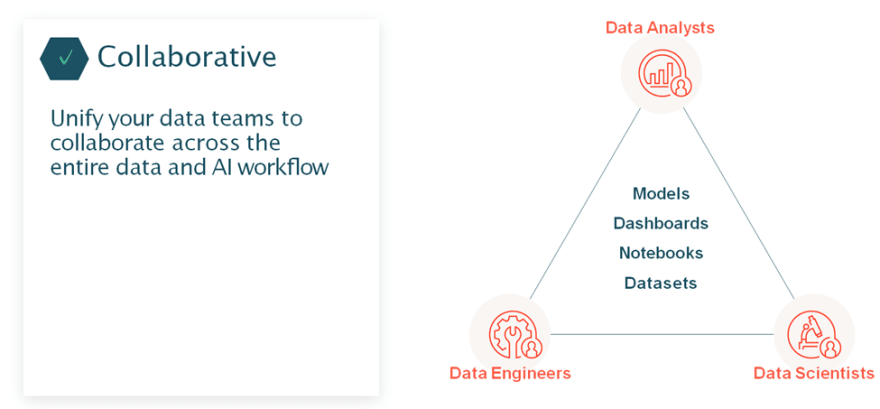
With Databricks and all your Data teams from Data Engineers to Data Analysts and Scientists can collaborate and share across all of your workloads. You can easily share data products, like models, Dashboards, Notebooks, and Datasets, and get more initiatives to production, so that you can be a data native organization.
I had read many of blogs related to Lakehouse but most of them include a lot of marketing stuff added in the blog. I tried to write too the point while explaining the core concept & feature that Lakehouse offers. Hope you like it. If you're curious how to pass the Databricks Lakehouse fundamentals Accreditation? Kindly follow the link ->
Databricks Lakehouse Exam Guide

Top comments (0)