
Since the beginning of computing, mathematicians and computer scientists were concerned about how to create programs or machines capable of learning in the same way as humans do, that is learning from interaction with our environment, which is a foundational idea underlying nearly all theories of learning and intelligence.
One compelling example of such learning in computer science is AlphaGo, the first computer program to defeat a professional human Go player and the first to defeat a Go world champion. The main technique used for creating and training AlphaGo is called Reinforcement Learning.
Reinforcement learning (RL) deals with the problem of how an autonomous agent situated in an environment perceives and acts upon it and can learn to select optimal actions to achieve its goals. Reinforcement learning is used in many practical problems, such as learning to control autonomous robots, learning to find the solution to an optimization problem (such as operations in factories), or learning to play board games. In all these problems, the agent has to learn how to choose optimal actions to achieve its goals, through the reinforcements received after the interaction with its environment. In a reinforcement learning task, the learner tries to perform actions in the environment. It receives rewards (or reinforcements) in the form of numerical values that represent an evaluation of how good the selected actions were. The learner (agent) simply has a given goal to achieve and it must learn how to achieve that goal by trial-and-error interactions with the environment. RL is learning how to map situations to actions to maximize the cumulative reward received when starting from some initial state and proceeding to a final state.
A general RL task is characterized by four components:
- The environment state space S represents all possible states of an agent in the environment. For example, every cell on a world is represented as a grid.
- The action space A consists of all actions that the learning agent can perform in the environment.
- The transition function δ specifies the non-deterministic behavior of the environment (i.e. the possibly random outcomes of taking each action in any state).
- The last component of the RL task is the reinforcement (reward) function which defines the possible reward of taking an action in a particular state.
So, to put it simply. the agent’s task in a reinforcement learning scenario is to learn an optimal policy, that maximizes the expected sum of the delayed rewards for all states in S.

One of the most widely used RL algorithms is the Q-learning algorithm.
In this scenario, the agent learns an action-value function (Q) giving the expected utility of taking a given action in a given state. In such a scenario, the agent does not need to have a model of its environment. For training the RL agent, a Q-learning approach is usually used, in which the agent learns the Q-value function that gives the expected utility of performing an action in a given state. The training process consists of the following: through several training episodes, the agent will try (possible optimal) candidate solution paths from the initial to a final state. After performing an action in its environment, the agent will receive rewards and will update the Q-values estimations according to Bellman’s equation where Q(s, a) denotes the estimation of the Q-value associated to the state s and action a, α represents the learning rate and γ is the discount factor for future rewards. Of course, RL problems can get very complicated when having a lot of states and actions to choose from, in that case, Q-learning is far from enough to solve the problem.
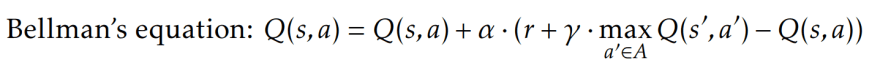
Summing up, this post aims to provide a brief introduction to the field of Reinforcement Learning, pointing out the general framework for solving RL tasks. This is a very exciting field of Machine Learning because it’s the closest we can get to human behavior at the moment.
At AI Flow, we handle the complicated math stuff, so you can create more intelligent products. Subscribe and get one month free when we launch the beta, at aiflow.ltd. Also don’t forget to check our Product Hunt campaign.




Top comments (0)