
In recent times, the serverless computing model has become an architectural approach increasingly popular. It enables faster development of modern applications, analytics and backend solutions.
Why use serverless implementation ?
It helps developers to focus on code rather than spending time in the configuration, managing, or scaling of backend infrastructure.
Serverless allows you to build and run applications without giving a thought about the server. The provisioning, administration, and scaling of the application server are all managed dynamically by the cloud provider.
Moreover, using serverless services allows to reduce drastically the bill.
An overview of some AWS serverless service

In this post, I would like to share with you how to use a full serverless architecture to meet an analytics use case.
As a big fan of AWS, I had to do this post using the technologies offered by this cloud provider but you will surely find the equivalents on GCP/AZURE 😇
Everyone knows how complex it is to configure and set up a KAFKA cluster. AWS already offered a service called MSK, but since April 2, 2022, it has offered a version of this service in serverless mode. According to AWS
it is the ideal solution to launch a project on Kafka when you are not able to predict the volume of data produced.
For this post I decided to implement this simple and effective solution :

This implementation will be split in 3 steps :
- Getting started with the serverless MSK service
- Setting up the producer
- Setting up the consumer within a Lambda Function
Let's go 🥷
Step 1 : Getting started with MSK service
It's easy to deploy a Serverless MSK instance, it's just a matter of checking the serverless box and providing a network configuration

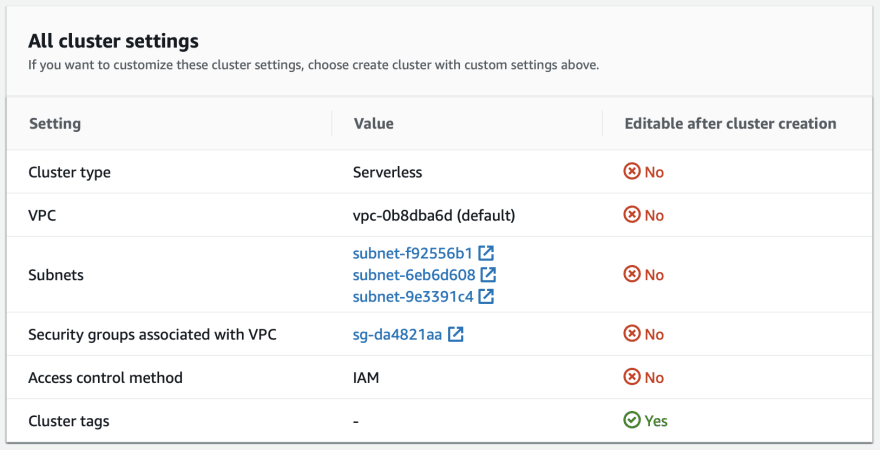
Once the serverless is active, you will found the bootstrap servers endpoint :


Keep this property near we will use it in the producer or consumer.
Note that the serverless version supports only AWS IAM for client authentication and authorization.
The default configuration applied on a serverless cluster here.
⚠️ The network configuration is not editable once the instance is deployed. AWS MSK must be deployed on secured VPC and can’t be exposed publicly.
Step 2 : Setting up the producer
To simulate a KAFKA producer, we will use an EC2 instance.
It must be assigned an IAM role (using IAM policy below) and a network configuration allowing it to communicate with the MSK cluster. The instance must be in the same VPC as the KAFKA cluster.
Producer IAM Policy
Once the EC2 instance is ready, you will need to install java as well as the kafka tools to test the connection and create our topic.
## Java 11 installation
sudo yum -y install java-11
## KAFKA Tools installation
wget https://archive.apache.org/dist/kafka/2.8.1/kafka_2.12-2.8.1.tgz
tar -xzf kafka_2.12-2.8.1.tgz
cd kafka_2.12-2.8.1/bin
Let's create our topic
export BS=[BOOTSTRAP_SERVER_URL]
./kafka-topics.sh --bootstrap-server $BS --command-config client.properties --create --topic salesdata.topic.1 --partitions 2
Let’s produce data to our MSK topic by using the kafka-console-producer.
## Download the sample sales data JSONL File
wget https://raw.githubusercontent.com/ahmedkadeh31/websales-msk/master/data/sales-data.jsonl -P ~/data/
## Send data to the topic
./kafka-console-producer.sh --bootstrap-server $BS --producer.config client.properties --topic salesdata.topic.1 < ~/data/sales-data.jsonl
Let's check if our topic received the data :
Cloud watch metrics

Kafka consumer result
./kafka-console-consumer.sh --bootstrap-server $BS --consumer.config client.properties --topic salesdata.topic.1 --group test-group-1 --from-beginning
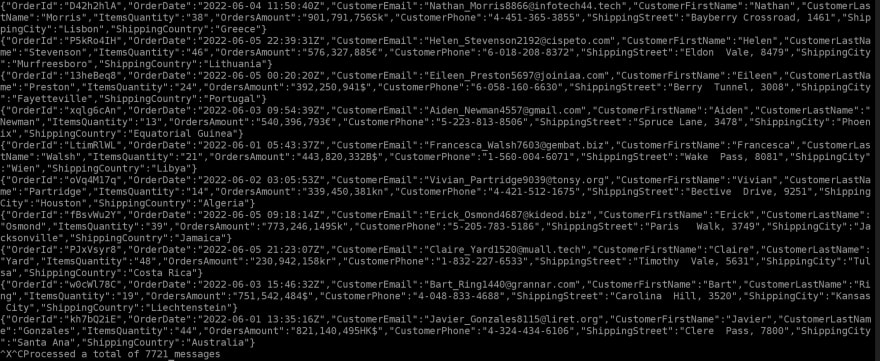
✅ Step 2 done!
Step 3 : Setting up the consumer Lambda Function
Now that our topic is fed, let's focus on our consumer.
When a message will be pushed in the topic, a trigger will invoke the lambda function.
And to be fully serverless, our function will write the data in DynamoDB.
The first action to do is to create an IAM role for the lambda.
The IAM role need the following policies :
- The policy created at the first step (for the producer)
- AWSLambdaMSKExecutionRole
- AmazonDynamoDBReadWriteAccess
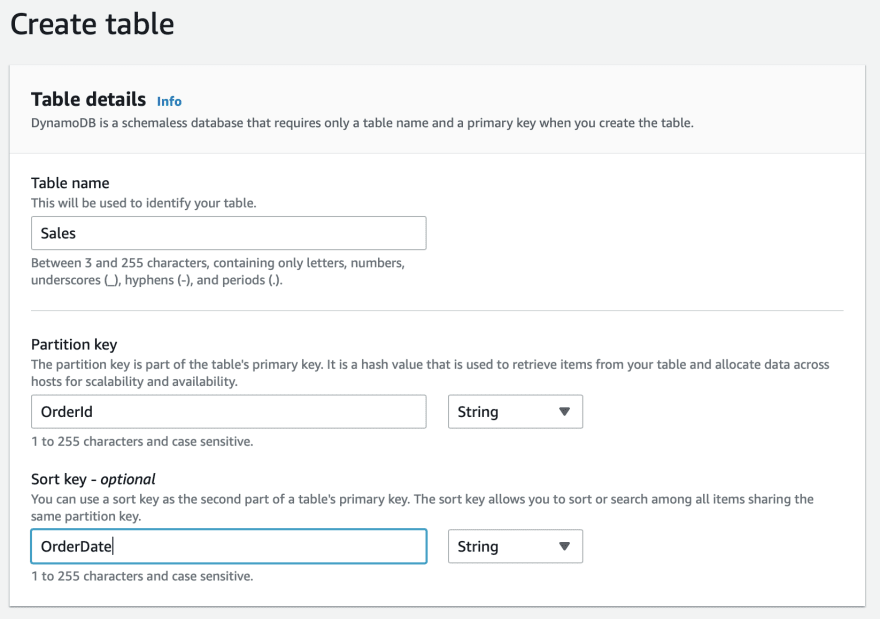
Next we create the DynamoDB table called 'Sales':
Now, let's code our lambda function ⚙️
Once our function is in place, we can test it by using an example event
Results
START RequestId: d1fd60fb-32ce-4bdb-bf16-590a8bf835c6 Version: $LATEST
[INFO] 2022-06-08T14:38:06.998Z Found credentials in environment variables.
[INFO] 2022-06-08T14:38:07.046Z d1fd60fb-32ce-4bdb-bf16-590a8bf835c6 Processing partition : mytopic-0
[INFO] 2022-06-08T14:38:07.046Z d1fd60fb-32ce-4bdb-bf16-590a8bf835c6 Sales data in message : {'OrderId': 'NT5a6j3D', 'OrderDate': '2022-06-05 14:30:48Z', 'CustomerEmail': 'Joseph_Moore9429@kideod.biz', 'CustomerFirstName': 'Joseph', 'CustomerLastName': 'Moore', 'ItemsQuantity': 23, 'OrdersAmount': '775,154,468Sk', 'CustomerPhone': '0-351-588-1823', 'ShippingStreet': 'Bush Road, 2355', 'ShippingCity': 'Otawa', 'ShippingCountry': 'Vanuatu'}
[INFO] 2022-06-08T14:38:07.046Z d1fd60fb-32ce-4bdb-bf16-590a8bf835c6 Saving data in DynamoDB table : Sales
END RequestId: d1fd60fb-32ce-4bdb-bf16-590a8bf835c6
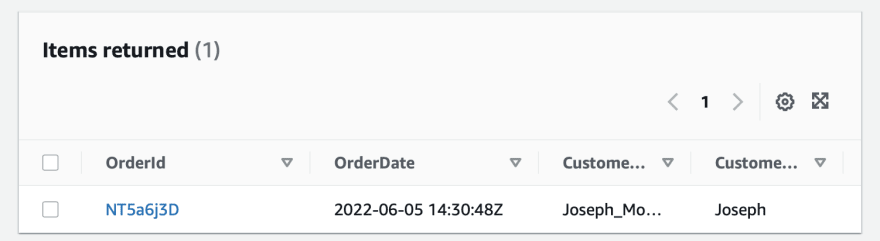
Great it works 🎉
The last step is to set up the MSK trigger in order to invoke the lambda function when a message is published.

Once configured, wait a few minutes and you can run the producer to send data.
To check that the function is working properly, take a look at the CloudWatch logs and the last processing result of the MSK trigger.

It was a good experience, this architecture is easy and quick to set up. By using MSK Serverless, there is no longer any need to spend hours configuring KAFKA, which saved us a lot of time.
But the use of MSK in Serverless mode has limitations, in particular on authentication and exposure to the public, which limits its use in production. However, I think it's interesting (and profitable) to use this service for small streaming applications, development environment or setting up a POOC.
Thanks for reading & hope that helps! 🤝
You can find the project ressources on my Github

Top comments (0)