
Amazon Web Services (AWS) offers a wide range of services to customers, with over 200 options available. While this diversity can make it easier for customers to find the right tool for a specific task, it can also make it challenging to understand how different services can be used together to achieve a particular outcome. In particular, customers may find it difficult to identify proven patterns for building data-driven applications using the various AWS services. Conducting multiple proof-of-concepts (POCs) to try and find a suitable pattern can be a time-consuming process and may not provide the level of confidence needed to implement a solution based on other customers' experiences. This guide aims to provide guidance through the process of developing data-driven applications on AWS by providing examples of proven patterns based on customer's successful implementation.
Modern data architecture
When building a modern data strategy, there are three main stages to consider:
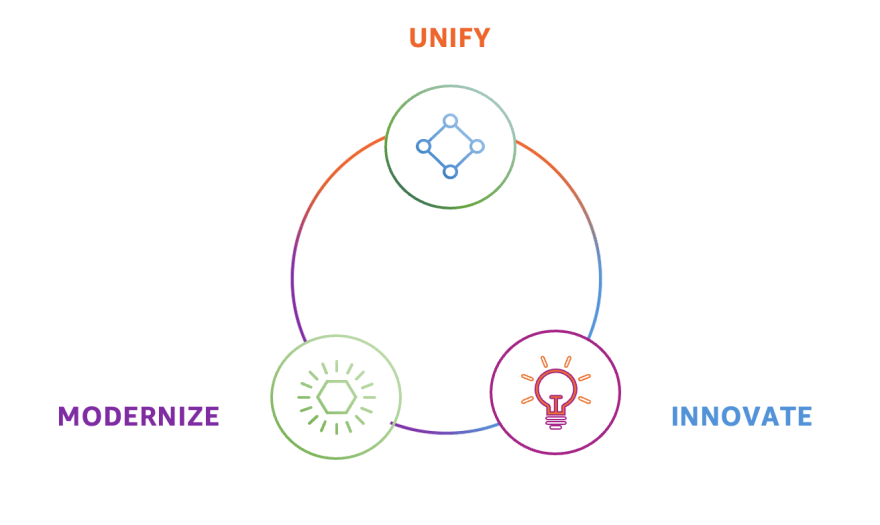
- Modernization: This stage involves updating your data infrastructure to take advantage of the scalability, security, and reliability offered by a cloud provider like AWS.
- Unification: This stage involves consolidating and integrating your data in data lakes and purpose-built data stores, such as Amazon S3, Amazon DynamoDB and Amazon Redshift. This allows you to easily access, process and analyze your data.
- Innovation: This stage involves leveraging artificial intelligence (AI) and machine learning (ML) to create new experiences, optimize business processes and gain insights from your data.
It is important to note that these stages do not have to be completed in a specific order, and it is possible to start at any stage, depending on your organization's data journey.
Modern data architecture on AWS
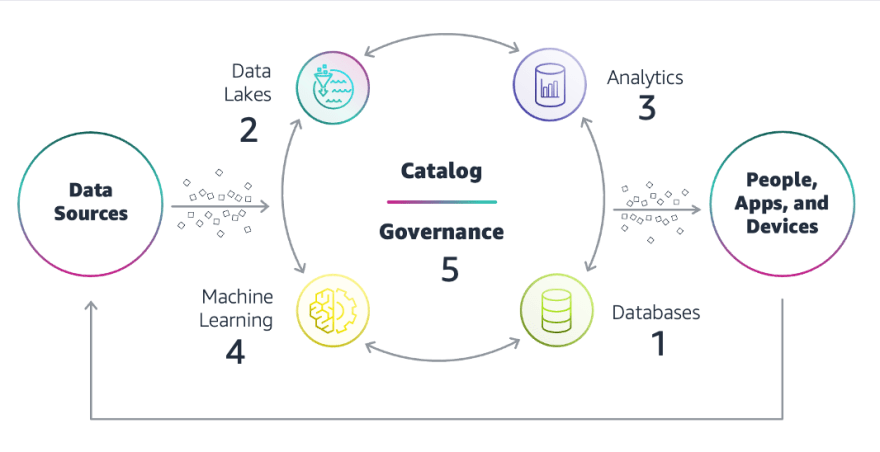
Choose the right type of database that works best for your modern application, it can be a traditional database or something new like NoSQL database. This will help your application work better.

Use a data lake, which is a big storage area for storing all kinds of data in a single place. This storage is often provided by Amazon S3. It will give you more freedom to use your data in different ways.
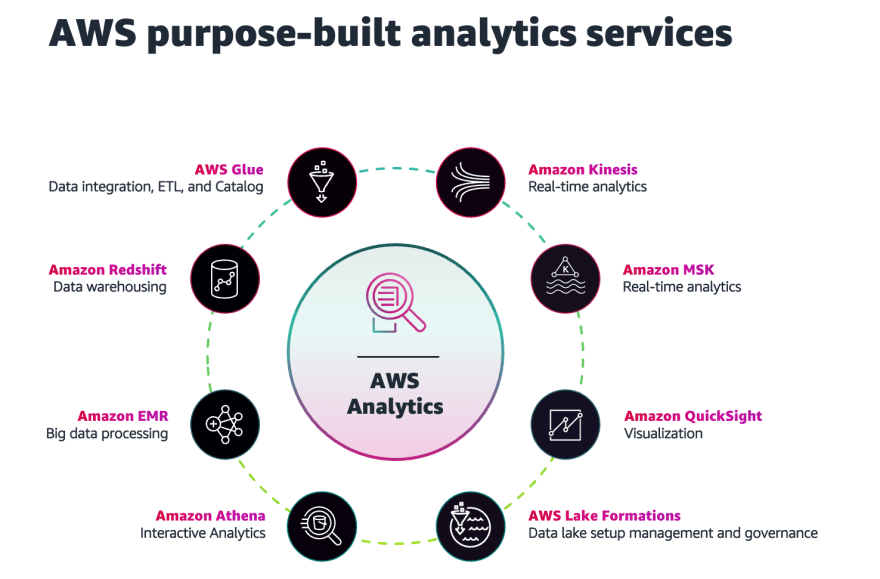
Build analytics on top of the data stored in the data lake, this can be used for things like getting reports, finding trends, and making predictions.
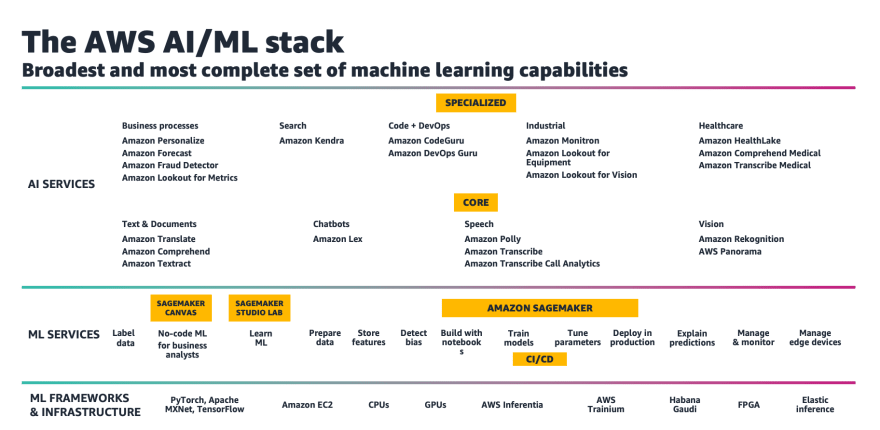
Use AI and Machine Learning to make predictions and make your systems and applications smarter. AWS has many different tools to help with this.
Make sure to properly manage and share your data, this includes making sure it's safe, making sure the right people have access to it and making sure it complies with regulations.
Data driven architectural patterns
the five most commonly seen architecture patterns on AWS, that cover several use cases for various different industries and customer sizes:
1. Customer 360 architecture
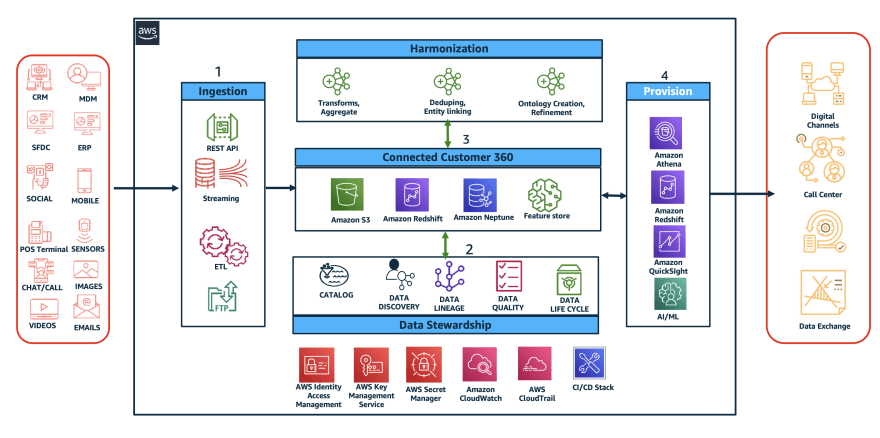
- Data Ingestion: This involves consolidating data from various sources and storing it in a scheme less manner. This data is ingested as close to the source system as possible, and includes historical data as well as data that is predicted to be useful in the future. This can be done using connectors such as SAP, and services like AppFlow, Google analytics and data movement service.
- Building a Unified Customer Profile: This step involves extracting and linking elements from each customer record to create a single, 360-degree dataset that serves as the source of truth for customer data. Amazon Neptune is used to create a near real-time, persistent, and precise view of the customer and their journey.
- Intelligence Layer: This step involves analyzing the data using analytical stores such as Amazon Redshift or S3 to refine the ontologies, and access raw information using AWS Glue DataBrew and Amazon Athena serverless.
- Activation Layer: This final step involves activating the refined customer ontology by using AI/ML to make recommendations, predictions and create next best action APIs using Amazon personalize and pinpoint. These actions are then integrated and presented across various channels for optimized personal experience.
2. Event-driven architecture with IOT data
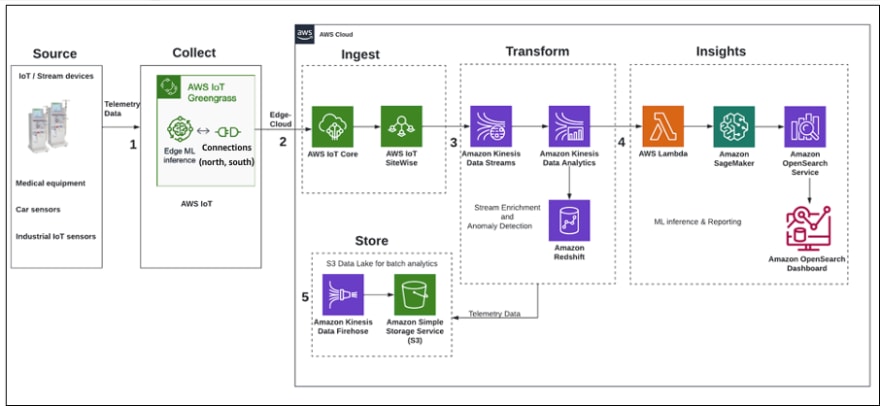
The architecture "Derive near real-time predictive analytics from IOT data" focuses on using IoT data to gain insights through predictive analytics. The process involves several steps including:
- Data collection from IoT devices such as medical devices, car sensors, industrial IOT sensors. This telemetry data is collected close to the devices using AWS IoT Greengrass which enables cloud capabilities to local devices.
- Data ingestion into the cloud using edge-to-cloud interface services such as AWS IoT Core, which is a managed cloud platform that allows connected devices to easily and securely interact with cloud applications, and AWS IoT SiteWise, which is a managed service that allows you to collect, model, analyze, and visualize data from industrial equipment at scale.
- Data transformation in near real-time using Amazon Kinesis Data Analytics, which offers an easy way to transform and analyze streaming data in near real-time with Apache Flink and Apache Beam frameworks. The stream data is often enriched using lookup data hosted in a data warehouse such as Amazon Redshift.
- Machine learning models are trained and deployed in Amazon SageMaker, the inferences are invoked in micro-batch using AWS Lambda. Inferenced data is sent to Amazon OpenSearch Service to create personalized monitoring dashboards.
- The data lake stores telemetry data for future batch analytics, this is done by micro-batch streaming the data into the S3 data lake using Amazon Kinesis Data Firehose, which is a fully managed service for delivering near real-time streaming data to destinations such as S3, Amazon Redshift, Amazon OpenSearch Service, Splunk, and any custom HTTP endpoints or owned by supported third-party service providers.
3. Personalized architecture recommendations
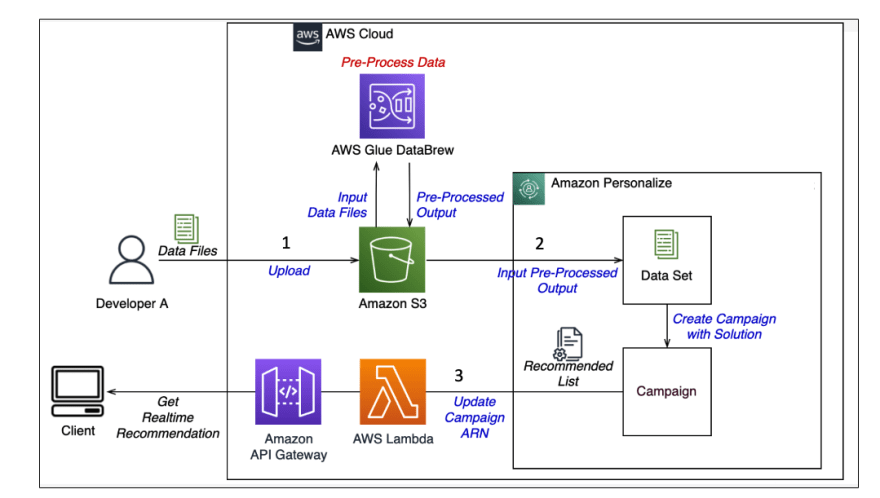
The architecture "Build real-time recommendations on AWS" focuses on using user interaction data to create personalized recommendations in real-time. The process involves several steps including:
- Data preparation: Collect user interaction data, such as item views and item clicks. Upload this data into Amazon S3 and perform data cleaning using AWS Glue DataBrew to train the model in Amazon Personalize for real-time recommendations.
- Train the model with Amazon Personalize: The data used for modeling on Amazon Personalize consists of three types: user activity or events, details about items in the catalog, and details about the users.
- Get real-time recommendations: After training the model, it can be used to provide recommendations to users through an API exposed through Amazon API Gateway. These recommendations are custom, private, and personalized. The process of creating these recommendations is simple and done by few clicks.
4. Near real-time customer engagement
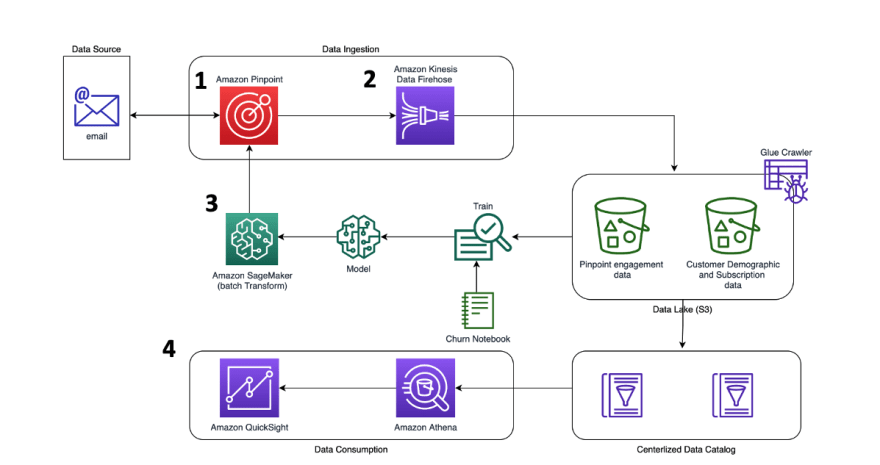
The architecture "Near real-time customer engagement architecture on AWS" focuses on using Amazon Pinpoint to collect customer engagement data and use it for creating insights through machine learning and data visualization. The process involves several steps:
- Initializing Pinpoint and creating a marketing project: Setting up the project to add users and their contact information, such as email addresses and configuring the metrics collection to capture customer interactions to Amazon S3.
- Near real-time data ingestion: Collecting data from Amazon Pinpoint in near real-time through Amazon Kinesis Data Firehose (optionally changed to Kinesis Data Stream for near real-time use cases), and storing it in S3.
- SageMaker model implementation: Training a model using a combination of Amazon Pinpoint engagement data and other customer demographic data, to predict the likelihood of customer churn or segmentation. This is done in an iterative manner and hosted in SageMaker endpoint.
- Data consumption with Athena and QuickSight: Analyzing the data from Amazon Pinpoint engagement and combining it with other data facts from data lake using Amazon Athena and visualizing it using Amazon QuickSight to share insights with others in the organization.
5. Data anomaly and fraud detection

The architecture "Fraud detection architecture on AWS" is a solution for fraud detection by training machine learning models on credit card transaction data and using it to predict fraud. The process involves several steps:
- Develop a fraud prediction machine learning model: A dataset of credit card transactions is deployed using AWS CloudFormation template and an Amazon SageMaker notebook is trained with different ML models.
- Perform fraud prediction: an AWS Lambda function processes transactions from the dataset, assigning anomaly and classification scores to incoming data points using SageMaker endpoints. An Amazon API Gateway REST API is used to initiate predictions. The processed transactions are loaded into an S3 bucket for storage using Amazon Kinesis Data Firehose.
- Analyze fraud transactions: Once the transactions are loaded in S3, different analytics tools and services such as visualization, reporting, ad-hoc queries can be used for further analysis.
In summary, when building data-driven applications on AWS, it's important to start by identifying key business requirements and user personas, and then use reference patterns to select the appropriate services for the use case. This includes using purpose-built services for data ingestion, such as Amazon Kinesis for real-time data and AWS Database Migration Service for batch data, and using tools like AWS DataSync and Amazon AppFlow to move data from file shares and SaaS applications to the storage layer. Data should be treated as an organizational asset and made available to the entire organization to drive actionable insights.





Top comments (0)