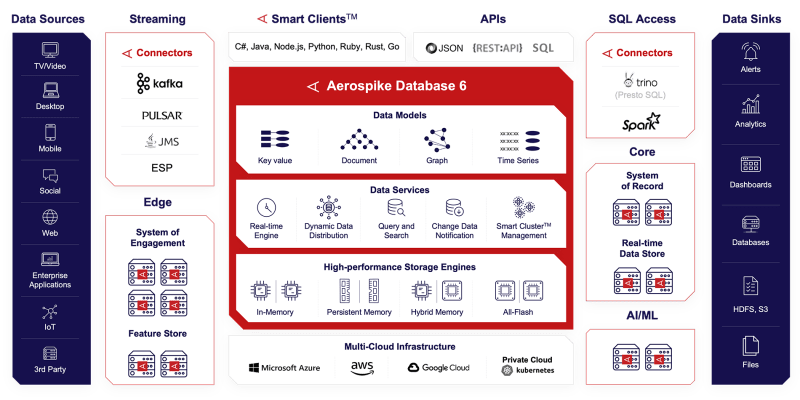
Aerospike Database 6: Partitioned Secondary Index Queries, Batch Anything, and JSON Document Models
Aerospike is proud to announce Aerospike Database 6, our newest database server release, now generally available (GA). This version of Aerospike is full of exciting developer features, which open up new capabilities for application developers to build on.
Launched two years ago, Aerospike Database 5 delivered a vastly improved Cross-Datacenter Replication (XDR) subsystem. It enabled our customers to create high-performance, geo-distributed applications with fine-grain control over the distribution of their data. Our newest database product release builds on these features and reflects our increased focus on queries. Combined with Aerospike Connect for Spark and Aerospike Connect for Presto (Trino), the Aerospike Data Platform enables our customers to serve both low latency transactional and analytical workloads against their large data sets.
We will cover three primary capabilities in this blog post. First, a discussion of the new query capabilities in our 6.0 release, and second, support for document data models through the Document API and our secondary index work, and finally our completion of batch operations, including batch writes, for greater efficiency through pipelined operations.
Server version 6.0. comes after seven release candidates, and is the culmination of 14 months of engineering effort. This is a major release, and includes breaking changes. Please review the release notes and the special upgrade instructions related to the new storage format and new secondary index query capability.
Partitioned Secondary Index Queries
The path to the new query subsystem started in the last two releases of Aerospike Database 5.
Server version 5.6 added set indexes, an optional index type that improves performance for a special kind of query. Using set indexes enables low latency access to all the records of a small set that lives inside a large namespace. Like the primary index, set indexes support fast restart.
Server version 5.7 delivered a 60% reduction in the memory consumed by secondary indexes, and a brand new, highly efficient garbage collection system. Query performance and throughput were also improved.
Aerospike Database 6 builds on these changes with a new architectural approach aligned with the design of the primary index. The data in each Aerospike namespace is evenly distributed across 4096 logical partitions, which in-turn are evenly distributed across the cluster nodes. The data for each partition is stored and indexed locally in multiple primary index sub-trees called sprigs. This enables primary index (PI) queries (formerly known as ‘scans’) to be massively parallelized.
A PI query can target all the partitions, a set of partitions, or a single data partition. Leveraging this capability, the Spark and Presto (Trino) connectors can split a PI query into hundreds and thousands of partitioned queries, feeding data to many thousands of workers in parallel, and attacking the job of rapidly processing terabytes of data through horizontal scaling. This approach fits well with the architecture of these analytics systems. The combination creates a next-level distributed computing data platform.
Before version 6.0, secondary index queries could only be parallelized at the node level. This meant that if a cluster had 40 nodes, the best parallelization the Spark and Presto (Trino) connectors could possibly use was 40 workers. As our customers make production use of Spark clusters with thousands of cores, having the huge majority of them sit idle was unacceptable, so these connectors did not implement support for secondary index queries.
In version 6.0, secondary indexes have been re-architected to separately index each partition. This enables massively parallelizing secondary index (SI) queries, as well as supporting pagination, similar to PI queries. Furthermore, SI queries in version 6.0 are tolerant of rebalancing, unaffected by the automatic data migration that occurs when the cluster size changes. As a result, the Spark and Presto (Trino) connectors will implement SI query support in the same way that they currently do PI queries. This opens the door for operators of Aerospike to optionally trade memory for performance improvements. By adding secondary indexes to sets that have the right cardinality, SI queries can run at orders of magnitude better speeds than equivalent PI queries.
The change in the secondary index architecture is reflected in the server’s query subsystem, which now unifies both types of queries - primary index and secondary index ones. This change goes deep into a common execution layer; into metrics, which have been merged and renamed; into the client API, which deprecates the Scan class, and provides the same rich functionality to both PI and SI queries from a single Query class.
Partitioned queries are achieved through client-server coordination, and require a new client version, such as Java client 6.0.0, C client 6.0.0, Go client 6.0.0, C# client 5.0.0 or Python client 7.0.0. Applications using the previous release of these clients may run against server 6.0, but will not benefit from the rebalance tolerance. Similarly, the new clients can talk to both server 5.x and server 6.0 nodes, but will need the cluster upgrade to be completed to unlock the new features.
Upcoming Query Features in Aerospike Database 6
Aerospike has delivered better query performance, a lower memory footprint for indexes, query stability, and higher query throughput. Subsequent releases of Aerospike Database 6 will add more functionality and operational improvements to queries.
In Aerospike Database Community Edition (CE), the primary index and secondary indexes are stored in process memory, which means that they must be rebuilt upon restart in a relatively lengthy cold restart. In Aerospike Database Enterprise Edition (EE), the primary index is kept in shared memory by default, or optionally in persistent memory or on a flash device. This enables an Aerospike EE server to go through a warm (fast) restart, which is significantly faster. Server version 6.1 will add the ability to store secondary indexes in shared memory, allowing warm restarts of the Aerospike daemon (asd) when they are present. Later versions will allow secondary indexes to be stored in persistent memory and even on flash devices.
Currently secondary indexes can be built over the top level keys of a Map data structure. This is typically employed to index the top-level fields of JSON documents, which are stored in Aerospike as Maps. Server version 6.1 will add the ability to index elements nested at any depth.
Storing, Indexing and Querying JSON Documents
Since the introduction of Map and List Collection Data Types (CDTs), developers have been storing JSON documents in key-ordered Maps, and using Aerospike as a document database. Developers use the rich Map and List APIs in multi-operation transactions to query and manipulate document data atomically on the server-side. Documents (Maps) are stored in a space-efficient MessagePack binary serialization, facilitating fast access.
The Aerospike Document API library (introduced mid 2021) added the ability to store, modify and query documents using the popular JSONPath query language. The Document API splits these queries into server-side execution based on the native Map API, and augmented by a JSONPath library.
The Document API is currently available as a wrapper to the Java client, and as an interface in the Aerospike gateway (also known as the REST client). The Document API library will be ported to other programming languages that have an Aerospike client.
Together with the upcoming capability to index deeply nested elements, Aerospike Database 6 enhances the development of applications that use a document model approach. Combined with features such as Strong Consistency and Aerospike’s ability to scale up to petabytes of data and hundreds of billions of objects, while maintaining sub-millisecond transaction latencies, results in a document database at scale.
Batch Anything
Since the beginning, the client has had support for a simple batch get command, to allow multiple records (or bins within them) to be retrieved together based on a list of keys. Similarly, a batch exists command checks on the existence of multiple keys all at once, from a specified list of keys.
Later the client added the ability to execute the same multi-operation transaction against a list of keys in parallel, using the batch operate command, but limited the type of operations in the transaction to read-only ones.
With server 6.0, the addition of batch write commands (put, delete, operate transactions without restrictions on write operations) completes the ability of a developer to batch anything in their application - reads, writes, updates, deletes or UDFs. Logically related operations can be sent all at once to the database cluster.
Batch writes are more efficient than asynchronously launching a series of commands at the server. Using batch:
- Reduces the round-trip time (RTT) needed to complete all the operations, lowering the overall latency
- Reduces network traffic, using less connections, and combining operations into fewer IP packets
- Improves parallelization, supporting faster data ingest
Developers of applications used in heavy writes or mixed workloads should consider converting from async writes to batch, for better performance and a more stable cluster.
Security Enhancements
Server 6.0 adds three new granular privileges for role-based access control.
- The
sindex-adminprivilege grants a user the ability to add and drop secondary indexes. - The
udf-adminprivilege grants a user the ability to add and remove UDF modules.
Previously these privileges were only available through the data-admin privilege, which some users were reluctant to grant widely.
The truncate privilege is now a standalone privilege, and no longer a part of the write privilege. Users representing applications that perform truncates should be granted the truncate privilege to one of their roles.
Breaking Changes
As mentioned earlier, make sure to read the release notes and the upgrade instructions. The breaking changes in server version 6.0 include
- A storage format change (the addition of a 4 byte end marker to each record) requires that persistent storage devices (with the exception of PMEM) be erased as part of the upgrade. The header (first 8MiB) of raw SSD devices must be zeroized. See SSD Initialization.
- Several configuration parameters have been renamed or removed:
- A small number of configuration parameters have been renamed.
-
scan-max-donetoquery-max-done -
scan-threads-limittoquery-threads-limit -
background-scan-max-rpstobackground-query-max-rps -
single-scan-threadstosingle-query-threads
-
- The following query configuration parameters were removed.
query-threadsquery-worker-threadsquery-microbenchmarkquery-batch-sizequery-in-transaction-threadquery-long-q-max-sizequery-priorityquery-priority-sleep-usquery-rec-count-boundquery-req-in-query-threadquery-short-q-max-sizequery-thresholdquery-untracked-time-ms
- The
batch-without-digestsconfiguration parameter was removed.
- A small number of configuration parameters have been renamed.
- The
truncateprivilege needs to be granted to applications using truncates. It is no longer part of thewriteprivilege. - The long deprecated Predicate Filtering (PredExp) was removed. Use Filter Expressions instead.
- The ‘scan’ module of the
jobs:info command has been removed. Use the ‘query’ module instead. - Be aware that scan and query related metrics have changed. We will publish a separate blog to detail these changes.
Deprecation Notice
- The
jobs:info command, initially deprecated in server 5.7 is scheduled to be removed after 6 more months. Usequery-showinstead. - The
scan-showinfo command is now deprecated. Usequery-showinstead. - The
scan-abortinfo command is now deprecated. Usequery-abortinstead. - The
scan-abort-allcommand is now deprecated. Usequery-abort-allinstead.
Learn more
Get details about Config, Metrics, and Info Changes in Aerospike Database 6.0

Top comments (0)