Introducción
Este artículo es el resultado de la ponencia presentada el día 28 de abril de 2023 en la Salmorejo Tech. Las slides de la presentación pueden encontrarse en el siguiente enlace: slideshare.
Con esta ponencia se buscaba explicar a una audiencia con conocimientos básicos de tecnología, las distintas herramientas que se pueden emplear para construir una plataforma de datos.
La ponencia comienza con una configuración sencilla, que prácticamente cualquier persona del mundo de la informática puede entender. Termina con una configuración compleja, donde sin entrar en muchos detalles, sí permite a la audiencia hacerse una idea de qué herramientas se requieren para implementar la solución.
Diferencia entre el mundo operacional y el mundo analítico.

El mundo operacional es donde encontramos las típicas aplicaciones de frontend y backend. En este mundo no es estrictamente necesario guardar históricos de información. Aquí estamos más interesados en guardar lo que el usuario necesite para realizar sus operaciones y estas operaciones pueden caducar con el paso del tiempo. Además, en el mundo operacional, guardamos grandes cantidades de información personal como pueden ser el email, teléfonos de contacto, direcciones, etc, etc. Esto es así porque los necesitamos para contactar con el usuario. Por ejemplo, para enviarle un pedido.
En el mundo analítico lo que se quiere es guardar tanta información como sea posible. En muchas ocasiones historificada. En este mundo también, no es estrictamente necesario guardar datos personales, por ejemplo el email. Aquí no necesitamos contactar con el usuario, y por tanto no necesitamos conocer su email real, pero sí que puede que estemos interesados en saber cuántos emails distintos se han utilizado en el sistema a lo largo de los años.
Es en este mundo analítico donde implementaremos nuestra plataforma de datos.
¿Qué es una plataforma de datos?
Una plataforma de datos es un conjunto de aplicaciones, herramientas, bases de datos que permiten la adquisición, el almacenamiento, preparación y gobierno de datos. Es una solución completa para el procesado, ingesta, analizado y presentación de datos generados por una empresa.
Ver links:
¿Quiénes son nuestros usuari@s?
Antes de seguir adelante implementando una solución tecnológica, tenemos que identificar los usari@s que utilizarán dicha solución, así como sus necesidades de negocio.
A continuación listamos los casos más típicos de usuarios que podemos encontrar para una plataforma de datos.
Data engineer.

Se enfoca en el diseño, construcción, mantenimiento y gestión de infraestructuras de datos.
Implementación y gestión de sistemas de almacenamiento de datos (bases de datos, almacenamientos en la nube, etc, etc)
Asegurar que los datos estén limpios, organizados y estructurados de manera adecuada para que puedan ser utilizados de manera efectiva.
Data analysts y data scientists y machine learning engineers.
Data scientist: utiliza técnicas estadísticas y de análisis de datos para extraer información útil con el objetivo de mejorar la toma de decisiones y la eficacia de una empresa.
Data analyst: recopila, procesa y analiza datos para ayudar a las empresas a tomar decisiones informadas. Su trabajo es proporcionar información relevante y accionable para impulsar el crecimiento y el éxito empresarial.
Machine learning engineer: desarrolla y optimiza modelos de aprendizaje automático para resolver problemas empresariales complejos. Su trabajo es construir sistemas que puedan aprender y mejorar a medida que se exponen a más datos.
Solución simple.
Ahora que ya sabemos quiénes son nuestros clientes podemos empezar a plantear soluciones. Como se anticipó en la introducción, iremos del modelo más simple al más complejo.
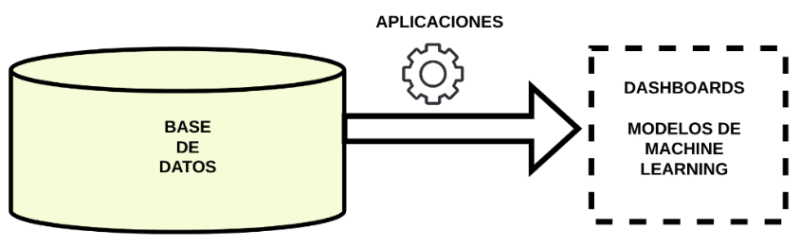
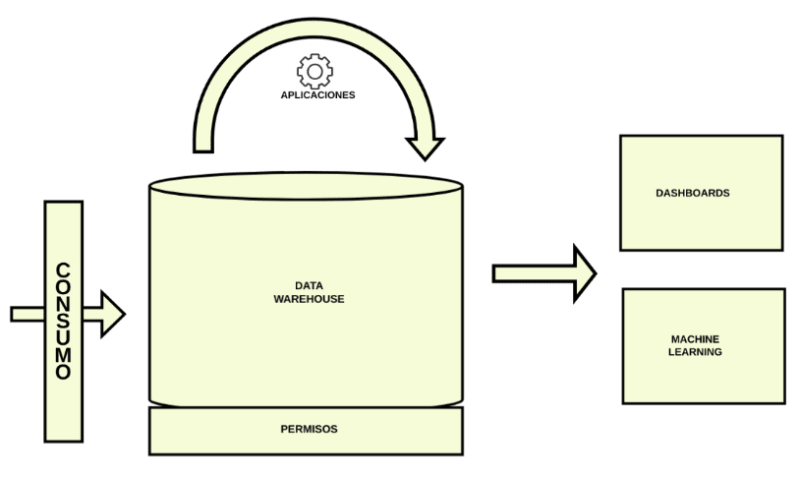
En esta solución, el mundo operacional y el mundo analítico comparten la misma base de datos.
Observamos que todos nuestros usuarios comparten el mismo sistema. La plataforma de datos utilizará como sistema de almacenamiento la misma base de datos que el resto del sistema operacional.
Para pequeñas y medianas empresas, esta puede ser una solución de compromiso, donde no se quiere añadir la complejidad que supone añadir sistemas de almacenamiento específicos para el mundo analítico.
La plataforma de datos no necesitará proveer de un sistema de almacenamiento especial.
Ventajas: sistema más simple de mantener.
Inconvenientes: acciones realizadas en el mundo analítico (por ejemplo sacar datos en un dashboard) pueden afectar a operaciones como pueden ser la compra de un producto desde el frontend porque el sistema de almacenamiento es compartido.
Herramientas que tendremos que proporcionar

Base de datos
- postgresql, mysql, oracle, etc, etc
- esquemas
- tablas
- gestión de permisos
Aplicaciones
- Leen tablas de la base de datos, realizan una transformación y escriben los resultados en otras tablas.
- ETL, extract, transform, load
Dashboards
- Diagramas donde se muestran datos de interés
Machine learning
- MLFlow
- Kubeflow
Ejemplo de aplicaciones que podemos usar
- Base de datos, por ejemplo PostgreSQL.
- Aplicaciones como Apache Airflow para el desarrollo de ETLs.
- Dashboards como Qlik y Tableau.
- Para machine learning por ejemplo podemos proporcionar Kubeflow.
Gobernanza
Gran importancia tendrá la definición y aplicación de reglas específicas para estandarizar nombres de las tablas, bases de datos, de procesos, etc, etc.
Además será importante crear reglas de utilización de las herramientas ofrecidas por la plataforma de datos. Recordemos que al final, detrás de la tecnología hay personas.
Debemos evitar que se haga un mal uso de dicha tecnología, para ello la gobernanza será fundamental.
Solución intermedia.
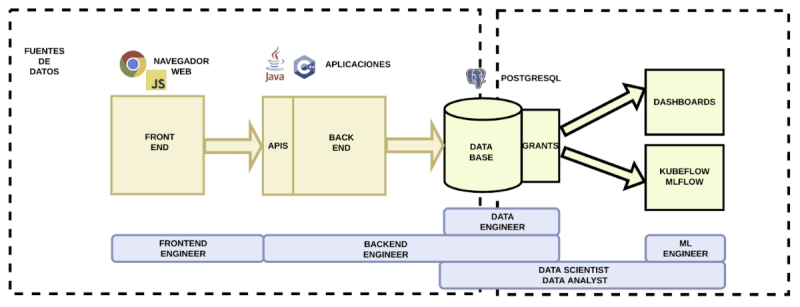
En esta solución observamos que el mundo operacional ahora es mucho más complejo.
Esta solución es necesaria cuando queremos evitar que procesos del mundo analítico afecten al mundo operacional. Además, el mundo operacional está compuesto por diferentes sistemas. Queremos tener todos nuestros datos analíticos en un único lugar para de este modo poder analizarlos y transformarlos de una manera sencilla.
La plataforma de datos necesitará proveer en este caso de una base de datos propia y de herramientas que permitan la extracción de la información almacenada en los diferentes sistemas del mundo analítico.
- Ventajas: acciones realizadas en el mundo analítico no afectan al operacional porque el sistema de almacenamiento no es compartido. Todos los datos analíticos están recogidos en un único lugar.
- Inconvenientes: mayor complejidad y costes.
Herramientas que tendremos que proporcionar
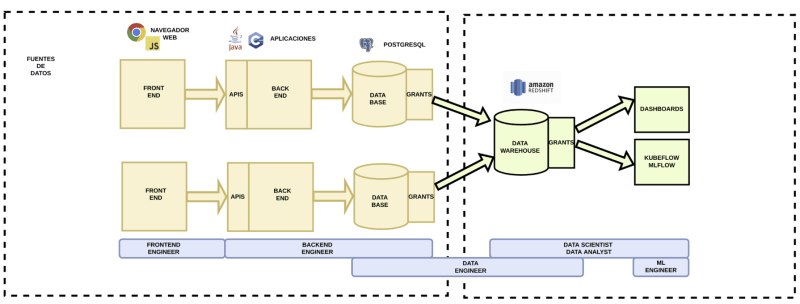
En esta solución las herramientas a proporcionar son las mismas que en la solución simple, pero ahora tenemos un nuevo tipo de base de datos, el Data Warehouse y aplicaciones que nos permitirán consumir información de los sistemas operacionales. El resto de las herramientas son las mismas que las que se explicaron en la anterior solución.
- Data Warehouse, por ejemplo, AWS Redshift.
- Aplicaciones como Apache Airflow para el desarrollo de ETLs.
- Dashboards como Qlik y Tableau.
- Para machine learning por ejemplo podemos proporcionar Kubeflow.
¿Qué es un Data Warehouse?
- Es una base de datos centralizada que integra muchas fuentes de datos.
- Permite aislar los sistemas operacionales de los analíticos.
- Queries lanzadas desde el sistema analítico no afectan al operacional.
- Permite reorganizar la información de forma que sea más fácilmente analizable.
- Proporciona un único modelo de datos.
- Permite mantener un histórico de información que el operacional, por no necesitarla, puede borrar.
- Permite integrar múltiples fuentes de datos en un único lugar.

- Modelado específico, esquema en estrella.
- Compuesto de tablas de hechos y de dimensiones.
- Tabla de hechos: sucesión de hechos, alto número de registros.
- Tabla de dimensiones: descripción de los hechos, pocos registros y muchos atributos.
- Permite la optimización de las queries en modo lectura.
- Permite queries más simples, sin necesidad de múltiples JOINs como podría suceder en un modelo normalizado de entidad-relación.
- Permisos vía GRANTs en tablas.
¿Qué es AWS Redshift?

Es una solución de Data Warehouse implementada por Amazon Web Services. Sin ningún esfuerzo, en la nube, podemos crear nuestro propio servidor.
En la captura de pantalla superior, se muestra la interfaz gráfica que permite crear y configurar AWS Redshift.
¡Cuidado! Nunca uses la interfaz gráfica para crear y mantener tu infraestructura en la nube. Usa siempre infraestructura como código. Con esto consigues que tu infraestructura sea reproducible, automatizable y fácilmente mantenible por cualquier persona en tu equipo u organización. Para ello hay diferentes soluciones como pueden ser CloudFormation, CDK, Terraform y muchas otras.
A continuación, documentamos un ejemplo de código Terraform que permite crear de forma sencilla un cluster AWS Redshift serverless.
1 resource "aws_redshiftserverless_workgroup" "serverless" {
2 workgroup_name = var.name
3 namespace_name = aws_redshiftserverless_namespace.serverless.id
4 base_capacity = var.base_capacity
5 security_group_ids = var.security_group_ids
6 subnet_ids = var.subnet_ids
7 enhanced_vpc_routing = true
8 publicly_accessible = var.publicly_accessible
9 tags = var.tags
10 }
11
12 resource "aws_redshiftserverless_namespace" "serverless" {
13 namespace_name = var.name
14 admin_username = var.admin_username
15 admin_user_password = var.admin_user_password
16 db_name = var.db_name
17 iam_roles = var.iam_roles
18 default_iam_role_arn = var.default_iam_role_arn
19 tags = var.tags
20
21 # https://github.com/hashicorp/terraform-provider-aws/issues/26624
22 lifecycle {
23 ignore_changes = [
24 iam_roles
25 ]
26 }
27 }
28
29 resource "aws_route53_record" "serverless" {
30 for_each = toset(var.route53_record_zone_ids)
31 zone_id = each.value
32 name = "redshift-${var.route53_record_name}"
33 type = "CNAME"
34 ttl = 30
35 records = aws_redshiftserverless_workgroup.serverless.endpoint.*.address
36 }
Solución avanzada.
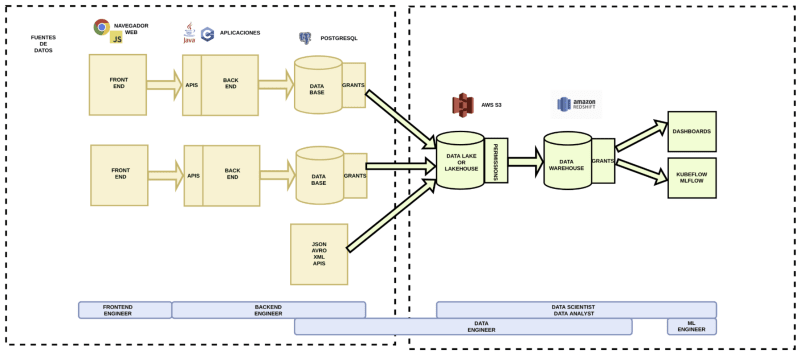
En esta solución aparecen dos nuevos elementos: el Data Lake o Lakehouse, y fuentes de datos de tipo JSON, AVRO, XML o cualquier tipo de API.
Esta solución la implementaremos cuando tengamos que guardar grandes cantidades de datos no estructurados como pueden ser eventos generados por el Internet de las Cosas.
- Ventajas: podemos guardar datos no estructurados en grandes cantidades.
- Inconvenientes: mayor complejidad y costes.
Herramientas que tendremos que proporcionar
En esta solución las herramientas a proporcionar son las mismas que en la solución intermedia, pero ahora se añade la necesidad de implementar un Data Lake o un Lakehouse.
En nuestro caso, y porque estamos usando las herramientas proporcionadas por AWS en la nube, el Lakehouse se implementará haciendo uso de AWS S3.
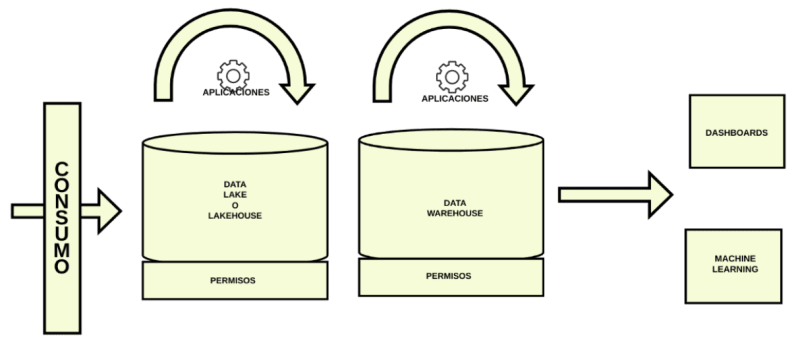
¿Qué es un Data Lake o Lakehouse?
- Es un sistema de almacenamiento de datos masivo y barato.
- Se utiliza para almacenar grandes cantidades de información en su formato nativo, sin necesidad de que los datos estén estructurados de una manera particular (JSON, XML, logs, etc)
- Los datos pueden provenir de diferentes fuentes, bases de datos, sensores, registros de máquinas, APIs, etc.
- Permite aislar los sistemas operacionales de los analíticos.
- Se utilizan sistemas distribuidos como AWS S3 de Amazon o HDFS (sistema de archivos de Hadoop)
¿Qué es un Data Lake o Lakehouse implementado en AWS S3?
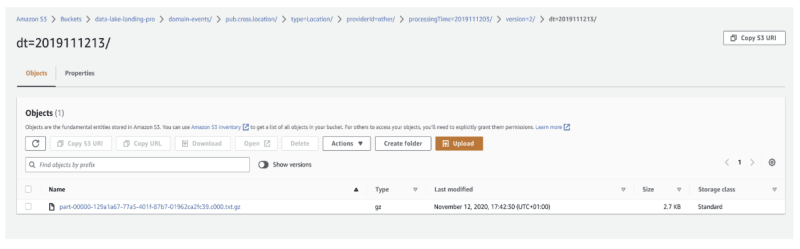
- En Adevinta, implementado en AWS S3 (en Amazon Cloud)
- Puede verse como un sistema de archivos con carpetas
- ¡Pero no es un sistema de archivos!
- Los archivos se llaman objetos.
- Podemos usarlo mediante el Hadoop File System, Apache Spark, etc, etc.
- Permisos vía IAM Roles.
¿Cómo podemos usar el Data Lake o Lakehouse?
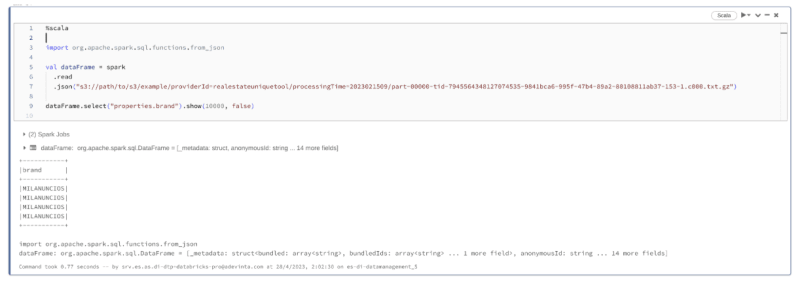
Para poder usarlo existen aplicaciones como Apache Spark. En la captura de pantalla superior, se muestra un notebook ejecutando código Apache Spark que permite leer un archivo comprimido en formato gzip y mostrar la información que contiene.
Conclusión.
En esta ponencia hemos presentado diferentes soluciones para construir una plataforma de datos. Desde la más sencilla hasta la más compleja. Otras soluciones son posibles, pero todas ellas tendrán piezas muy similares a las aquí discutidas.
Ahora ya solo queda que tú también montes en tu empresa tu propia data platform y logres ese ascenso o mejora laboral que te mereces.

Top comments (0)