
Queueing in multi-tenant SaaS systems is often introduced to improve the overall platform stability, improve the user experience and scale the system. When you browse the internet or ask some developers, it will often be mentioned as an easy-to-implement solution. Well, it is not always that way, and there are sometimes some pitfalls that you can encounter while doing this step.
What multi-tenancy and single-tenancy actually mean
Let's first discuss some basics, so we have a common understanding of:
- SaaS (Software as a Service) — this is probably self-explanatory as selling software in this form is pretty common now. But quoting Wikipedia:
- SaaS is a software licensing and delivery model in which software is licensed on a subscription basis and is centrally hosted. SaaS is also known as on-demand software, web-based software, or web-hosted software
- Multi-tenant — this means that the SaaS software you offer is serving multiple tenants/multiple customers using one instance. It does not matter if your instance is a server, multiple servers or serverless, the important thing is you have a shared infrastructure. Most SaaS companies are running using this model as it is way easier to manage and lowers the overall maintenance costs. In fact, only very specialized services, with high charges make sense not to be multi-tenant.
- Single-tenant — opposite to multi-tenant. This means that in order to onboard a new customer, your tech team needs to set up a new instance of the app. Each tenant can also have a different version of the app (although maintaining too many differences often gets too expensive and hard to manage). This means, that in a single-tenancy system, each new customer runs a separate software instance. Each tenant can have multiple users that share the same instance.
Single-tenant vs multi-tenant SaaS architecture
The decision between multi-tenancy and single-tenant architecture is out of the scope of this article, but the basic rule of thumb is to choose what is important for you — the ease of management of multiple customers — probably hundreds and thousands, of being able to adjust every single tenant by adding custom code changes. Another decision driver for a single-tenant architecture would be a requirement of separate computing resources, data isolation, data security, and some specific legal requirements. In general, something we could summarize as tenant isolation.
What is the problem with queueing in multi-tenant systems?
Let us imagine a system where we have a long-running process that the clients execute. It can be anything — from processing a file (import a CSV, video format conversion), or anything else that makes sense — like crawling a page etc.
Now in such systems, it could happen, that one customer executes so many tasks that are queued, that his "tasks" pile up and form a long waiting queue to be handled.
If Client 1 executes 1000 such tasks, all other customers (2, 3 etc.) will have to wait until this one gets his 1000 tasks done. This happens because queues are by default FIFO — first in, first out.

In this case, Client 2 will wait for ages to get his one task done, will get quickly angry and can potentially cancel the subscription. Why would he wait an hour or two to get one simple conversion finished?
So we have one customer affecting the user experience of many customers, by consuming all the computing resources available.
What is fair processing in multi-tenant architecture
Before we jump into a bit more technical discussions let's quickly consider what we think is fair.
The quick answer is that one client causing a big load, should not cause harm to other clients. So we should process Client 2 and Client 3 from the image, and then continue with Client 1 tasks.
But to be honest, in lots of SaaS, we have different tiers of clients. Not all clients are equal. A client that has the lowest tier should probably have a bit less priority than a client on an enterprise Tier. This could mean, that f.e. our business decision is to handle clients in the top Tier four times faster than in the lowest one. This does not mean we process all tasks of the top tier first, we just process them a bit faster if the queue is full.
This might be considered unfair, but I would like to have my target multi-tenant architecture handle such cases.
Multi-tenant SaaS architecture — things to consider
In order to properly implement a multi-tenant architecture we need to consider the following related problems:
Single-tenant vs multi-tenant — data isolation
When you switch from a single-tenant to a multi-tenant approach you need to consider how you partition your data. Your application now stores data from multiple tenants/multiple customers in a single software instance, but the tenant's data should not be shared between them!
In short, the three multi-tenancy models for data storage are:
- Silo - when each tenant has a separate instance of the storage, f.e. a separate database server.
- Bridge - when each client data is stored on the same database server, but has a separate schema to store data.
- Pool - when all clients share the same database (including schema), but the tables have columns to inform which tenant data it represents.
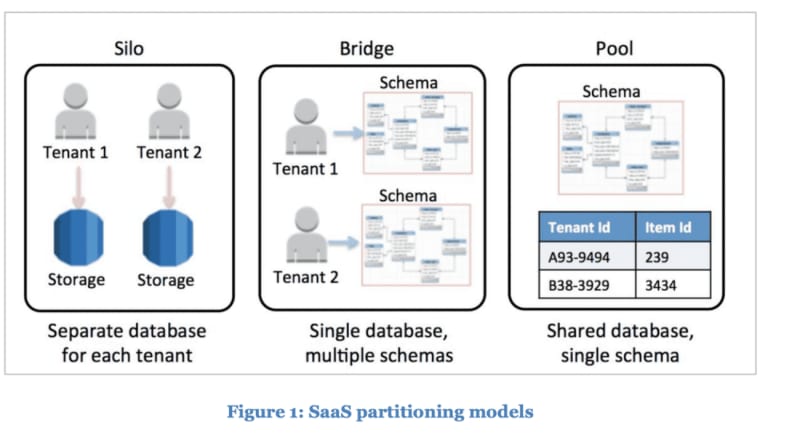
As you can see, the Silo approach is quite close to running a single-tenant architecture. In fact, for the db storage you need to create a single instance for each new customer. This can be automated and is a bit easier to manage than running a separate instance of the software per customer, but it still requires quite a lot of work and raises the maintenance costs. When you need to go the Silo way, it's good to consult with cloud service providers — they usually have articles explaining how to implement dedicated instances for storage using their cloud services.
This is quite an interesting discussion to have when planning your multi-tenant architecture. You can read more about it f.e. in this Amazon whitepaper
Noisy neighbour
Because multi-tenant SaaS software clients share the same hardware resources, it can happen that the activity of one of the tenants will have a negative impact on other tenants. I already touched the queueing part of it, but the same issue applies to other resources. F.e. a client executing many heavy actions that are not queued can cause a partial system outage that also hits other users. In this case, even when a user is not causing a big load on the system, he will encounter slow response times, errors etc. It happens not only when all tenants use a single database instance, but even if they only use the same software instance, as the CPU resources are shared.
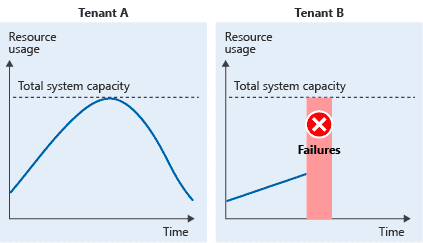

Figure with 3 tenants, each consuming less the maximum throughput of the solution. In total, the three tenants consume the complete system resources.
You can read more about it in this Microsoft Documentation.
How to fix multi-tenant queueing?
While researching the web I found a couple of different solutions, let us quickly go through them and discuss the pros and cons.
1. Add more workers
This can definitely be considered as a first aid if the problem hits you. If you have a lot of consumers there might be a need for faster processing = lower waiting times. But let us be honest — this won't solve the problem. One client can still block the processing for others, and there is usually a limit of consumers that you can execute. Next to that, if the processing is using some external systems/APIs, you can easily hit the rate limits.
It is worth mentioning, that even when you use cloud computing with virtual machines that you can scale easily, there is usually a hard limit enforced by the cloud platform you use.
2. Request throttling
Did I just mention an external system could have a rate limit? Yup. When we hear rate limits, we usually tend to think about APIs. But we could introduce something similar in our app. Not always, but in some business flows, you can show an alert to the user, that he added too many tasks, and because of that — needs to wait a bit, or... just upgrade to a higher tier ;)
This does not solve the queue issue itself but could help limit the problem of a noisy tenant. You can set limits for tasks added within a minute, hour, day etc. Not perfect, but I think it's worth considering.
2.1 Request throttling with priority
Priority — connected with the tier the tenant is on, can be actually added to many of the described solutions. If you connect tenant priority with a rate limit, it can lead to some interesting results. Most queues support the priority of a message, and that will allow to process enterprise customers a bit faster.
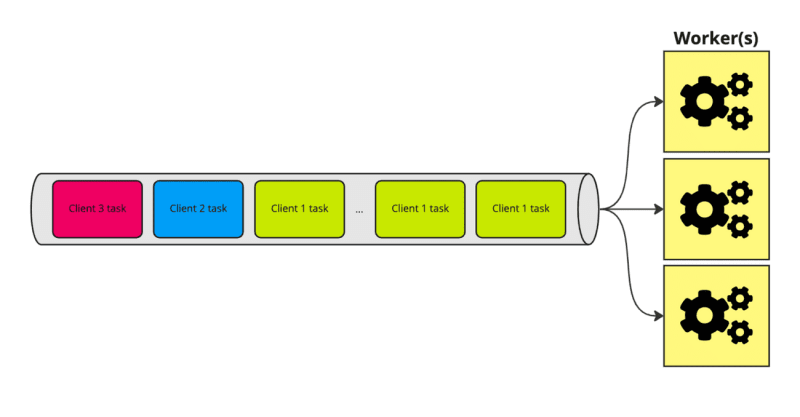
3. Sharding
In this case, you can just split the tasks into multiple queues (each queue can serve multiple tenants). A simple solution could be based on the client number, like this:

In the example, I split the clients into 3 different queues. In this case, when Client 1 starts to process too many tasks, it will "only" affect 33,(3)% of the other tenants. Does not fix the problem, but definitely makes it a bit less painful (at least for some users).
3.1 Sharding, but better
This is something I did not see in any articles, but I've learned from one of our projects. You can actually come up with better ideas for sharding, than the client id.
As an example, we could have a default queue for processing tasks, but we can also add a queue for our "enterprise" tenants. Next to that, we can come up with queues for tenants that are known for high load and just process them next to the default queue.
In the project I worked for, there was a special "spike" queue, that was activated by a rate-limiting mechanism. If the system detected that a tenant was queueing too many tasks, he was moved to a "spike" queue.

4. Multiple instances - per tenant queue
Easy, elegant, powerful and not always possible. Just create an automation (using Cloudformation or Terraform), that sets up a queue for each new tenant. You can consider this to be the Silo approach described in the partitioning SaaS part above.
This is probably the perfect solution if you do not have too many tenants, and there won't be too many new each month/day.
In our case, we had thousands of tenants register every week, so a per-tenant queue was not an option. It would be a nightmare to manage, but also we would hit the limit of SQS queues within one week.
4.1 Processing this amount of queues
Another question is how to handle that many queues. Well, there are at least two options:
If the customers pay enough, you could run a consumer for each of them. Not perfect, but I think it would fit the Silo approach quite well.
You could implement a
slimconsumer that iterates through all the queues, and fetches max one new task from each tenant queue, then forwards the task to one shared queue. The "output" queue is then connected to your consumers - shared across all tenants. This approach is described by Simone Carriero in his article.

5. Switch what is queued
This is our case, and before I describe it I would like to underline, that it fits our needs, and might be considered a bit controversial. Yet, it has worked perfectly for over two years now ;)
A bit of background on what we had to handle:
- We have quite a lot of new tenants every week;
- Each new tenant starts by importing data from an external system;
- An import might be just a few elements, but might also be thousands of them;
- Data is imported from an external system that has rate limits — both for us and each of our tenants;
- So when we hit the rate limit for Tenant A, we can usually still process Tenant B.
A "Default" approach to this would be to queue each element, as each of them needs to be fetched from the external API, and then processed.
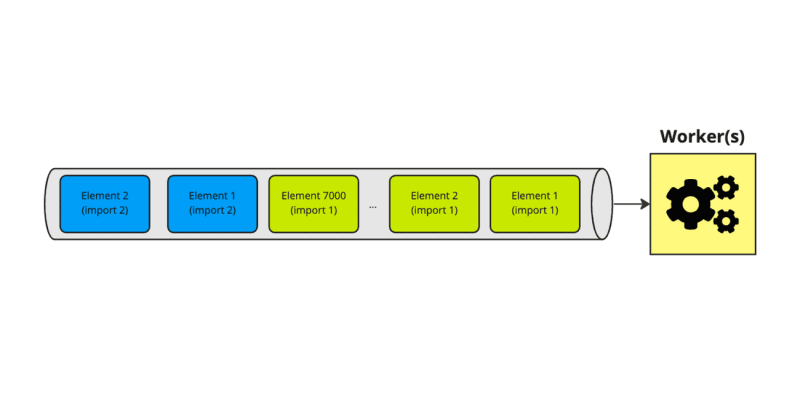
This is obviously a terrible idea, as one import of 10000 elements will be processed for ~1 hour (due to rate limits), and tenants that import 10 elements will have to wait, although they could be served within 3 seconds.
So we decided to rethink what exactly we queue, and instead of queueing a certain element, we just queue the fact that tenant X import needs to be processed:
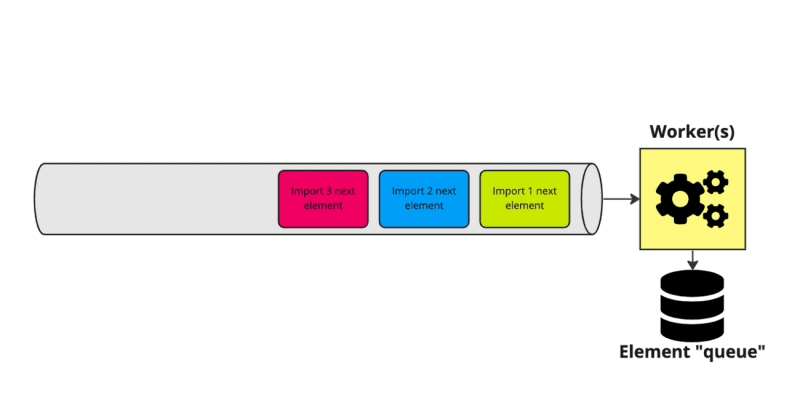
Next to that, we maintain a separate list of elements to be imported into the database.
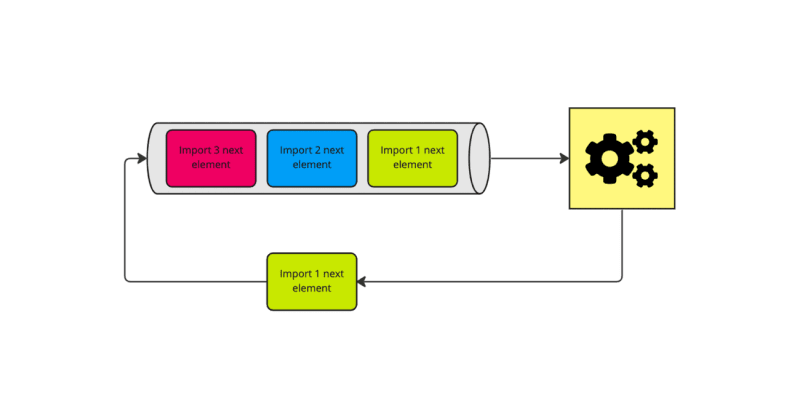
A consumer receives a task to process import no. 1, fetches the next element for it, and after it finishes, it reschedules the task to the queue:
Rate limit adjustments
As mentioned, the system we are connected to has a rate limit enforcement both on our app, but also on the tenant level. Our app rate limits are quite big, and in 99% of cases, we hit the tenant limit. So it makes sense to slow down importing one tenant, in order to process others.
In the case of our solution, that was pretty easy to implement. First, we had to fetch the rate limit information from the external service. That actually already there in each response header. We have exact info on how many requests are left in a specified timeframe.
Based on that, we can calculate a delay — the closer we get to the limit, the bigger the delay gets. As the delay grows, the rate limit "recovers", and we can lower the delay.
Next, we pass the delay to the queueing solution:

Now the queue handles the delay and provides us only with tasks that we can run without hitting the limits.
Handling different tiers
As mentioned in the introduction, in most SaaS solutions there are different tiers of users, and we might need to process some users faster. Like a big enterprise account etc.
In our system, each tier has an assigned "multiplier" that tells us how many import tasks we should schedule for the import task. Based on that, we can manage the pace/velocity at which we import the data:

What is the perfect solution for your SaaS?
There is no one-size-fits-all solution for multi-tenancy queueing, and I doubt our approach will be the best one for all of you. I just wanted to light a spark, and make you think about a couple of things:
- Although we (developers) tend to say queueing is easy, it is not. It is easy to implement, but it comes with quite a lot of problems you can hit, fair processing and data partitioning are two of them.
- You might read about some battle-proven solutions described by well-known companies, but I think it is still beneficial to sit down and re-think the approach for your multi-tenant app. You might come up with something similar to what we did, that works a lot better in your case.
Multi-tenancy in SaaS is usually not easy, but to be honest I think in 95% of cases it is worth investing the time, as it makes maintenance costs way lower. So unless you are in an MVP phase, you should make the investment.
If you have any other ideas for solving queueing in multi-tenant architecture — let me know!

Top comments (1)
Nice!